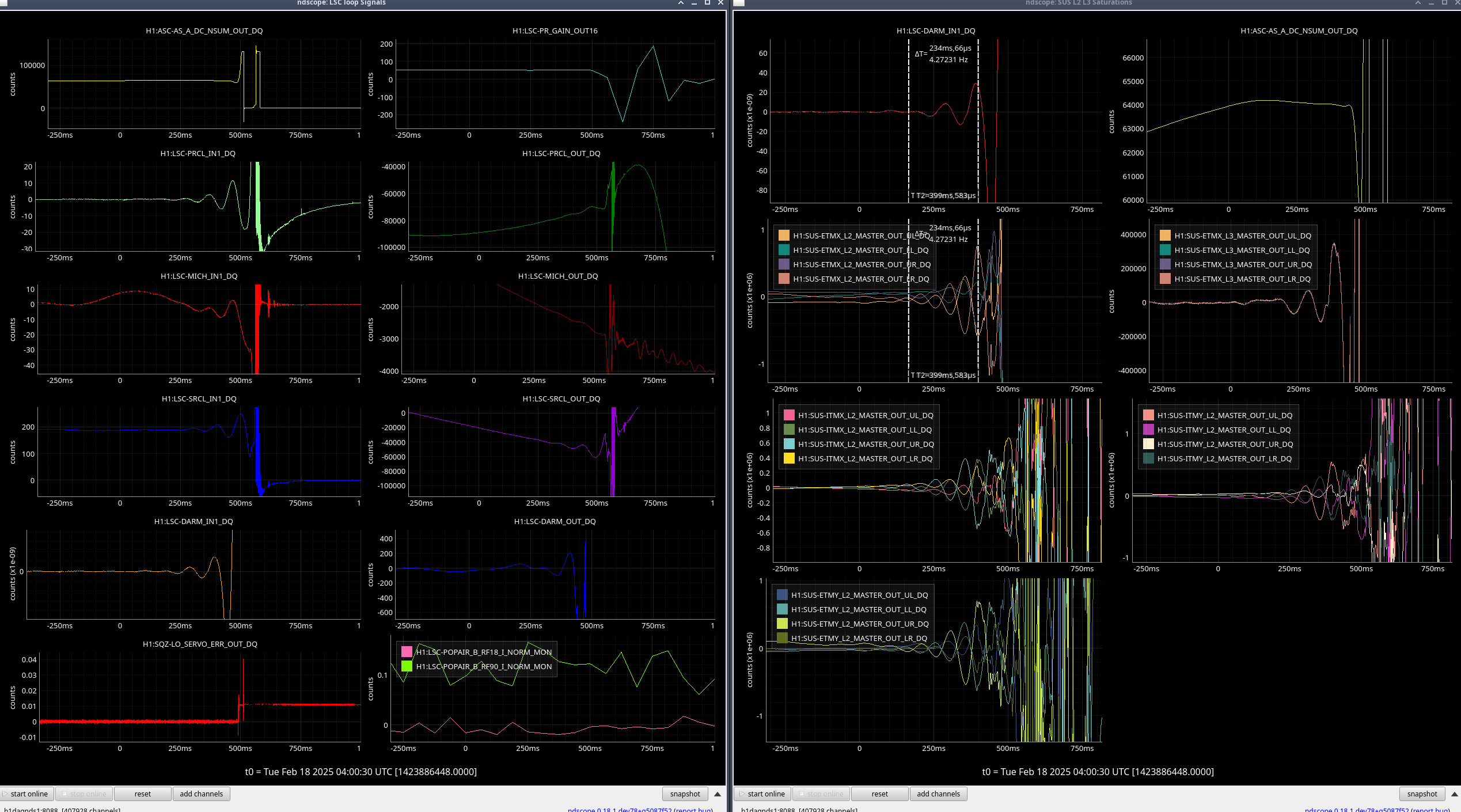
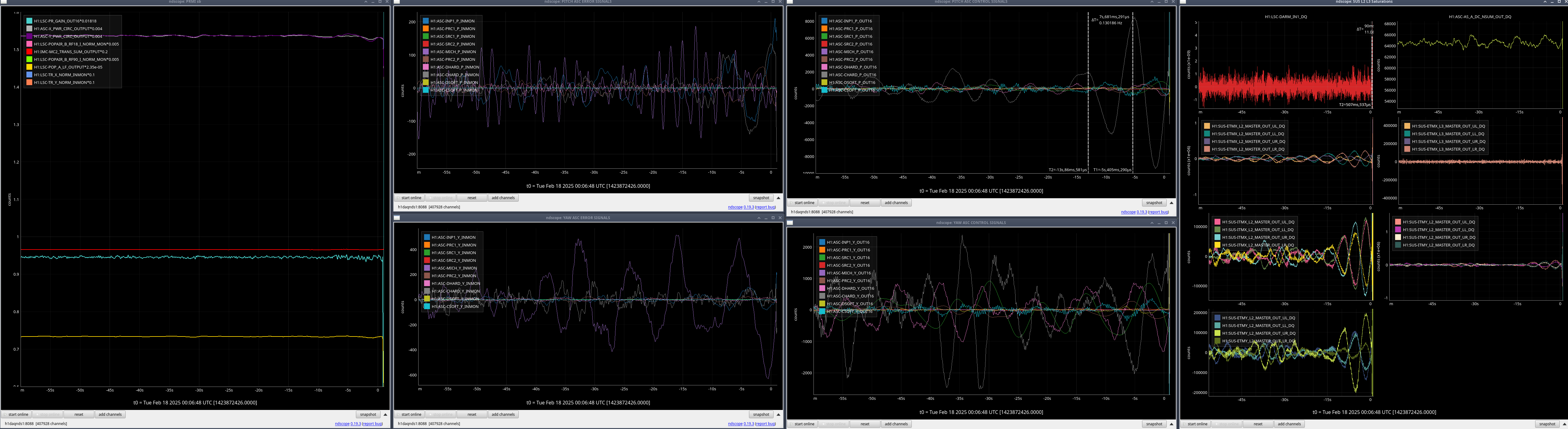
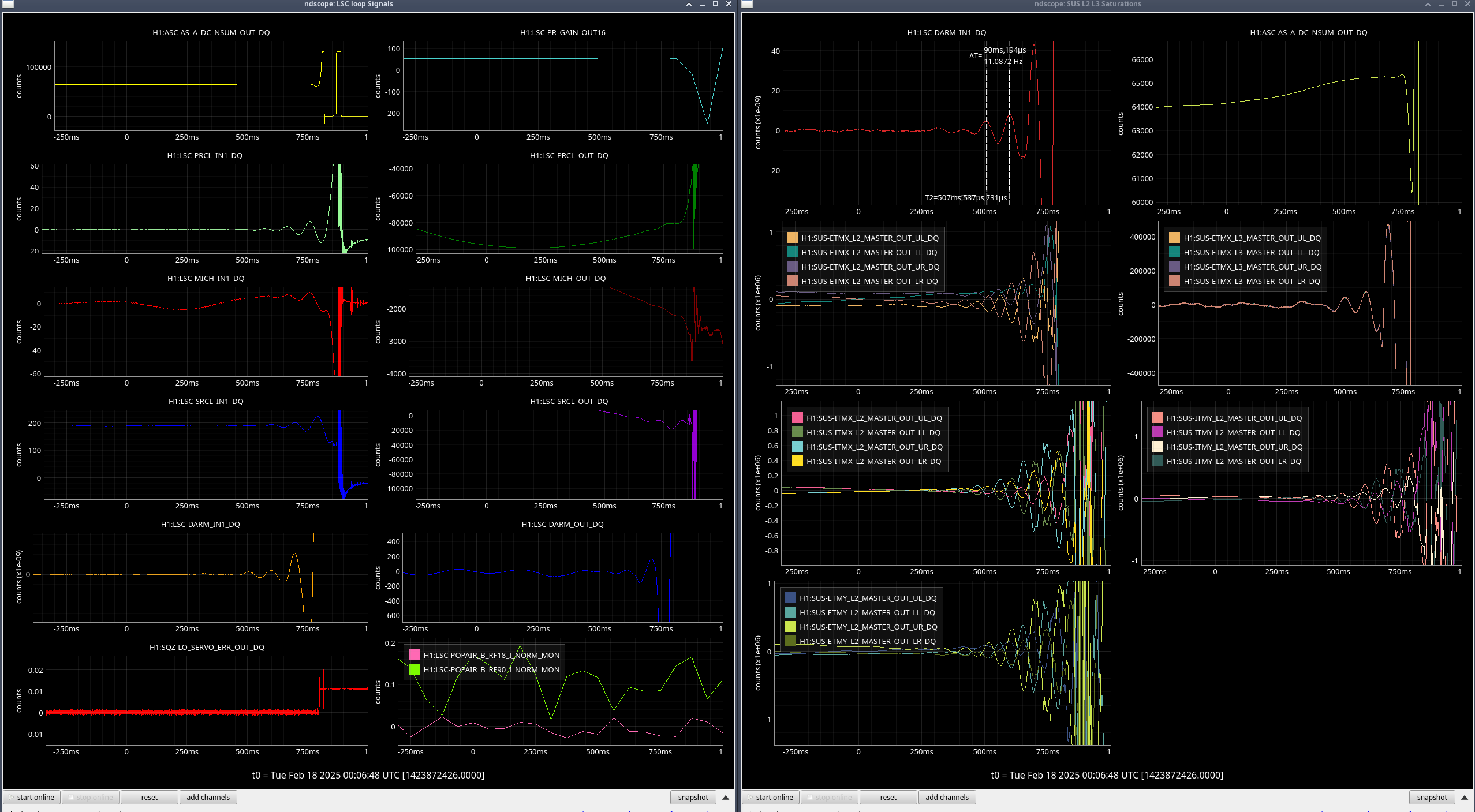
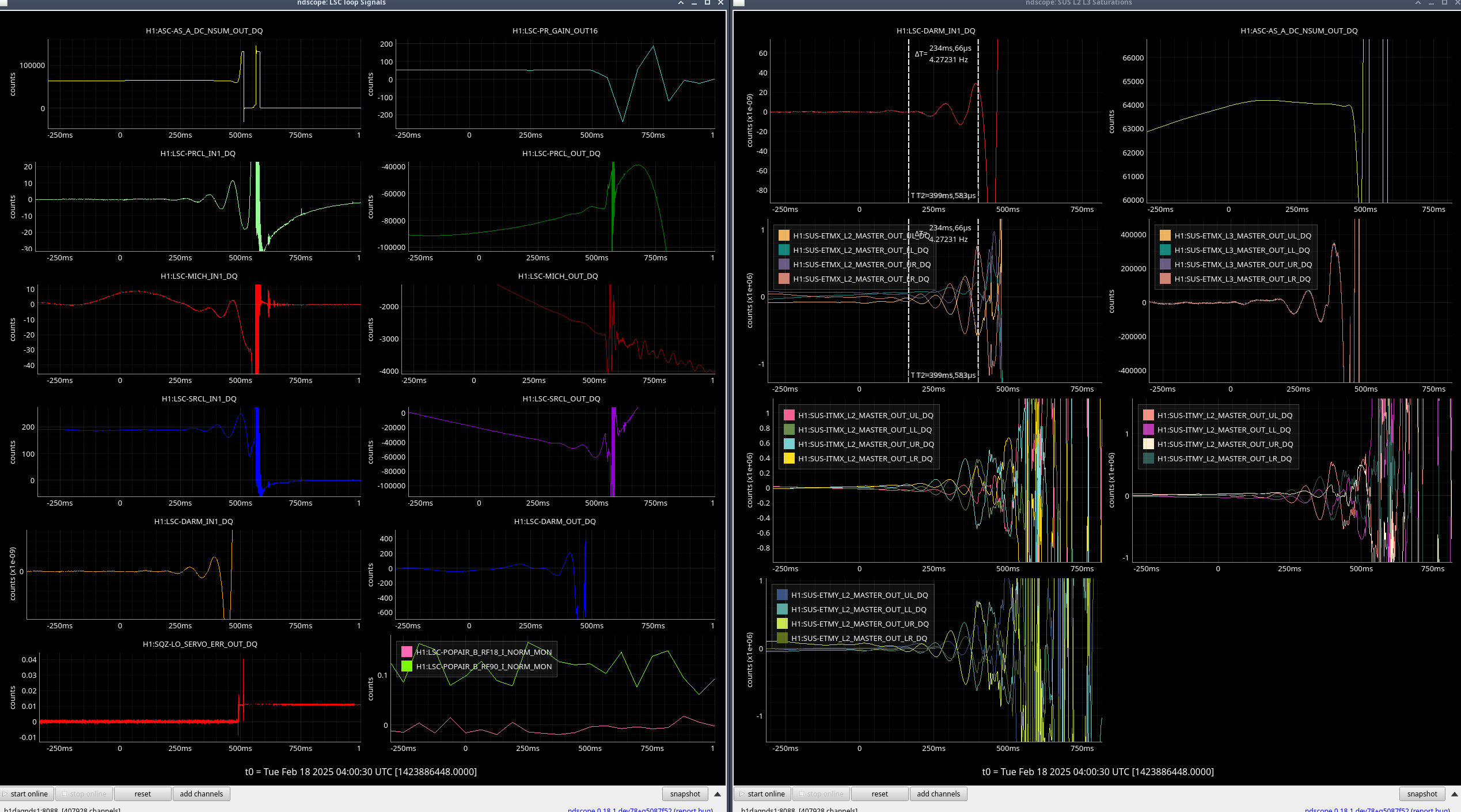
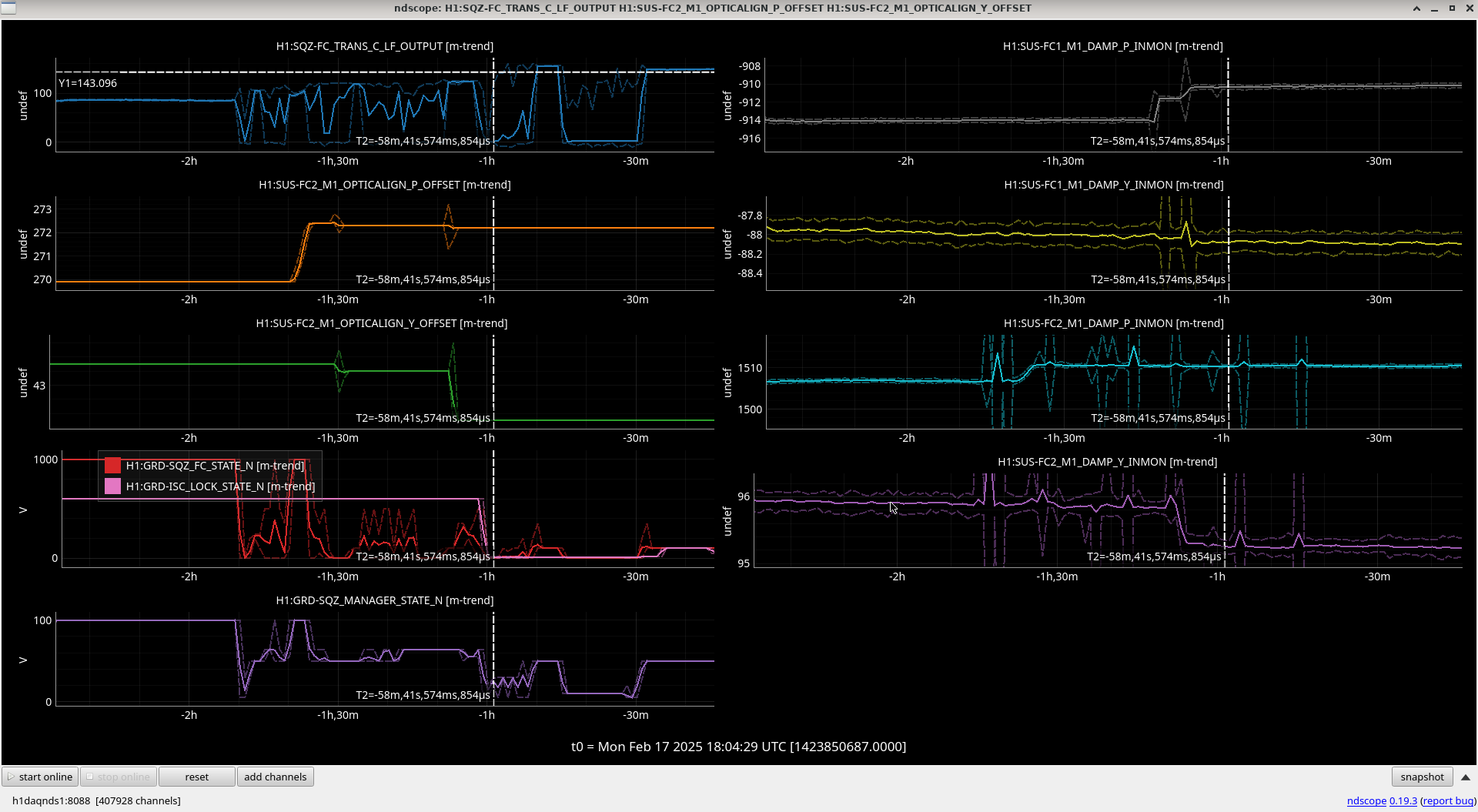
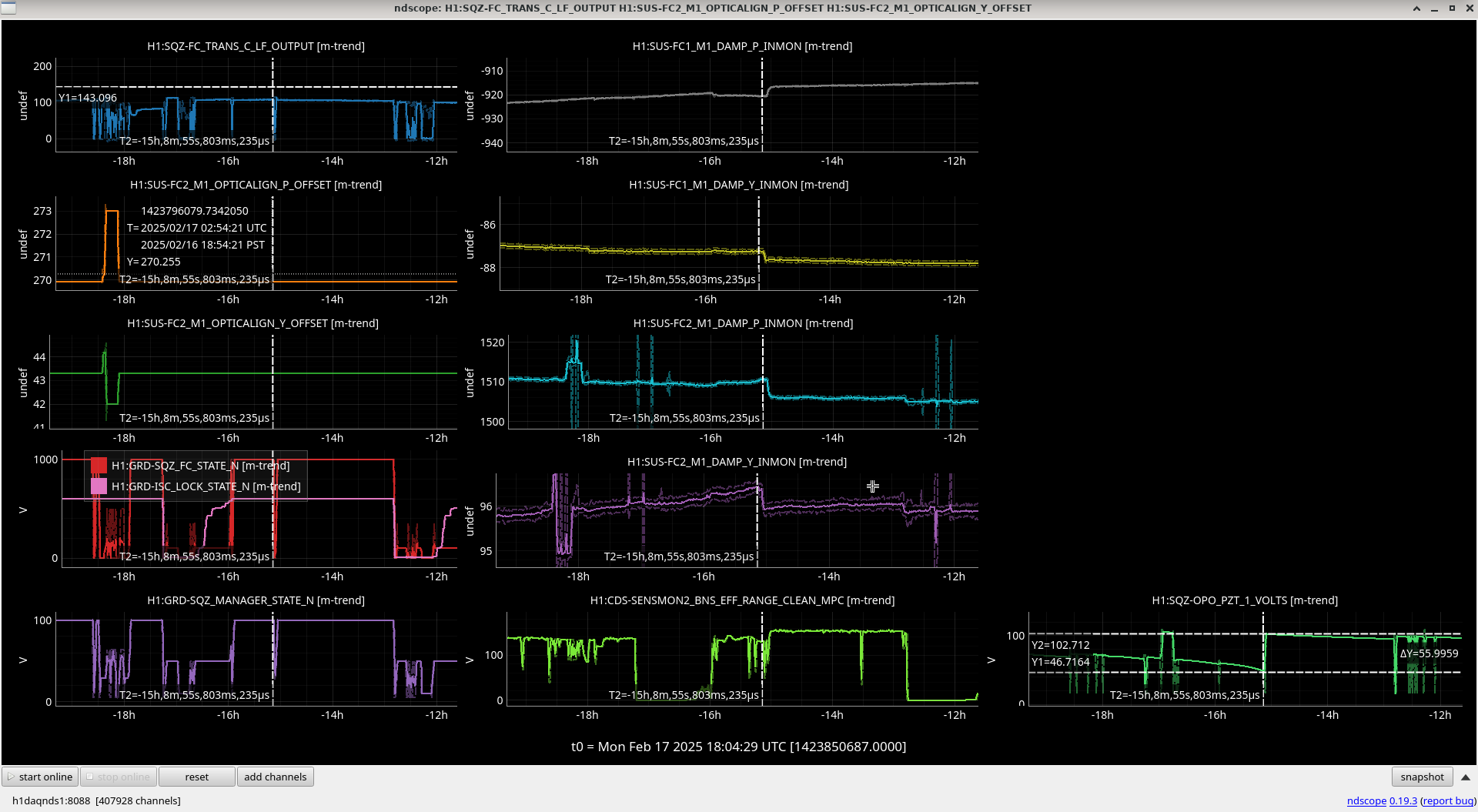
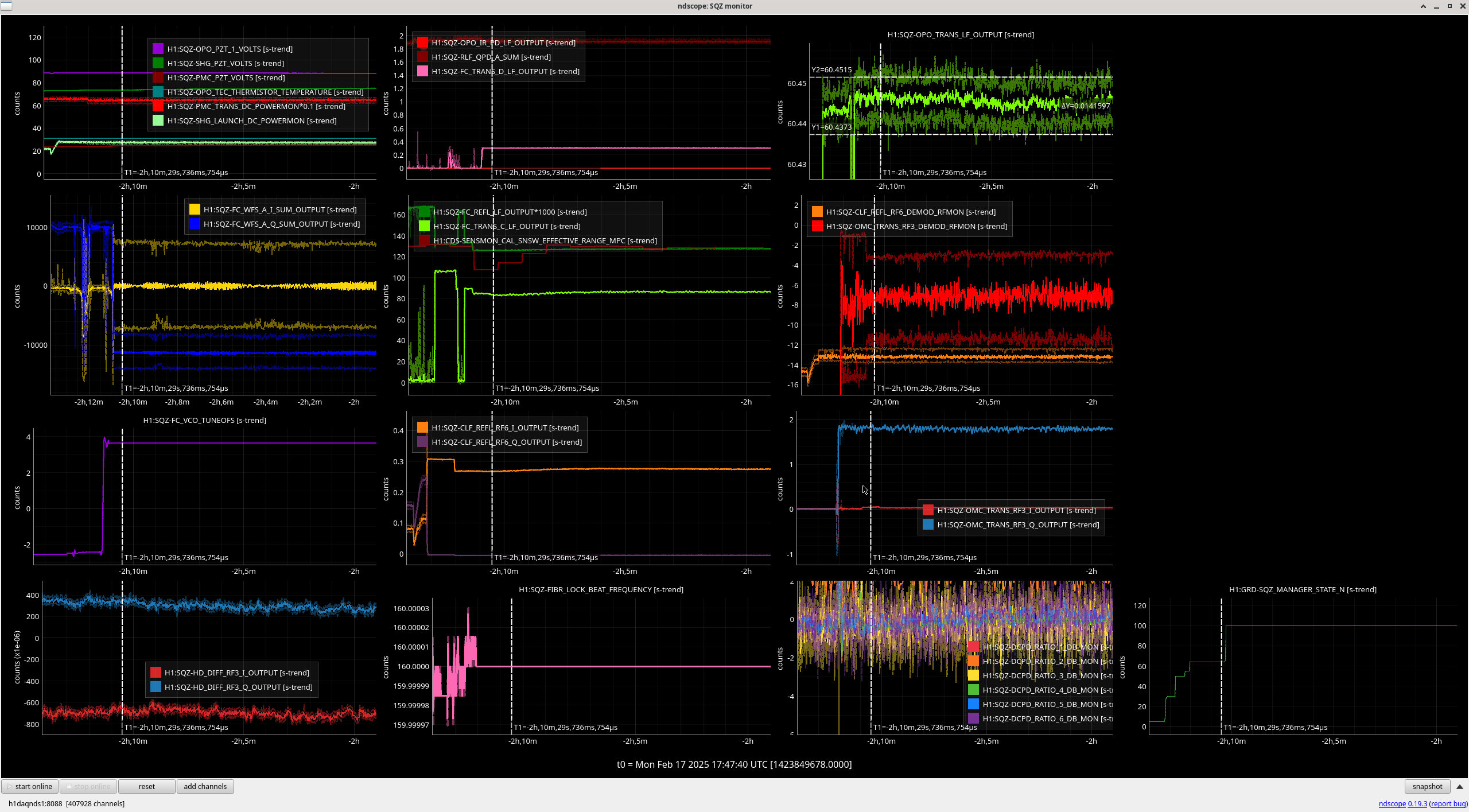
I reviewed the weekend lockloss where lock was lost during the calibration sweep on Saturday.
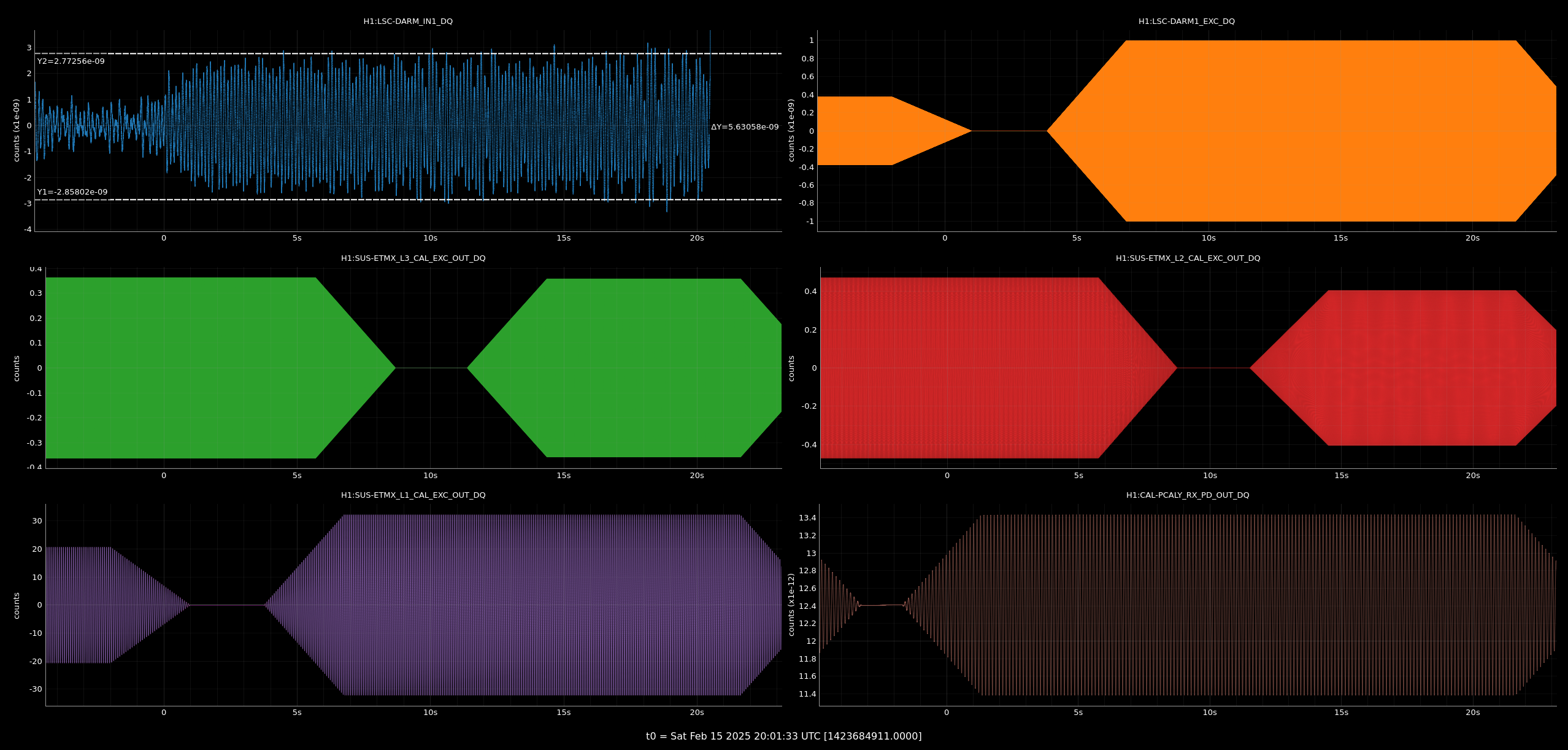
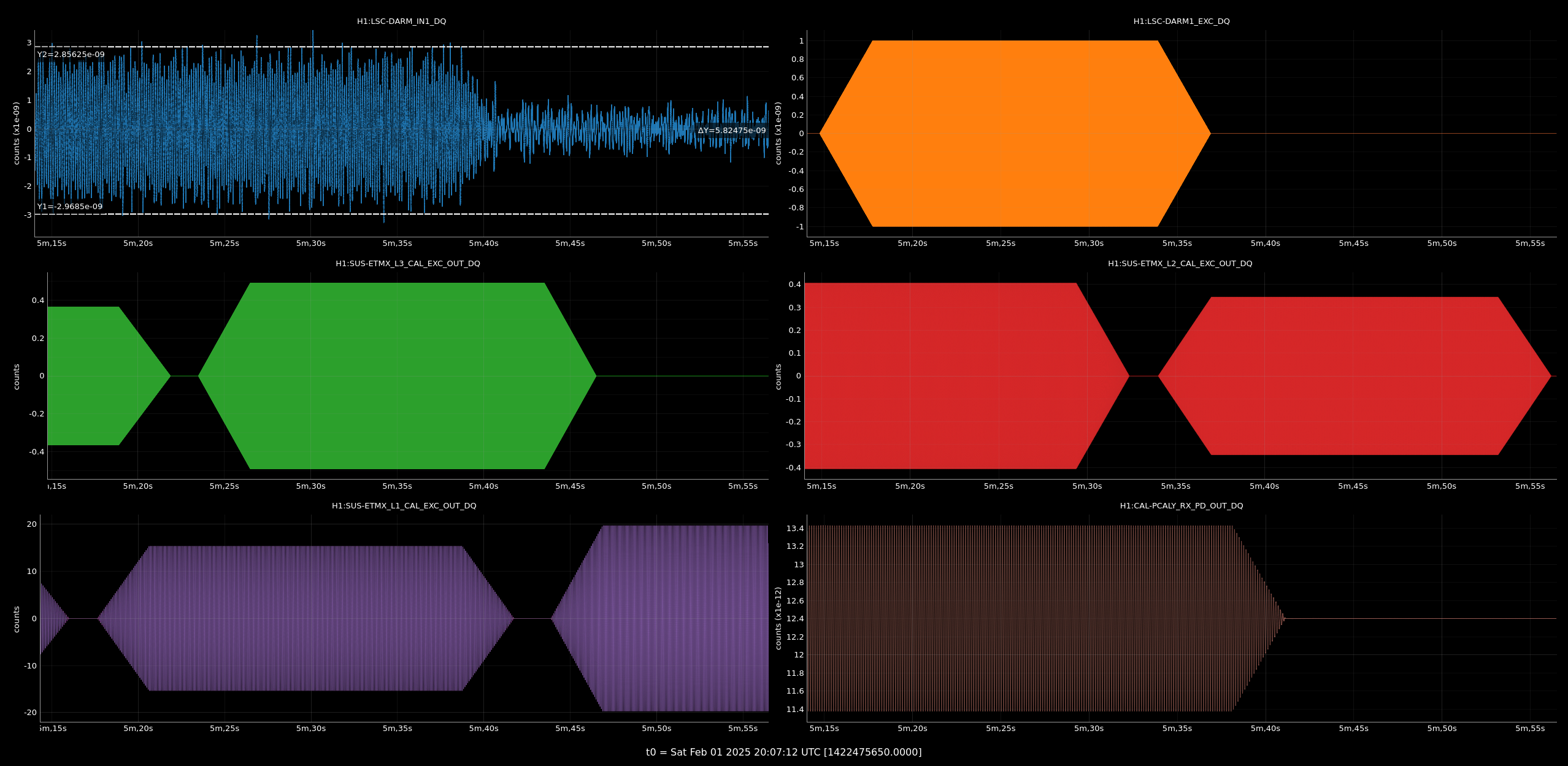
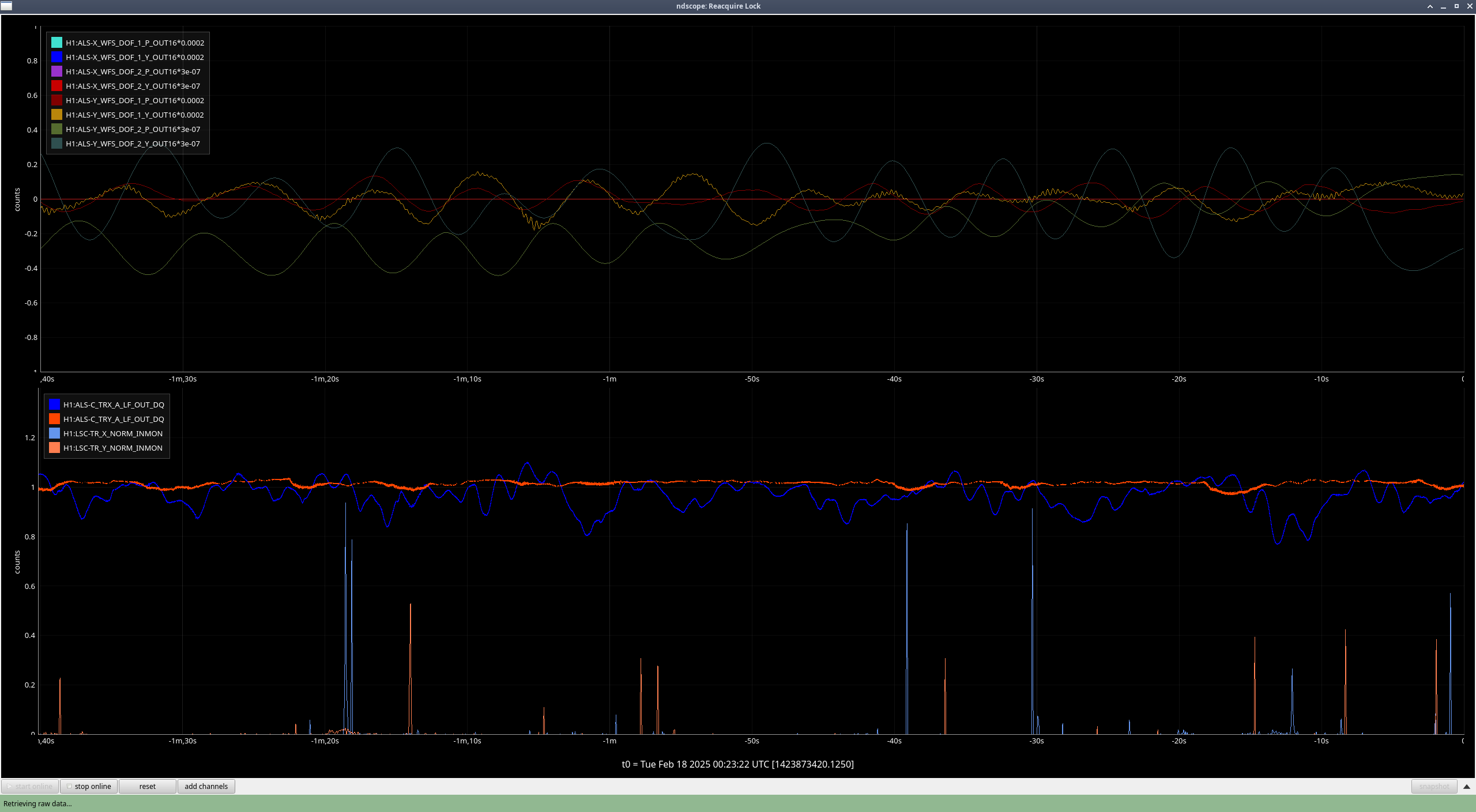
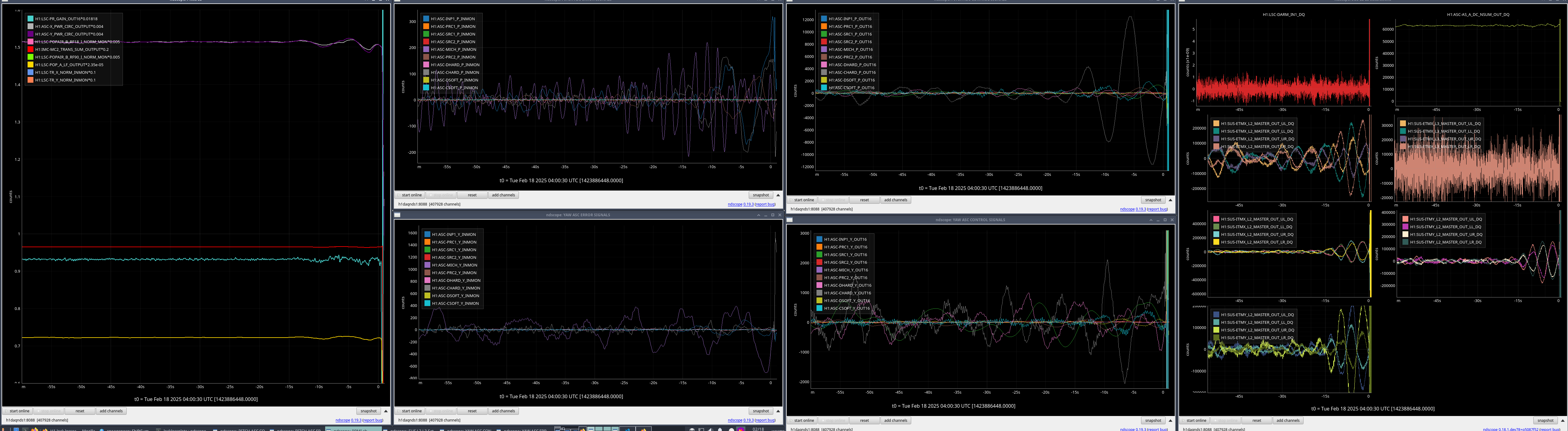
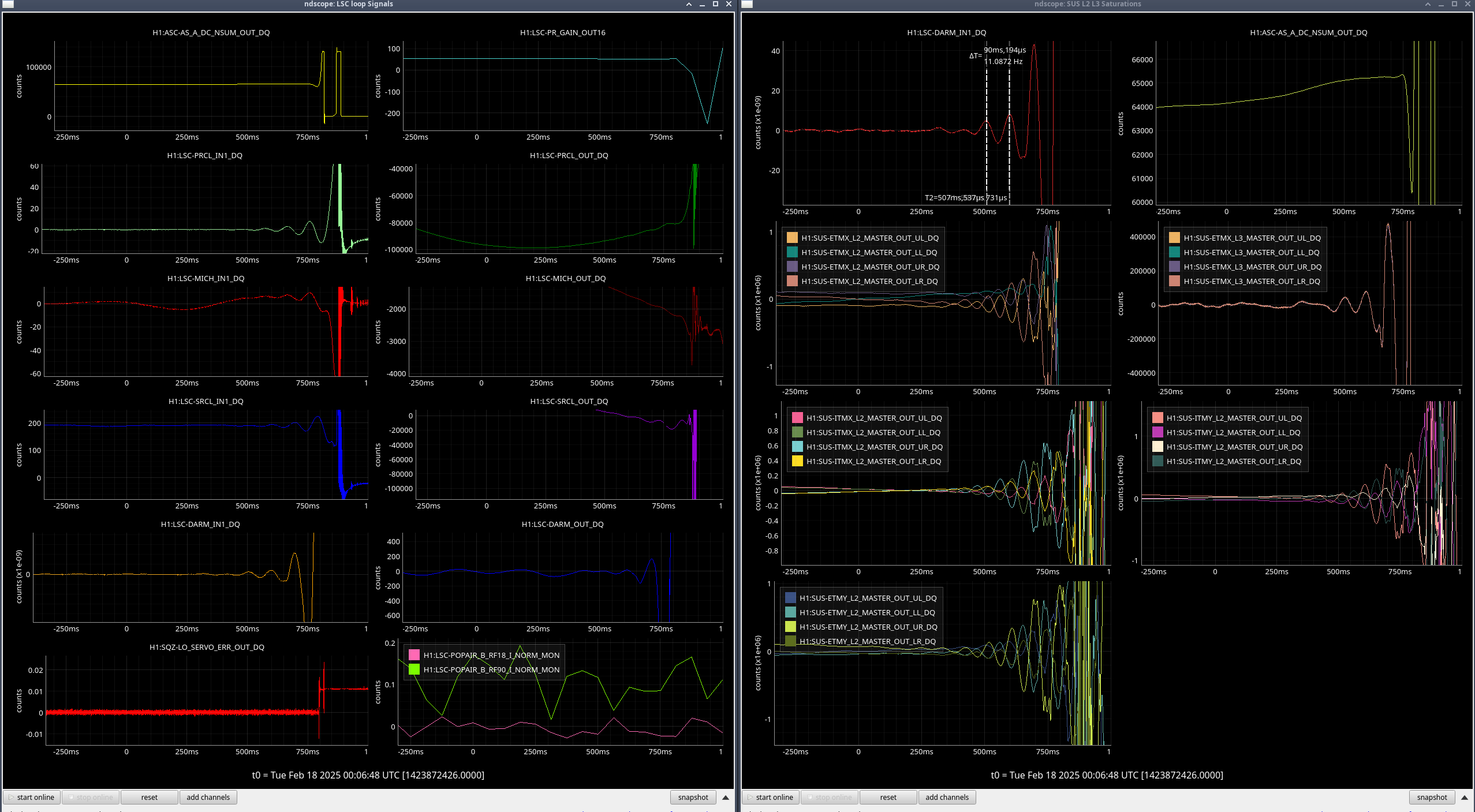
I've compared the calibration injections and what DARM_IN1 is seeing [ndscopes], relative to the last successful injection [ndscopes].
Looks pretty much the same but DARM_IN1 is even a bit lower because I've excluded the last frequency point in the DARM injection which sees the least loop suppression.
It looks like this time the lockloss was a coincidence. BUT. We desperately need to get a successful sweep to update the calibration.
I'll be reverting the cal sweep INI file, in the wiki, to what was used for the last successful injection (even though it includes that last point which I suspected caused the last 2 locklosses), out of abundance of caution and hoping the cause of locklosses is something more subtle that I'm not yet catching.
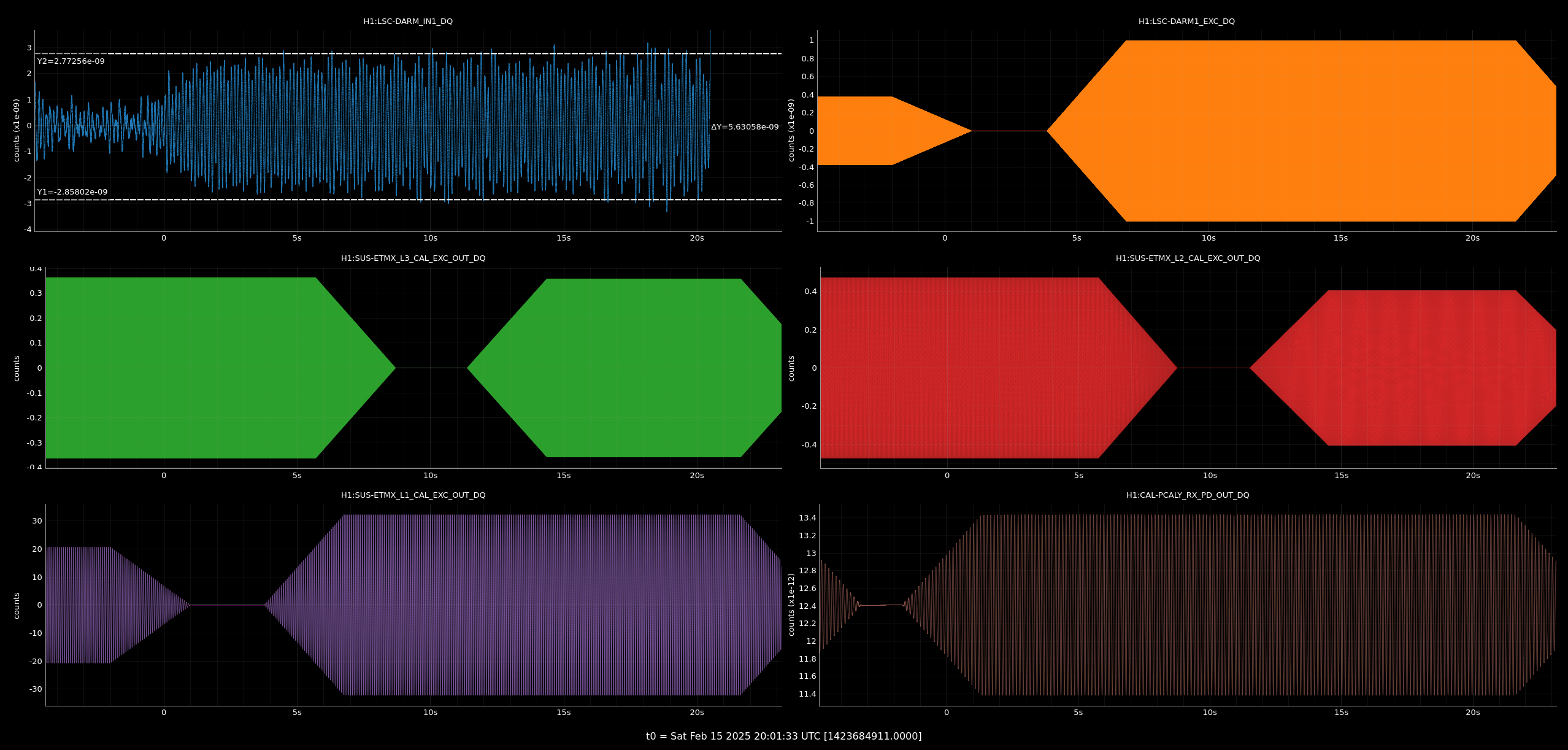
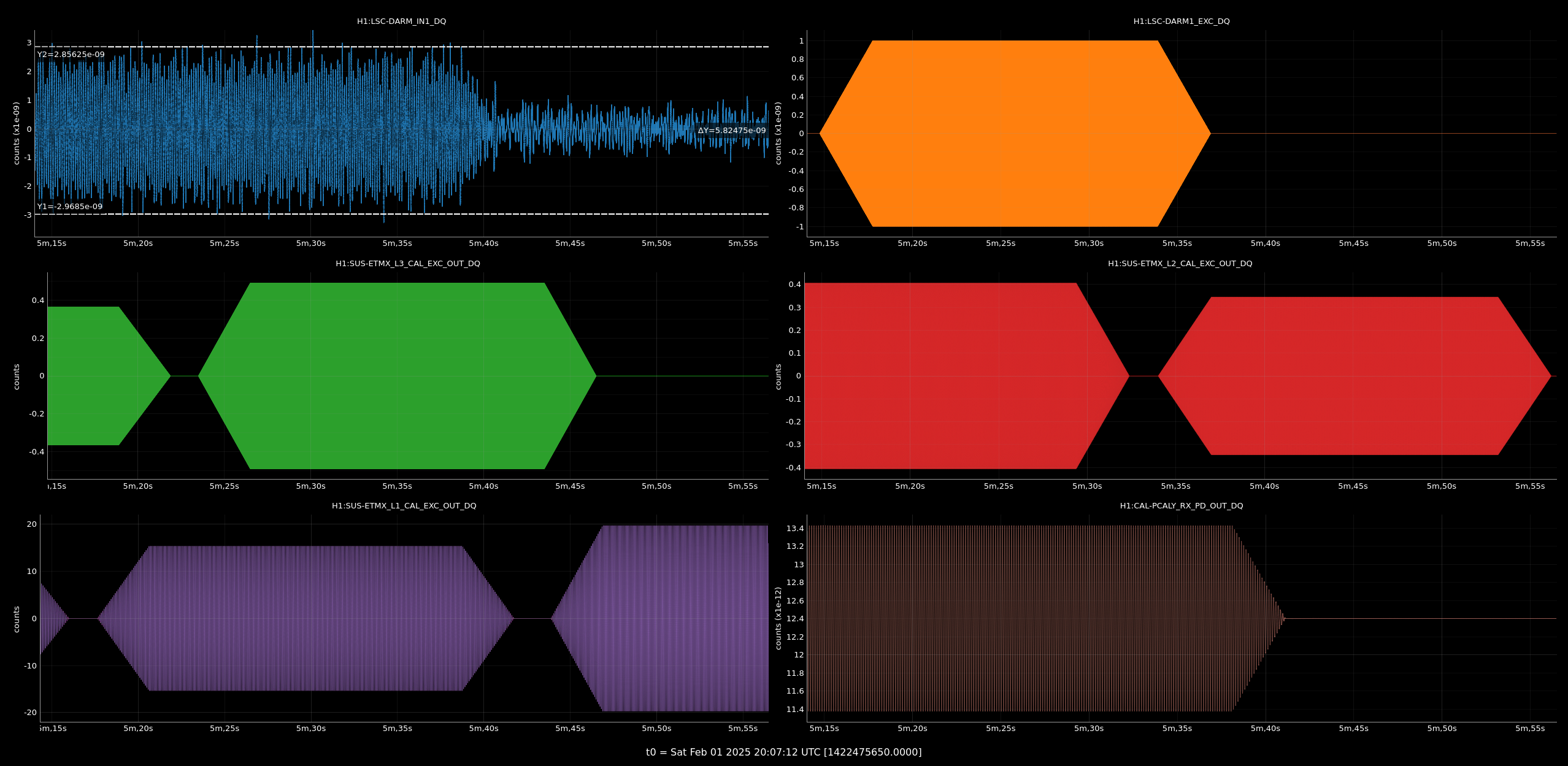
Despite the lockloss, I was able to utilise the log file saved in /opt/rtcds/userapps/release/cal/common/scripts/simuLines/logs/H1/ (log file used as input into simulines.py), to regenerate the measurement files.
As you can imagine the points where the data is incomplete are missing but 95% of the sweep is present and fitting all looks great.
So it is in some way reassuring that in case we lose lock during a measurement, data gets salvaged and processed just fine.
Report attached.

How to salvage data from any failed attempt simulines injections:
- simulines siletently dumps log files into this directory:
/opt/rtcds/userapps/release/cal/common/scripts/simuLines/logs/{IFO}/ for IFO=L1,H1 - navitating there you will be greeted by a log the outputs of simulines every single time it has ever been run. The one you are interested in can be identified by the time, as the file name format is the same as the measurement and report directory time-name format.
- running the following will automagically populate .hdf5 files in the calibration measurement directories that the 'pydarm report' command searches in for new measurements:
'./simuLines.py -i /opt/rtcds/userapps/release/cal/common/scripts/simuLines/logs/H1/{time-name}.log'for time-name resembling20250215T193653Z- where '.
/simuLines.py' is the simulines exectuable and can have some full path like the calibration wiki does: './ligo/groups/cal/src/simulines/simulines/simuLines.py'



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}