WP12321 Add FMCSSTAT channels to EDC
Erik, Dave:
Recently FMCS-STAT was expanded to monitor FCES, EX and EY temperatures. These additional channels were added to the H1EPICS_FMCSSTAT.ini file. DAQ and EDC restart was required
WP12339 TW1 raw minute trend file offload
Dave:
The copy of the last 6 months of raw minute trends from the almost full SSD-RAID on h1daqtw1 was started. h1daqnds1 was temporarily reconfigured to serve these data from their temporary location while the copy proceeds.
A restart of h1daqnds1 daqd was needed, this was done when the DAQ was restarted for EDC changes.
WP12333 New digivideo server and network switch, move 4 cameras to new server
Jonathan, Patrick, Fil, Dave:
A new Cisco POE network switch, called sw-lvea-aux1, was installed in the CER below the current sw-lvea-aux. This is a dual powered switch, both power supplies are DC powered. Note, sw-lvea-aux has one DC and one AC power supply, this has been left unchanged for now.
Two multimode fiber pairs were used to connect sw-lvea-aux1 back to the core switch in the MSR.
For testing, four relatively unused cameras were moved from h1digivideo1 to the server h1digivideo4. These are MC1 (h1cam11), MC3 (h1cam12), PRM (h1cam13) and PR3 (h1cam14).
The new server IOC is missing two EPICS channels compared with the old IOC, _XY and _AUTO. To green up the EDC due to these missing channels a dummy IOC is being ran (see alog).
The MC1, MC3, PRM and PR3 camera images on the control room FOM (nuc26) started showing compression issues, mainly several seconds of smeared green/magenta horizontal stripes every few minutes. This was tracked to maximizing CPU resources, and has been temporaily fixed by stopping one of these camera viewers.
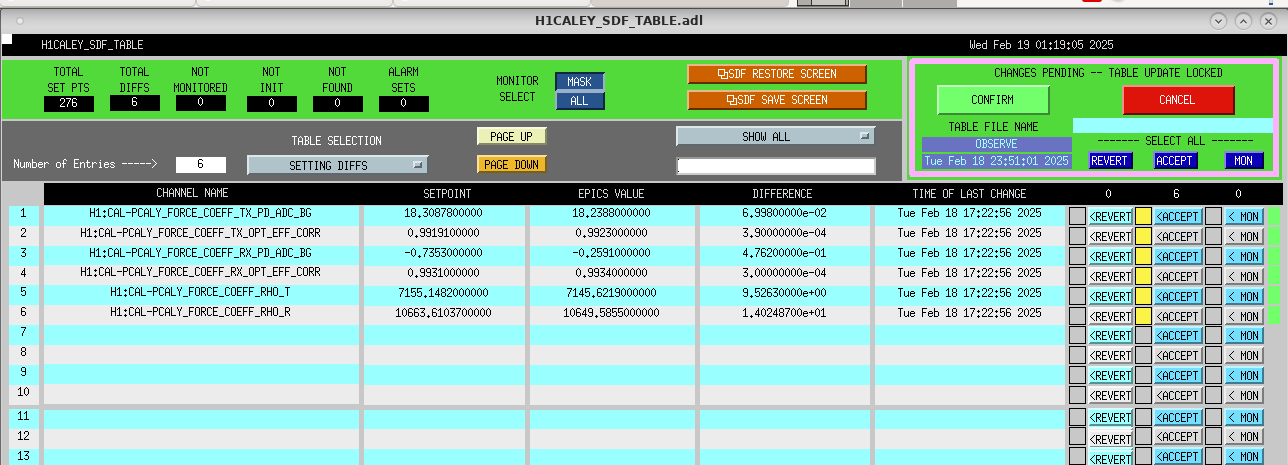
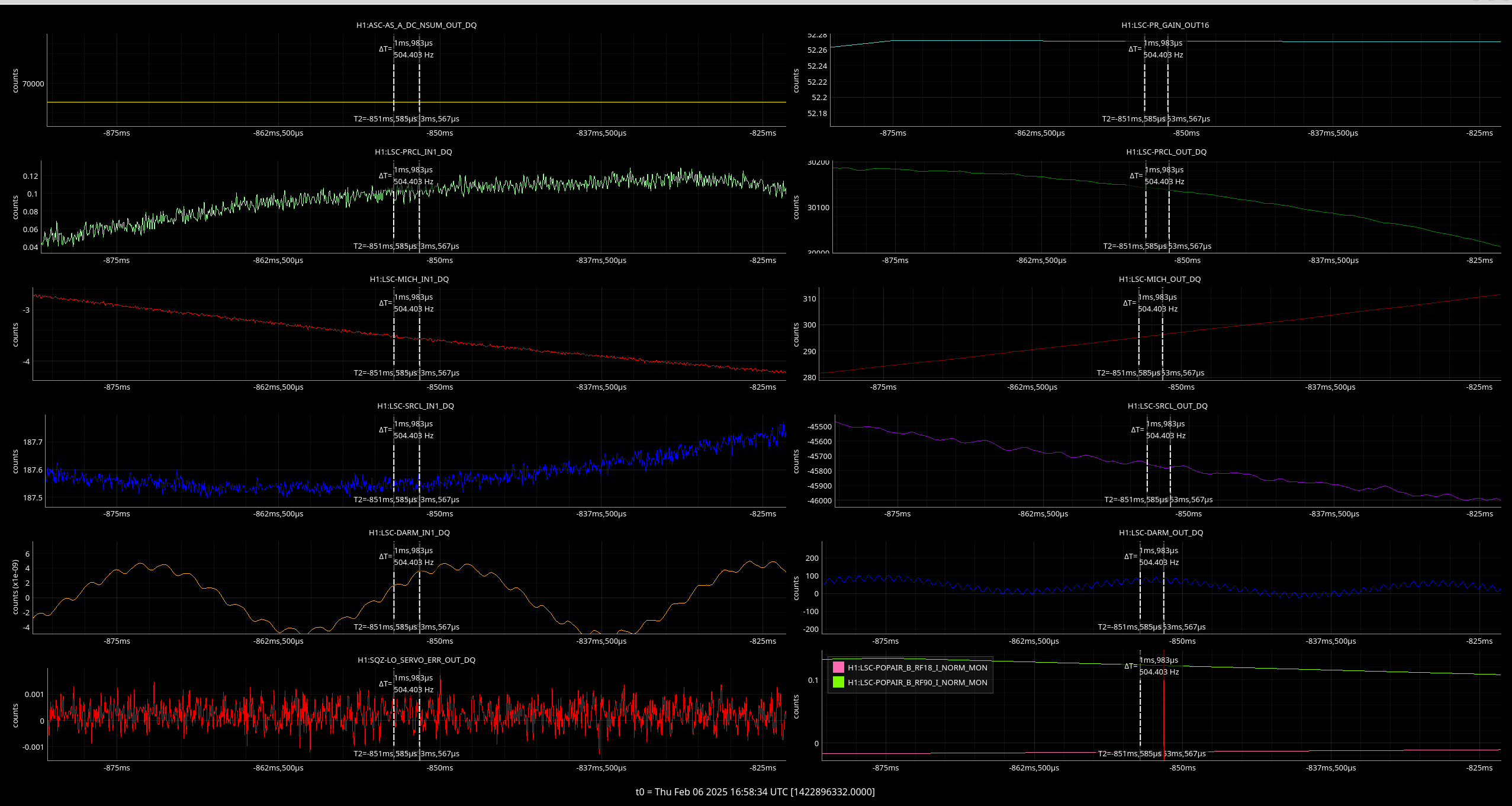
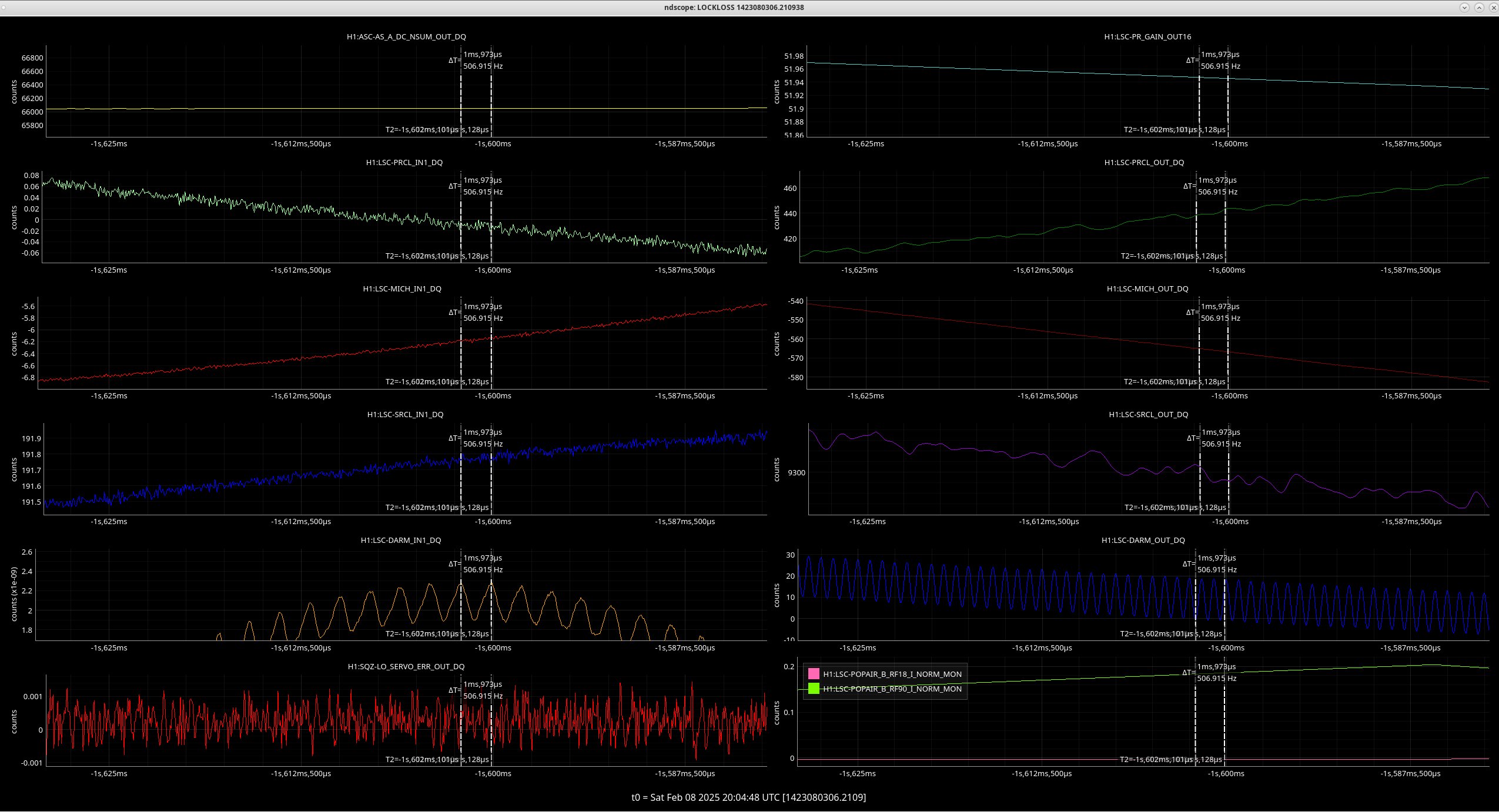
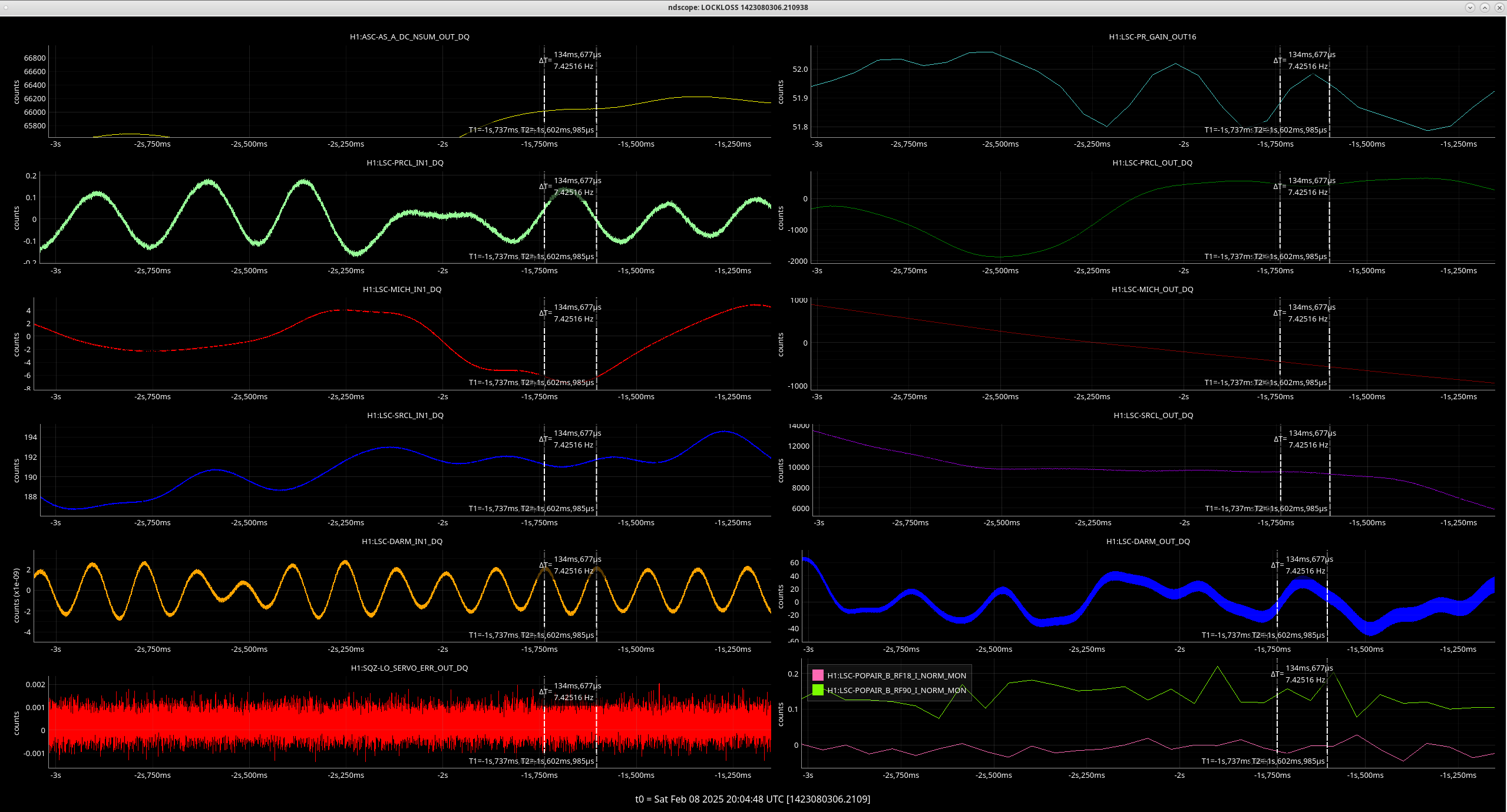
EY Timing Fanout Errors
Daniel, Marc, Jonathan, Erik, Ibrahim, Dave:
Soon after lunchtime the timing system started flashing RED on the CDS overview. Investigation tracked this down to the EY fanout, port_5 (numbering from zero, so the sixth physical port). This port sends the timing signal to h1iscey's IO Chassis LIGO Timing Card.
Marc and Dave went to EY at 16:30 with spare SFPs and timing card. After swapping these out with no success, the problem was tracked to the fanout port itself. With the original SFPs, fiber and timing card, using port_6 instead of port_5 fixed the issue.
For initial SFP switching, we just stopped all the models on h1iscey (h1iopiscey, h1iscey, h1pemey, h1caley, h1alsey). Later when we replaced the timing cards h1iscey was fenced from the Dolphin fabric and powered down.
The operator put all EY systems (SUS, SEI and ISC) into a safe mode before the start of the investigation.
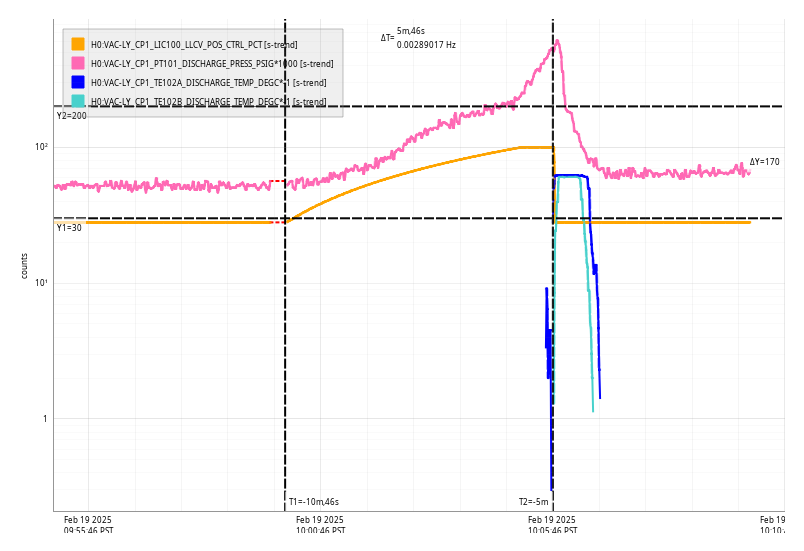
DAQ Restart
Erik, Dave:
The 0-leg restart was non-optimal. A new EDC restart procedure was being tested, whereby both trend-writers were turned off before h1edc was restarted to prevent channel-hopping which causes outlier data.
The reason for the DAQ restart was an expanded H1EPICS_FMCSSTAT.ini
After the restart of the 0-leg it was discovered that there were some naming issues with the FMCS STAT FCES channels. Erik regenerated a new H1EPICS_FMCSSTAT.ini and the EDC/0-leg were restarted again.
Following both 0-leg restarts, FW0 spontaneously restarted itself after running only a few minutes.
When the EDC and the 0-leg were stable, the 1-leg was restarted. During this restart NDS1 came up with a temporary daqdrc serving TW1 past data from its temporary location.
Reboots/Restarts
Tue18Feb2025
LOC TIME HOSTNAME MODEL/REBOOT
09:45:03 h1susauxb123 h1edc[DAQ] <<< first edc restart, incorrect FCES names
09:46:02 h1daqdc0 [DAQ] <<< first 0-leg restart
09:46:10 h1daqtw0 [DAQ]
09:46:11 h1daqfw0 [DAQ]
09:46:12 h1daqnds0 [DAQ]
09:46:19 h1daqgds0 [DAQ]
09:47:13 h1daqgds0 [DAQ] <<< GDS0 needed a restart
09:52:58 h1daqfw0 [DAQ] <<< Sponteneous FW0 restart
09:56:21 h1susauxb123 h1edc[DAQ] <<< second edc restart, all channels corrected
09:57:44 h1daqdc0 [DAQ] <<< second 0-leg restart
09:57:55 h1daqfw0 [DAQ]
09:57:55 h1daqtw0 [DAQ]
09:57:56 h1daqnds0 [DAQ]
09:58:03 h1daqgds0 [DAQ]
10:03:00 h1daqdc1 [DAQ] <<< 1-leg restart
10:03:12 h1daqfw1 [DAQ]
10:03:13 h1daqnds1 [DAQ]
10:03:13 h1daqtw1 [DAQ]
10:03:21 h1daqgds1 [DAQ]
10:04:07 h1daqgds1 [DAQ] <<< GDS1 restart
10:04:48 h1daqfw0 [DAQ] <<< Spontaneous FW0 restart
17:20:37 h1iscey ***REBOOT*** <<< power up h1iscey following timing issue on fanout port
17:22:17 h1iscey h1iopiscey
17:22:30 h1iscey h1pemey
17:22:43 h1iscey h1iscey
17:22:56 h1iscey h1caley
17:23:09 h1iscey h1alsey

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}