Sheila, Camilla. Repeat of 78776, continuing 81575.
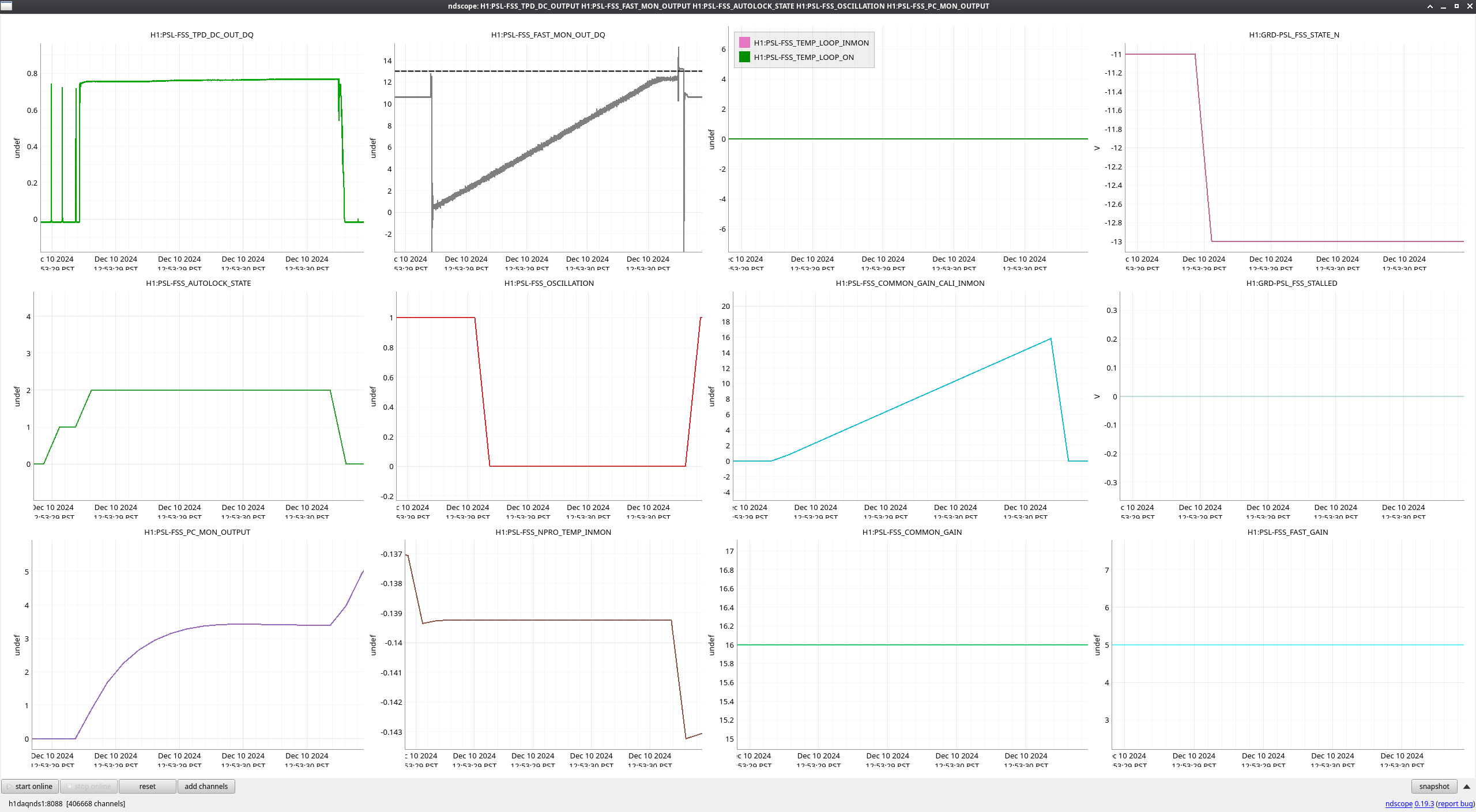
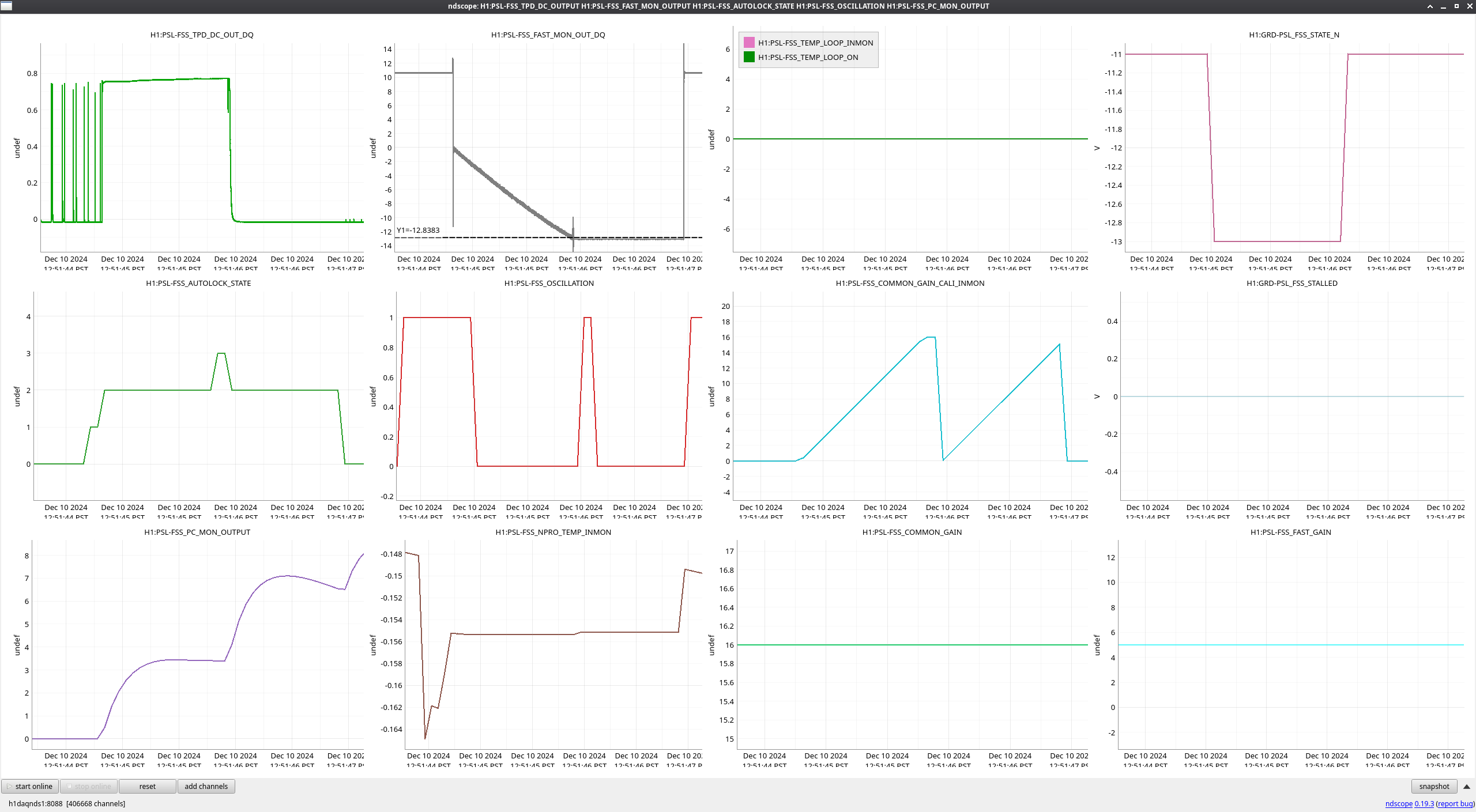
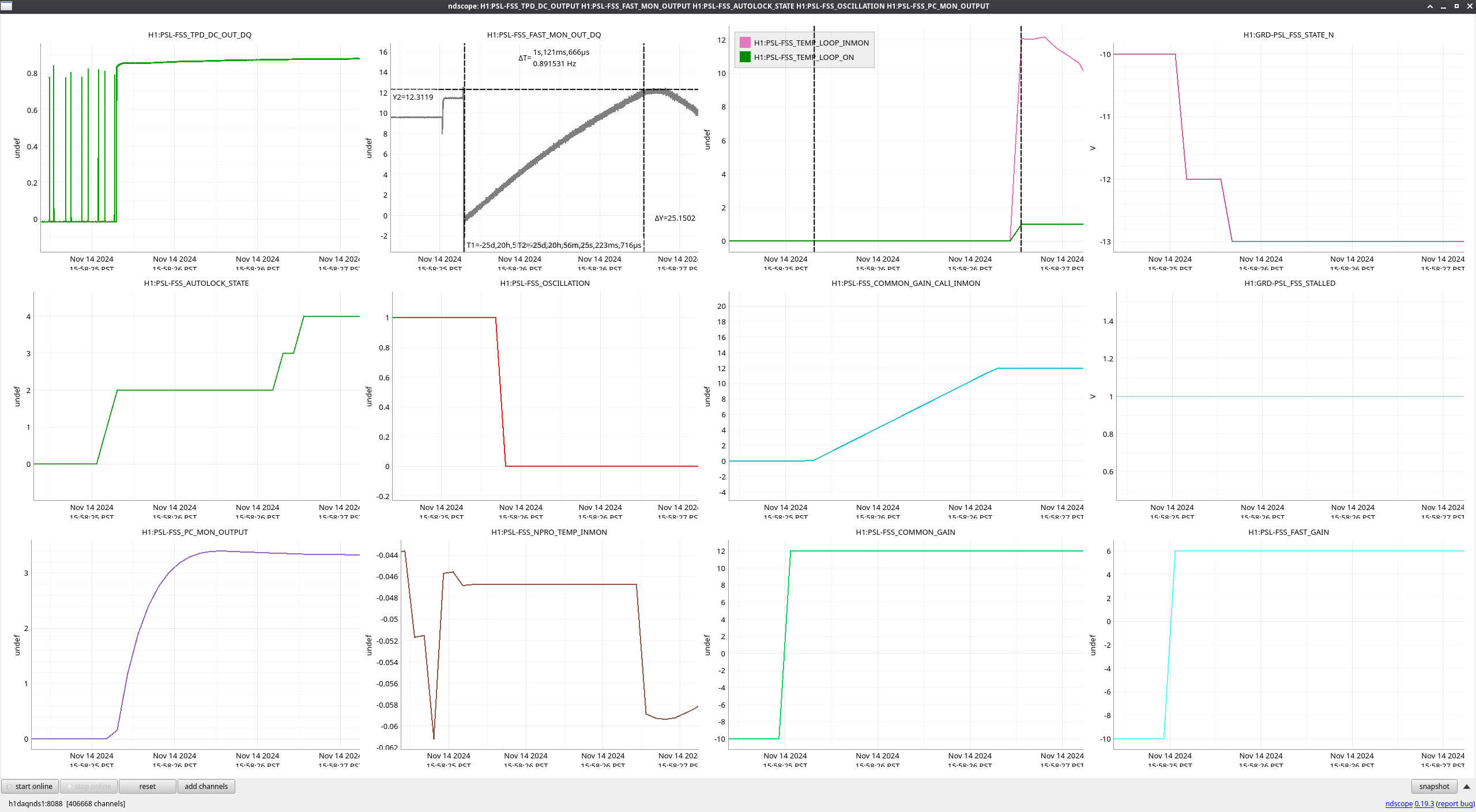
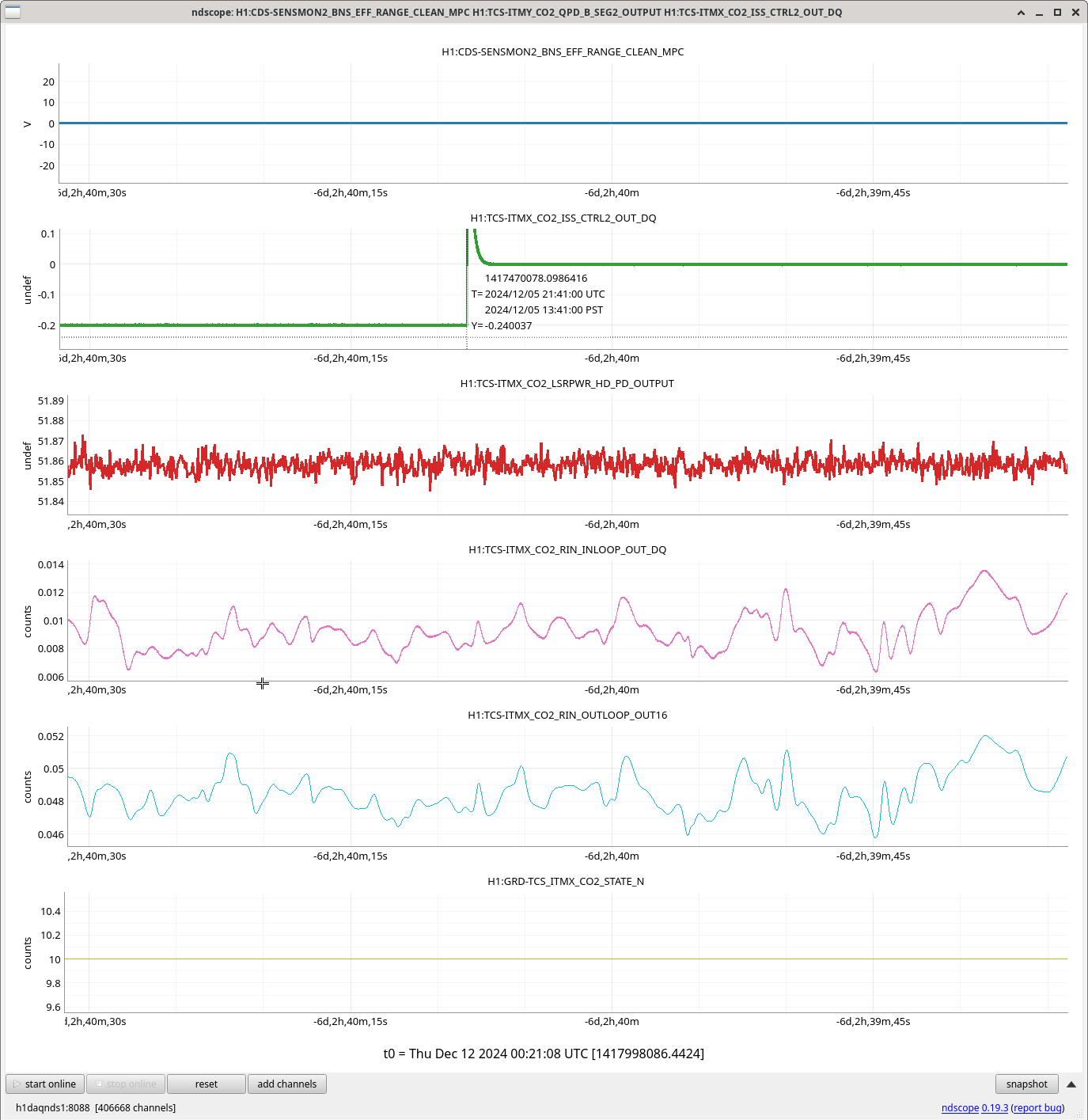
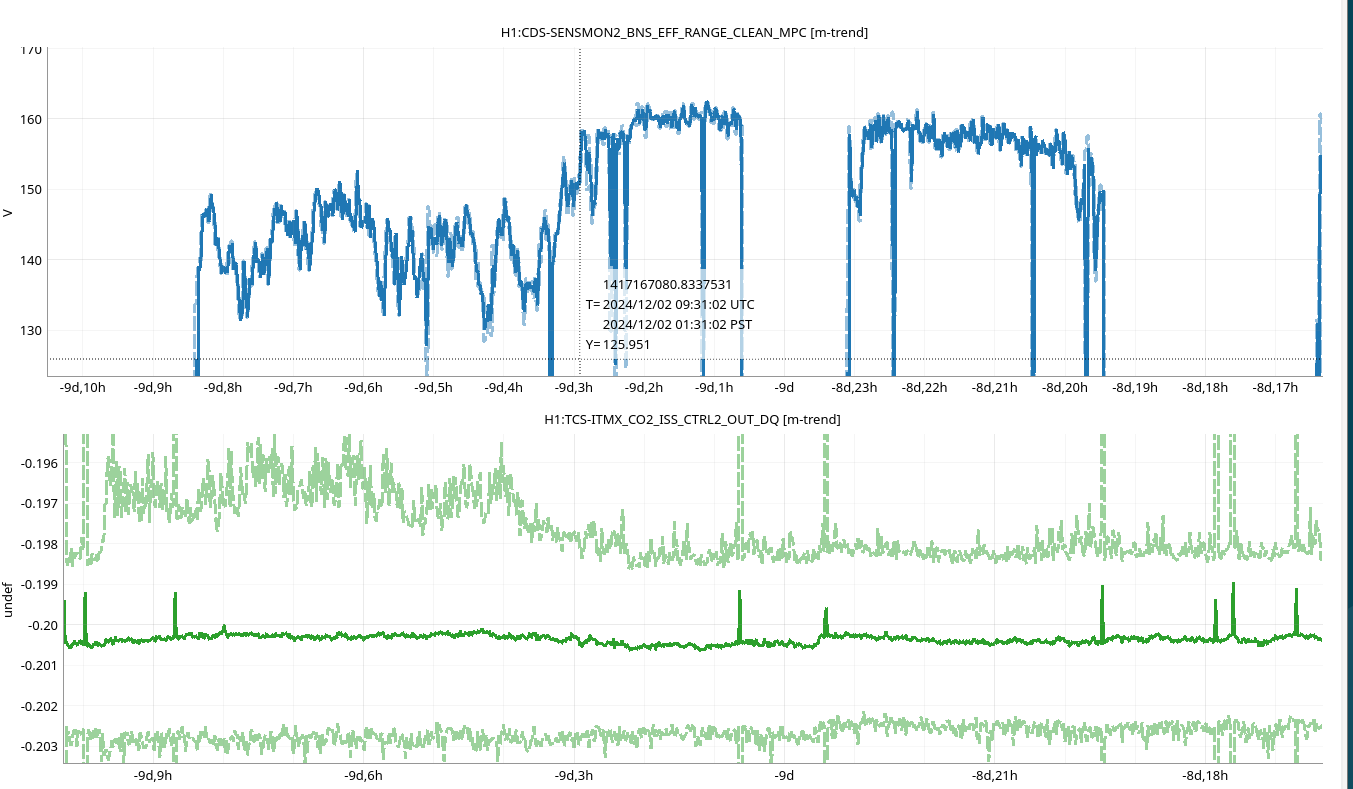
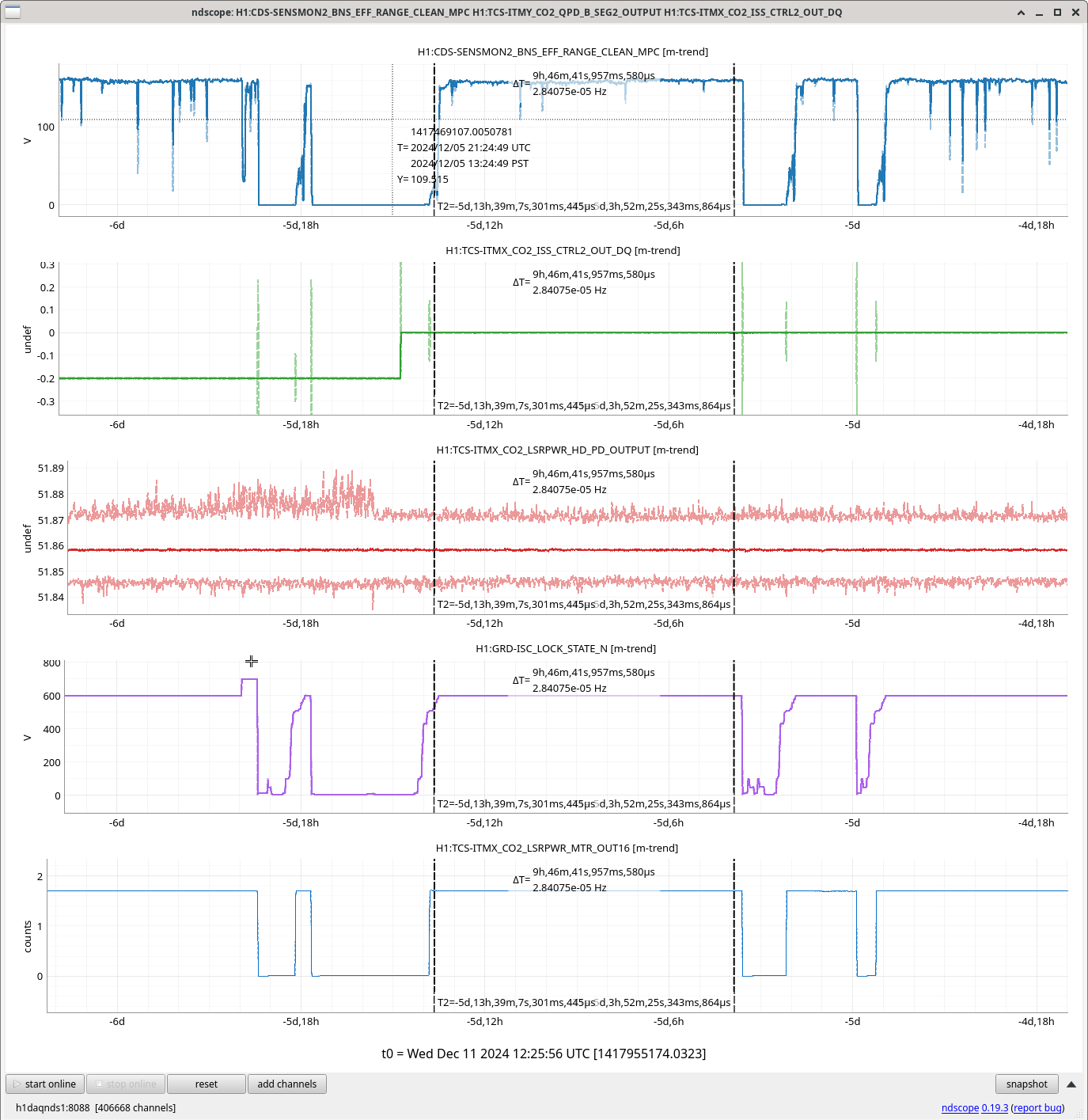
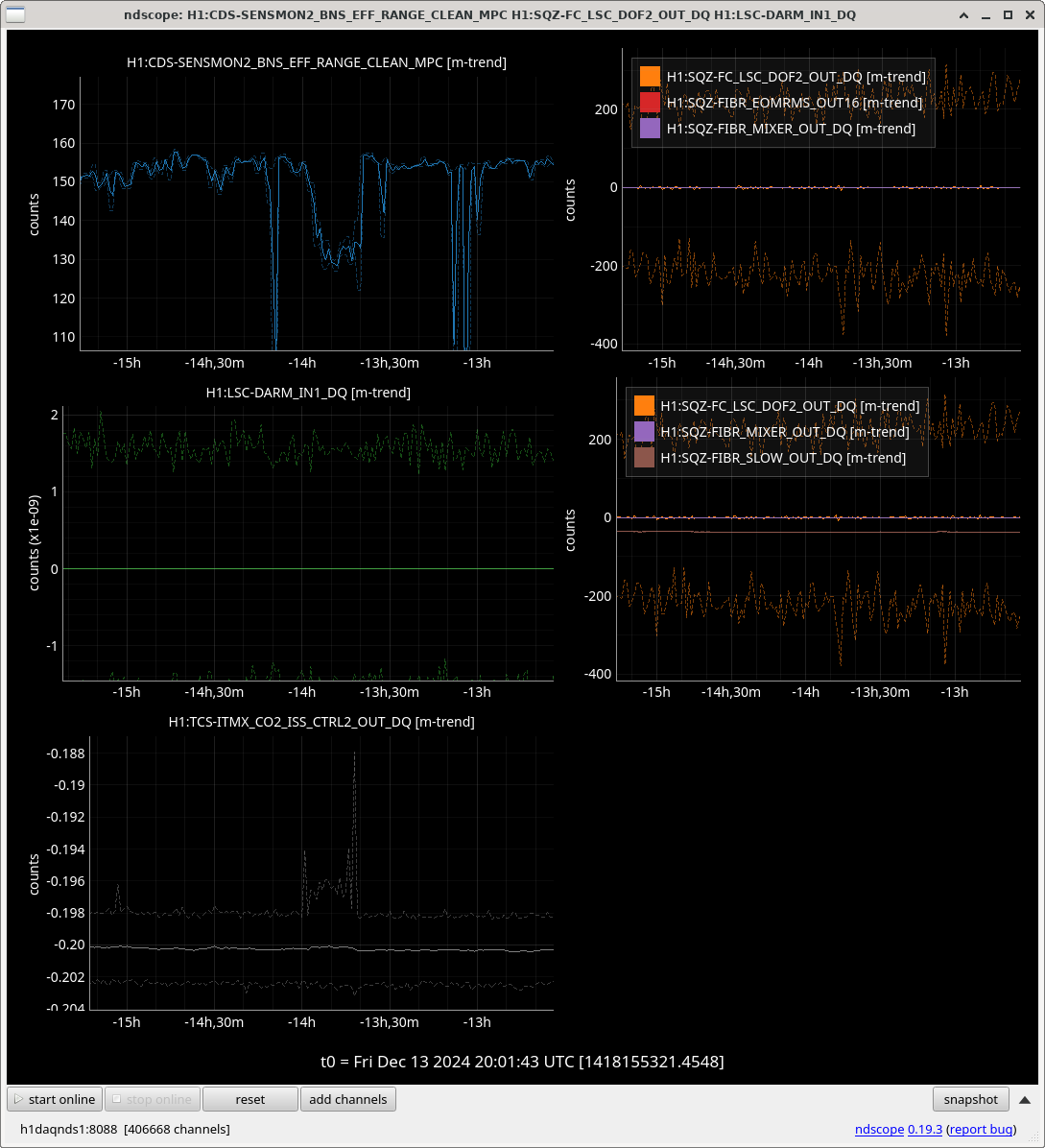
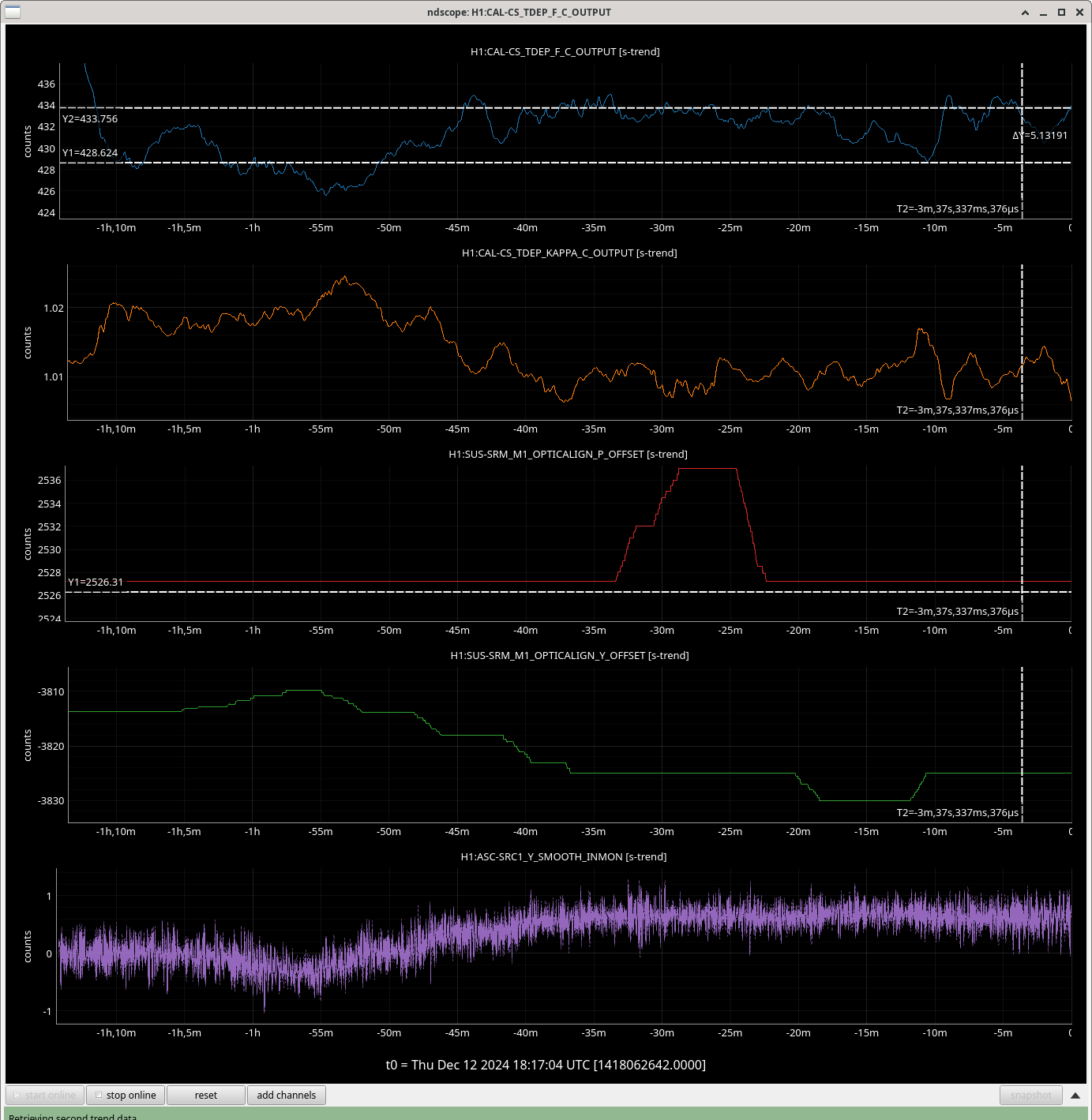
During the emergency July/August OFI vent, we accidentally left off the SRCL ASC offsets and the OM2 heater. Today we tried to find best SRCL1 ASC offsets with OM2 heater off. We could improve CAL FCC (but kappaC decreased) with SRC1 ASC YAW offset (-0.62) and adjusted SRCL LSC offset (-140) with SQZ FIS data. This decreased the range so we reverted settings back to nominal. May continue next week and look at FC de-tuning, OMC ASC offsets and LSC FFs as these may need to be updated too.
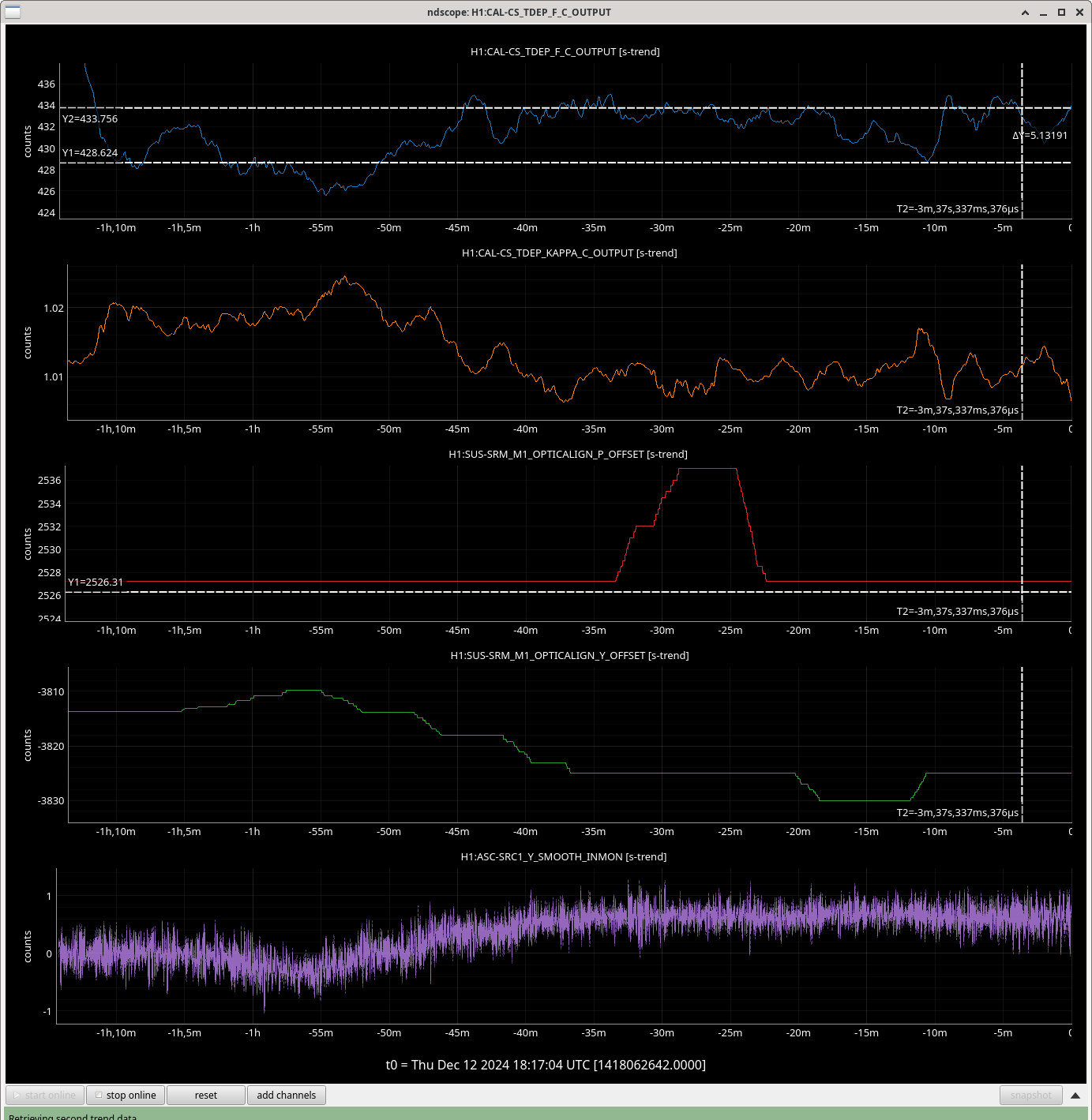
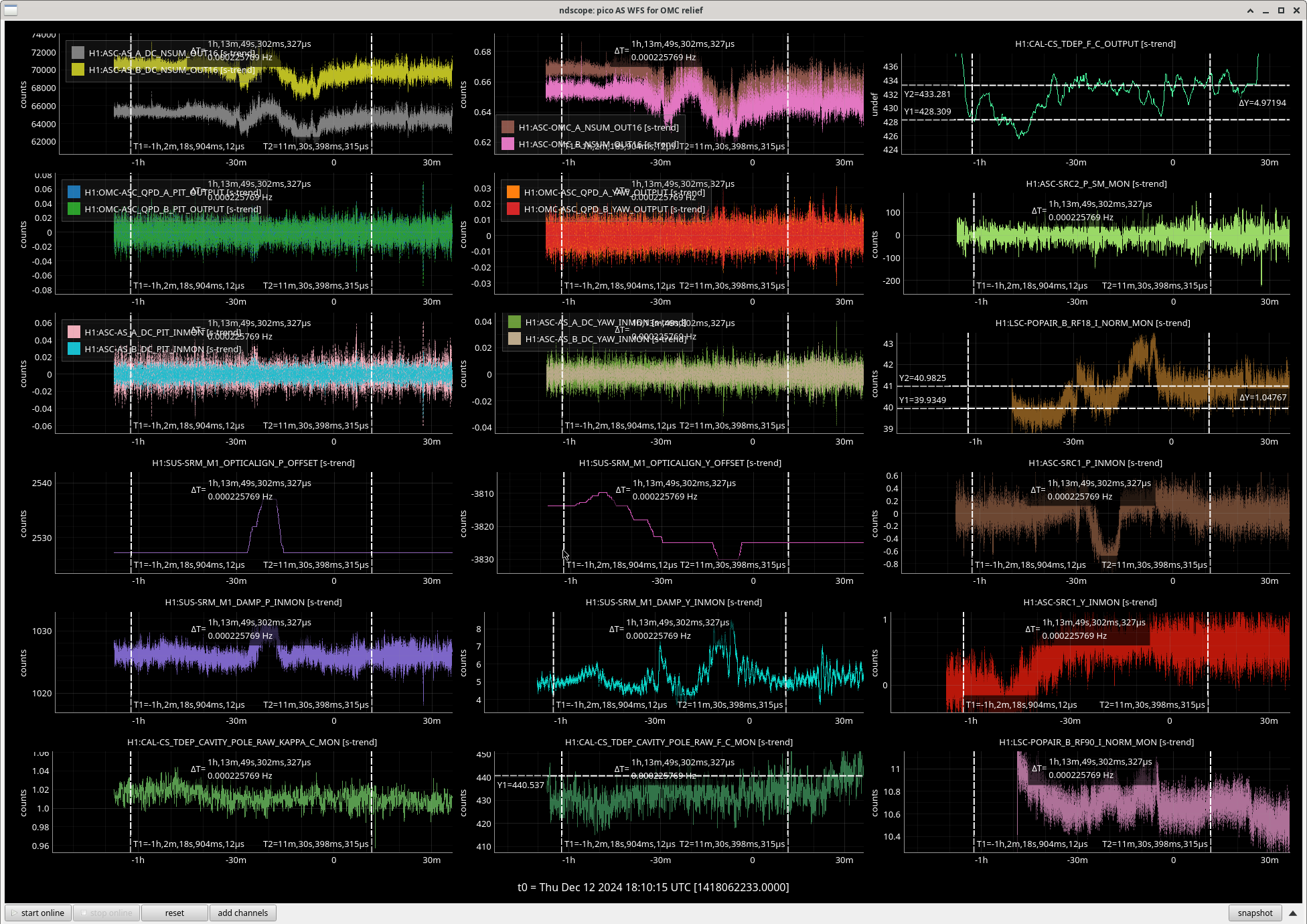
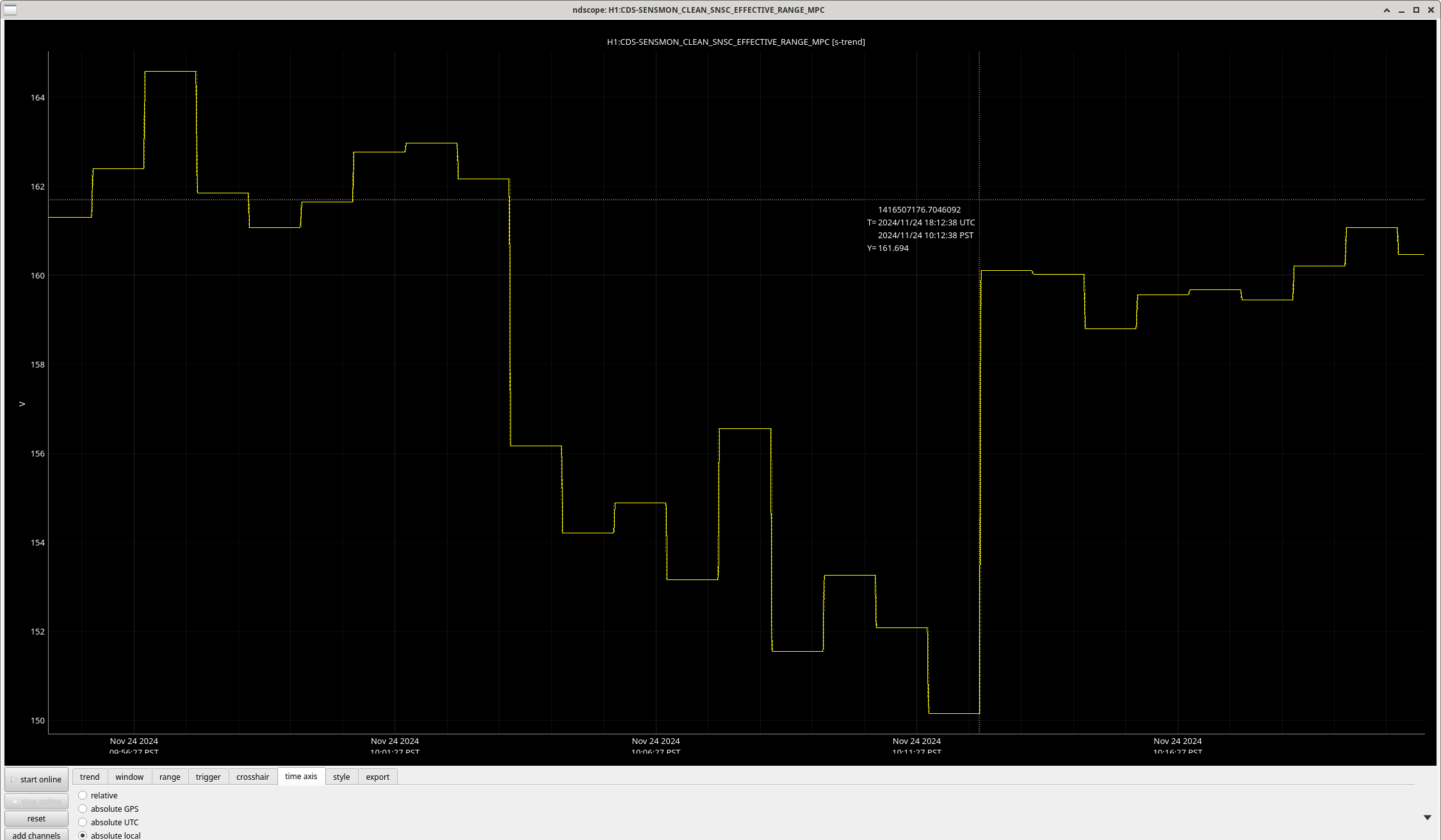
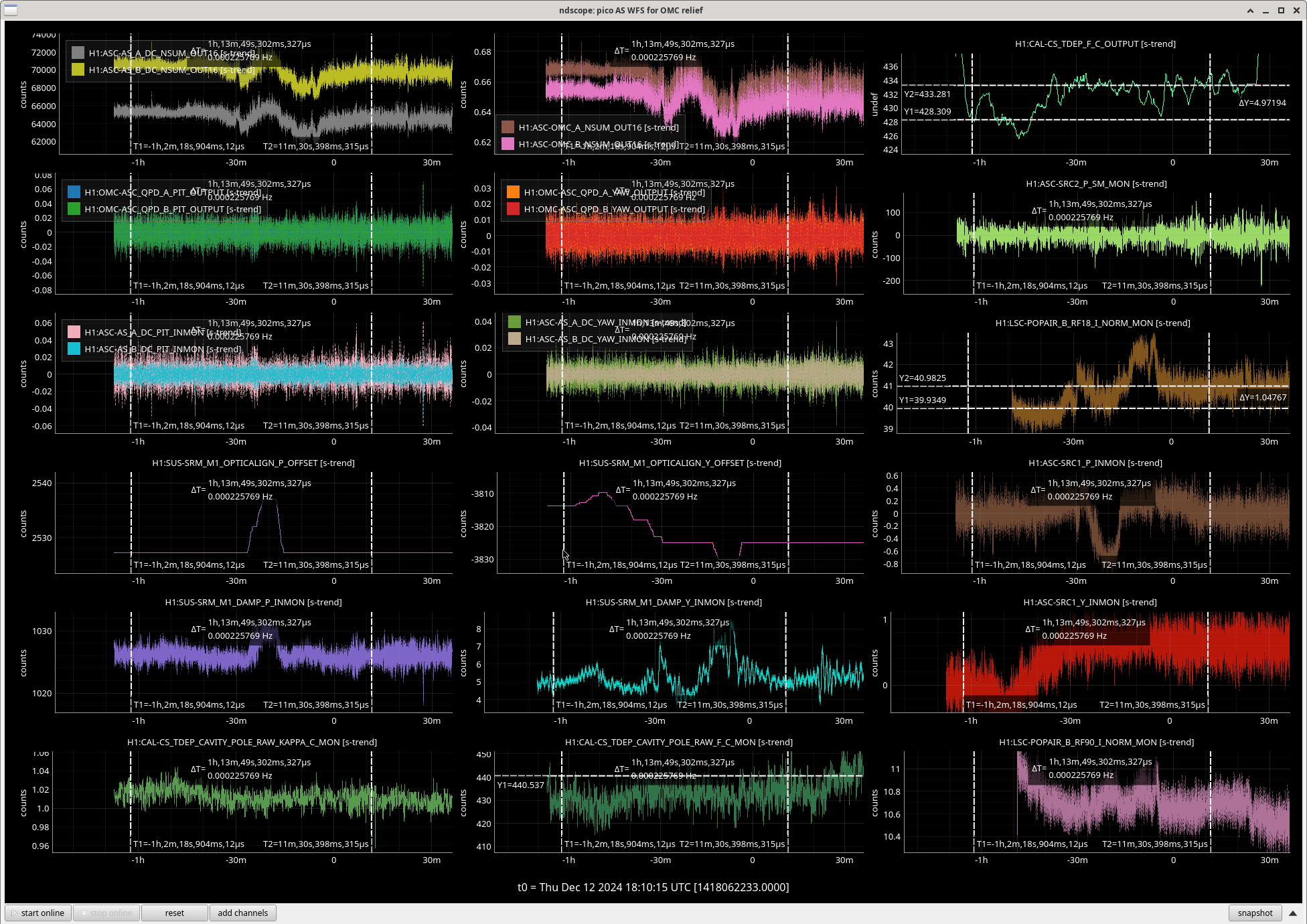
We repeated the setup in 81575, turned off SRCL LSC offset, opened the POP beam divertor, turned off SRCL1 ASC loops and then moved SRM in pitch and Yaw (0.1urad steps in groups of 5urad). Saw no change in pitch but an offset in yaw improved the FCC (but decreased KappaC). Could see ASC-OMC_NSUM's changing so we may need to update OMC offsets too. could see RF18 increase. FCC (couple cavity pole) increased 4.5Hz. Plots here and here.
Added a -0.62 offset into SRC1 (need to put into ISC_LOCK / sdf / lscparms). Then turned back on SRC1 ASC (ramp time 0.1s turned on offset and on button at same time).
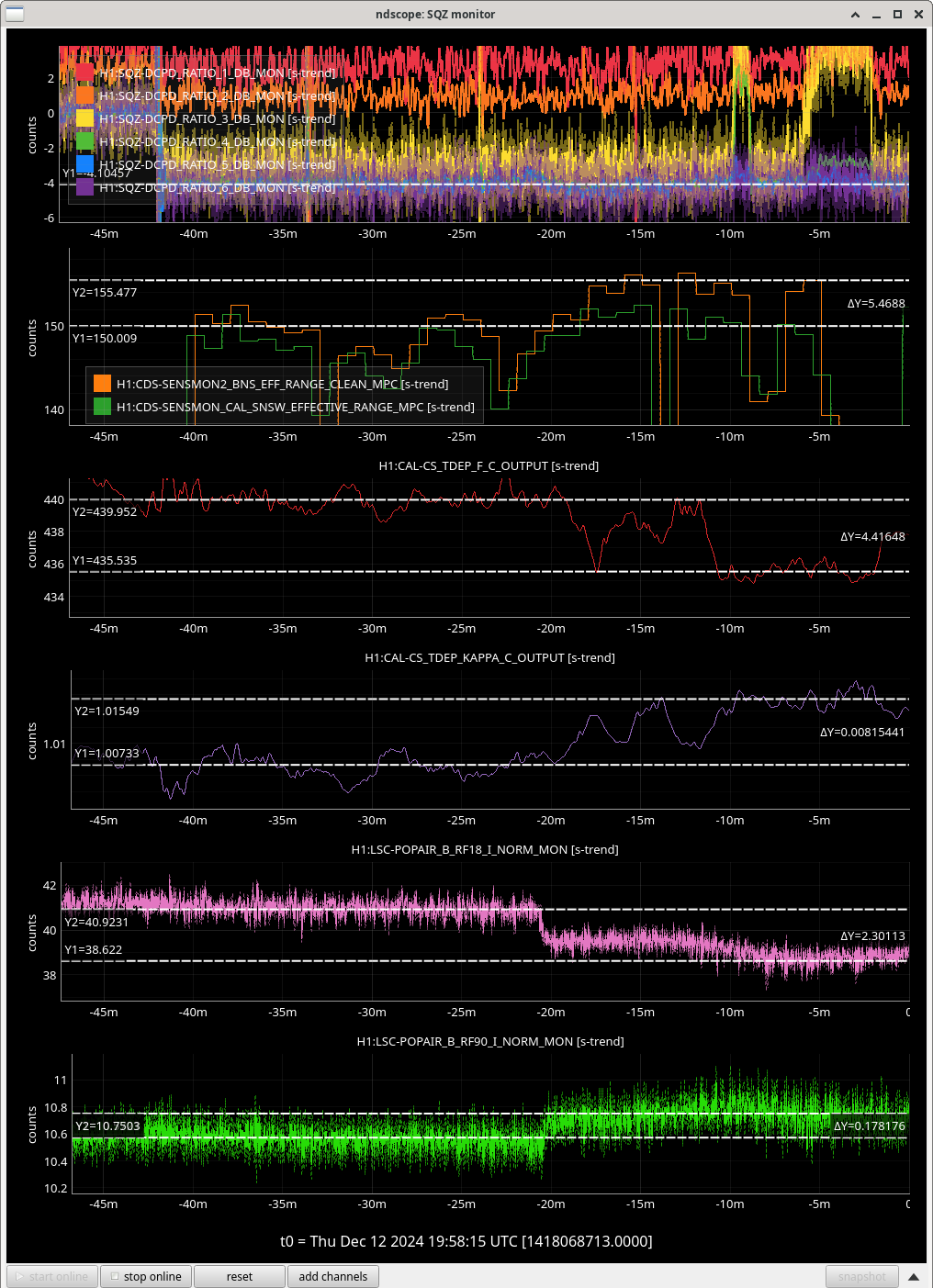
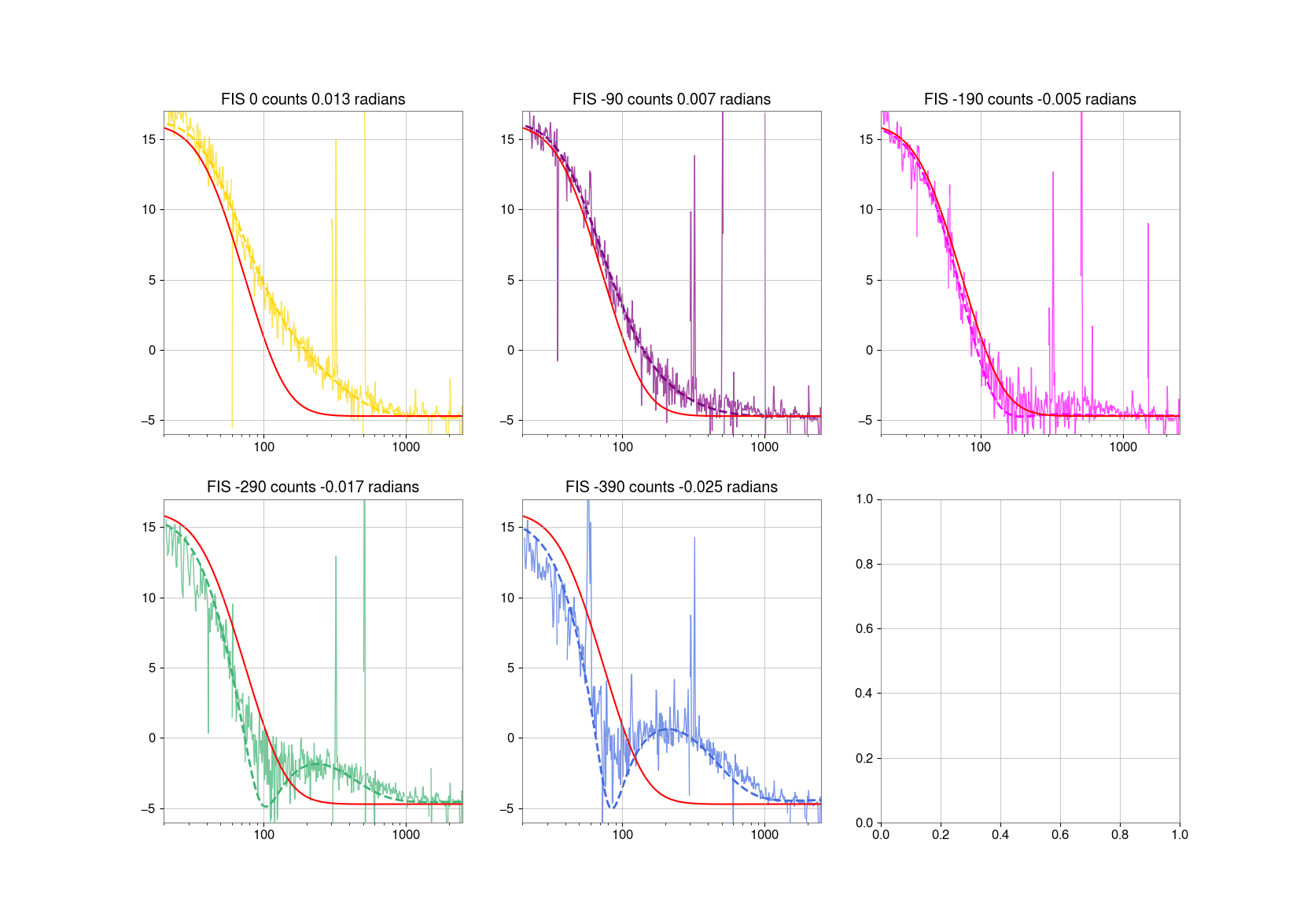
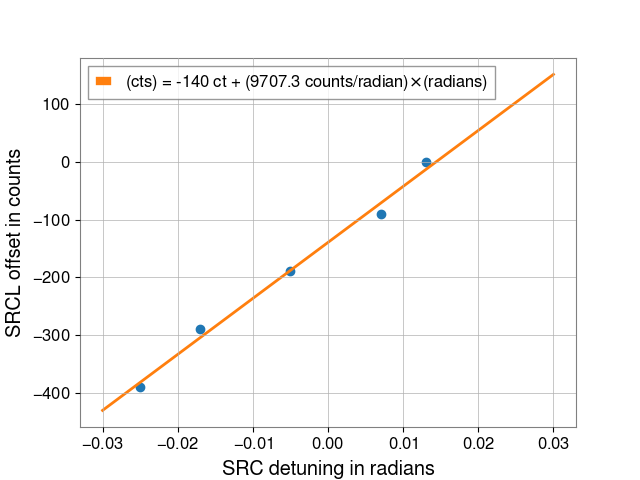
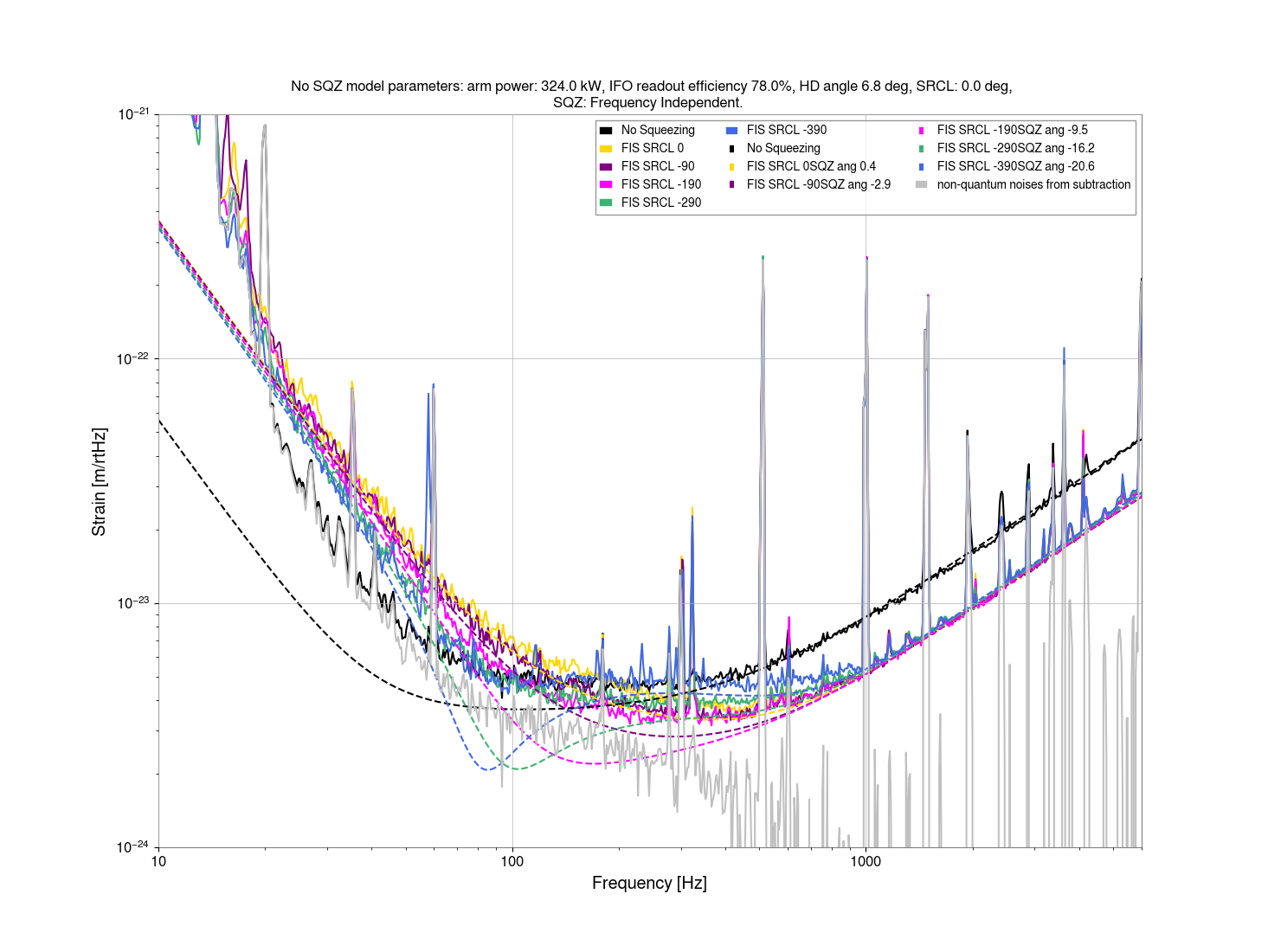
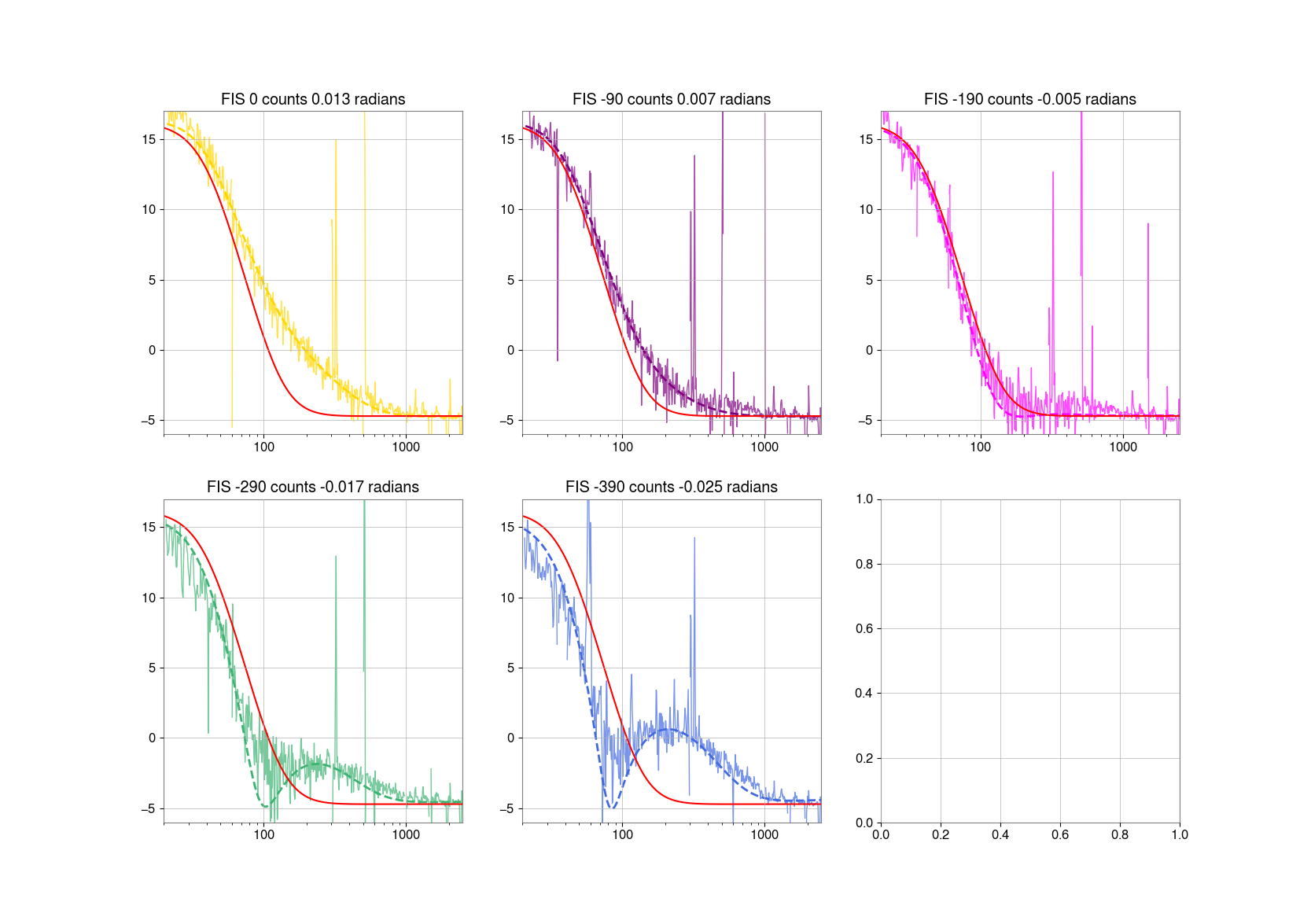
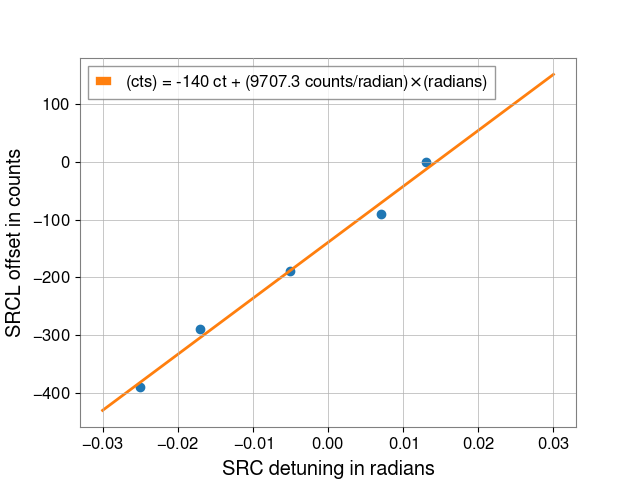
Repeated SQZ FIS vs SRCL de-tuning dataset from 80318, this gave us the SRCL offset of -140 to use:
- 18:12:30 - 18:21:00 UTC: No Squeezing ref0
- 18:29:30 - 18:33:00 FIS 0 deg SRCL offset (phase 133deg) ref1
- 18:36:00 -18:38:30 FIS -90 deg SRCL offset (phase 156deg) ref2
- 18:41:30 - 18:44:00 FIS -190 deg SRCL offset (phase deg186) ref3
- 18:52:15 - 18:54:30 FIS -290 deg SRCL offset (phase deg205) ref4
- 18:57:00 - 19:00:00 FIS -390 deg SRCL offset (phase deg219) ref5
Outputs from Sheila's 80318 code attached: DARM spectra, fitted SRCL de-tuning to model, offset fit that gave us -140.
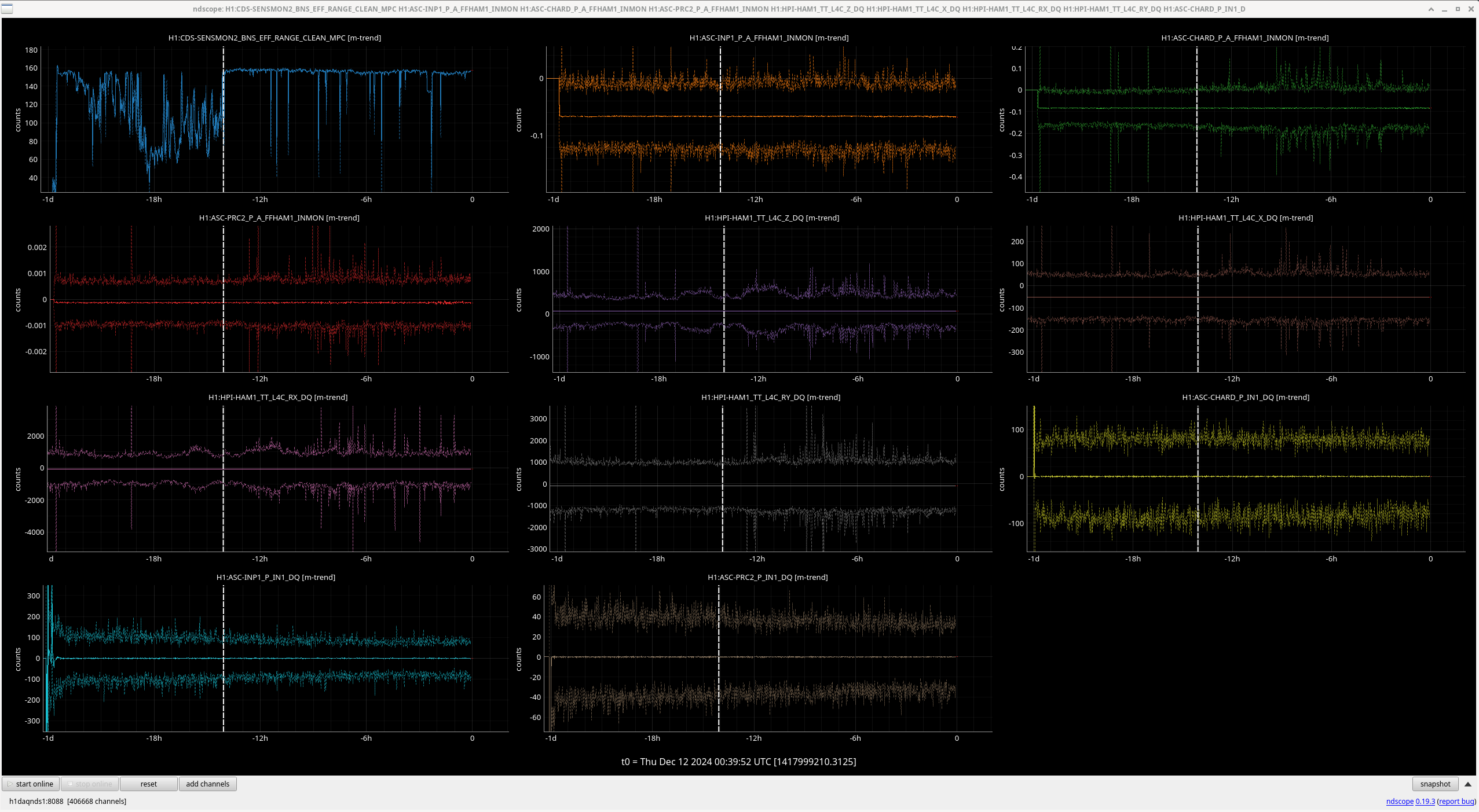
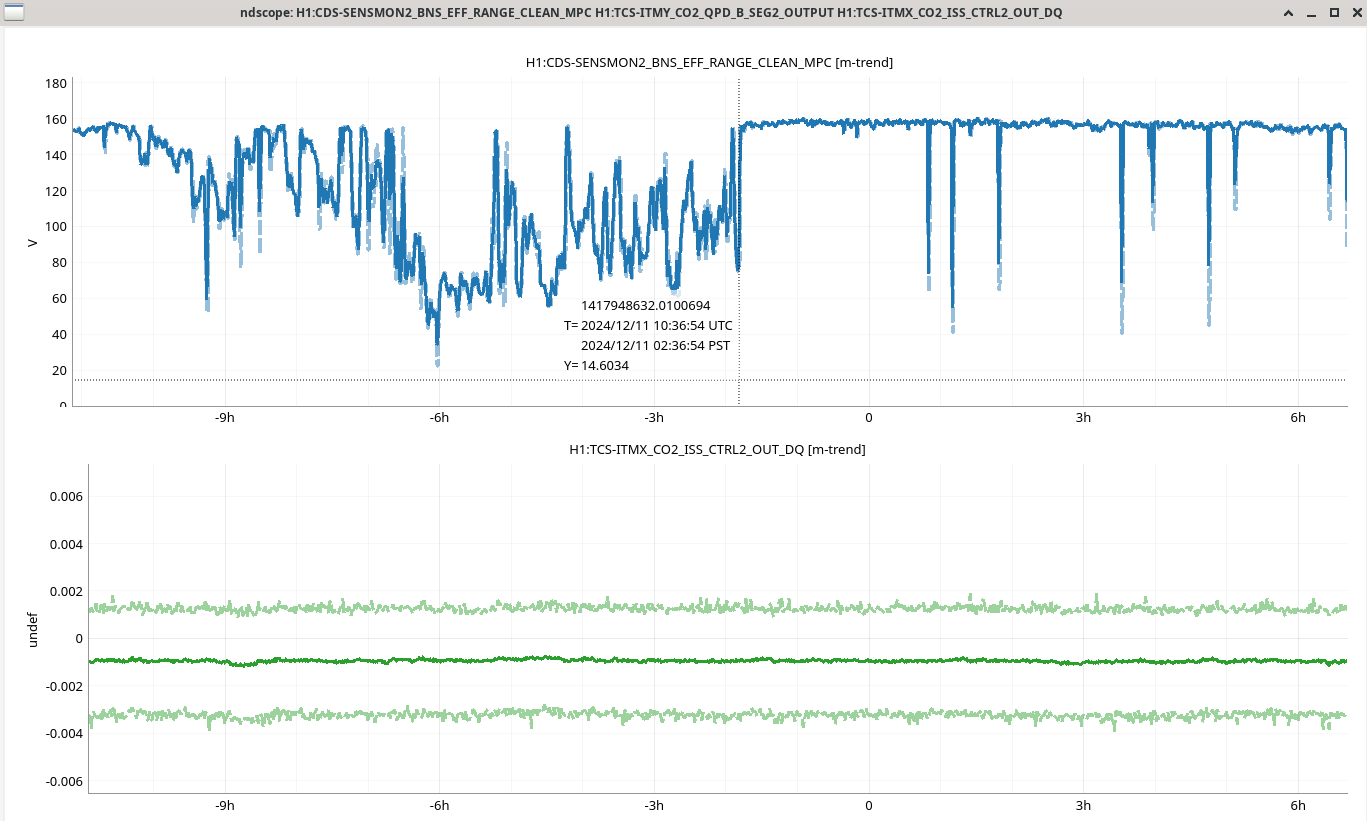
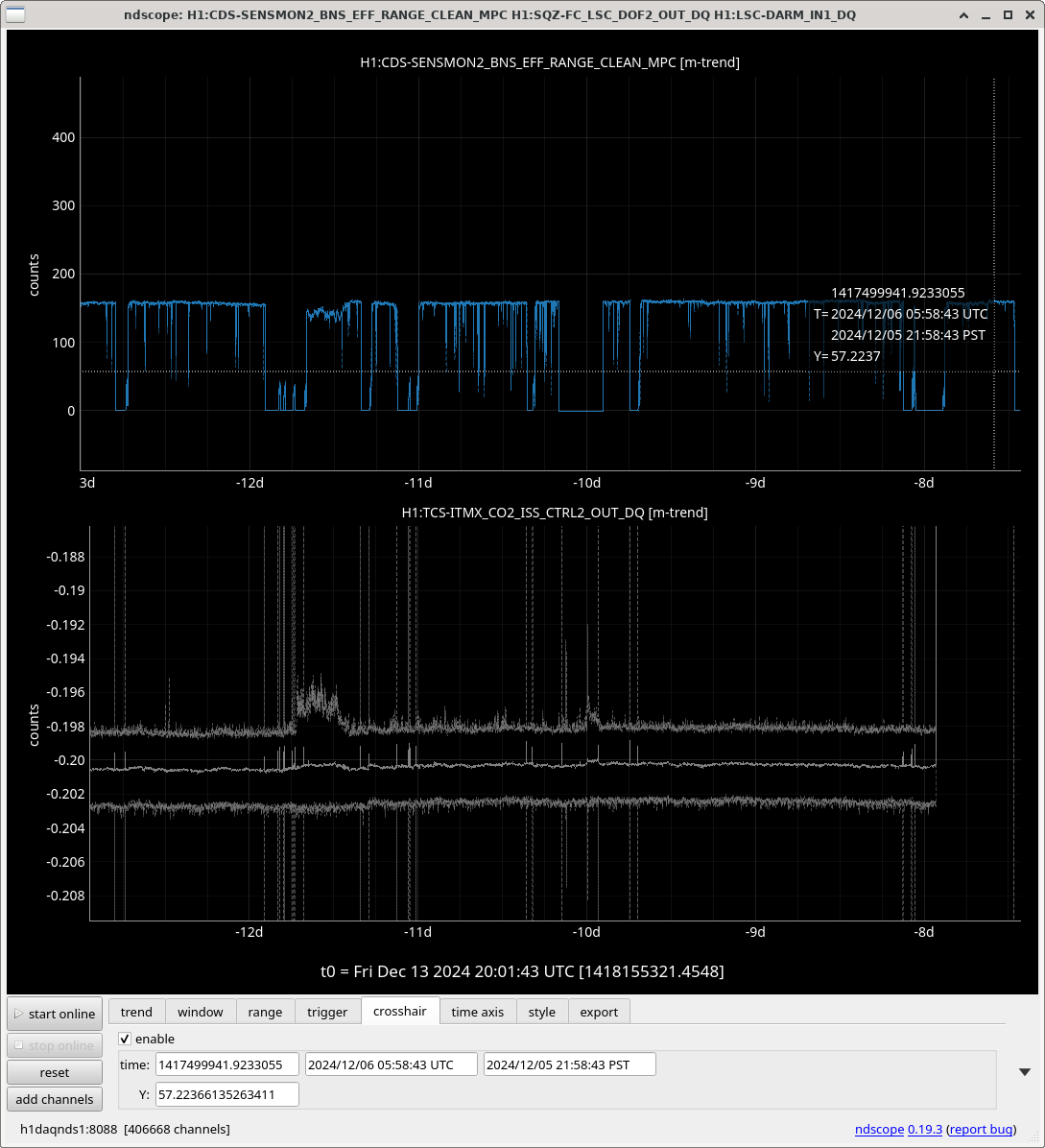
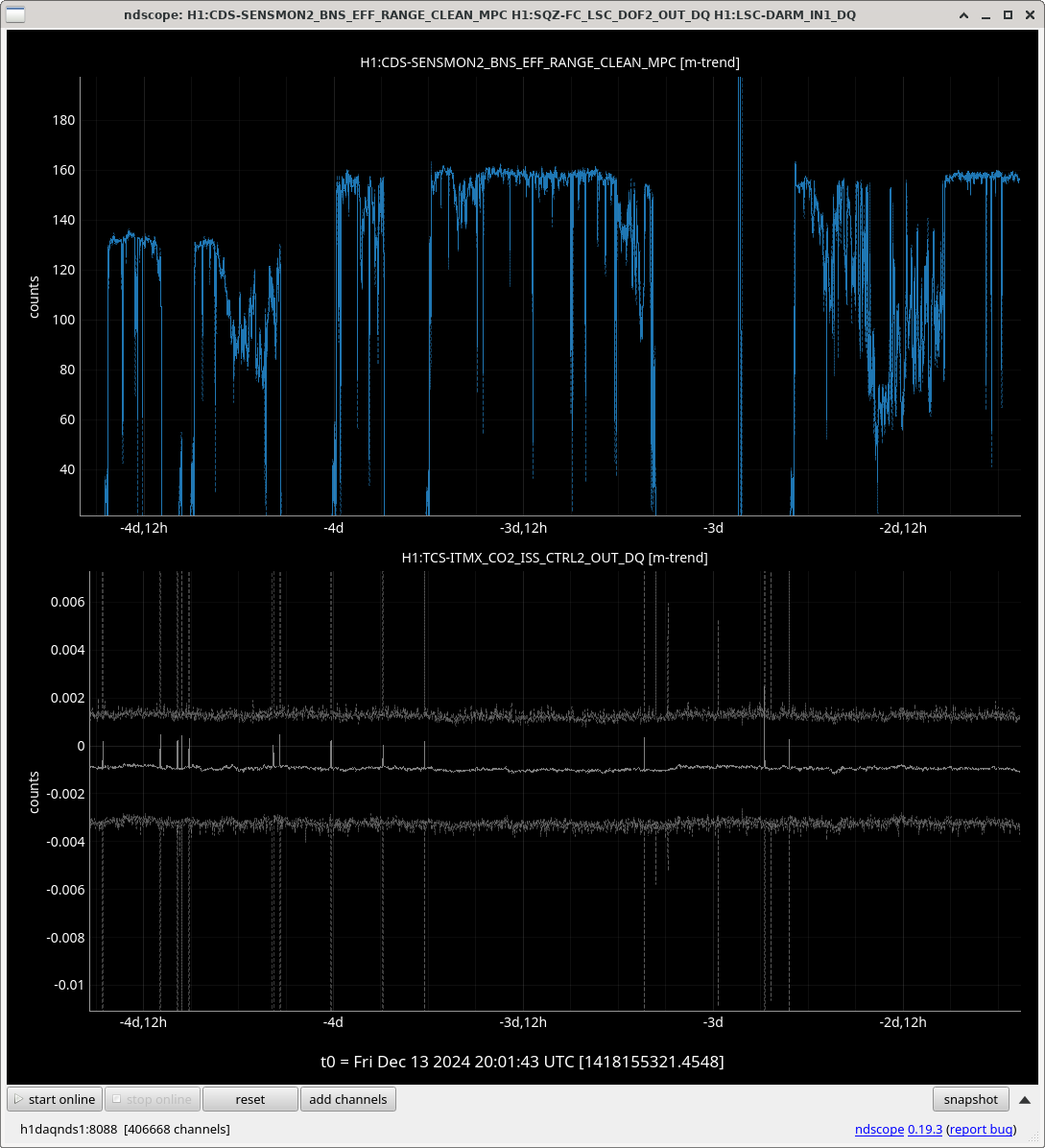
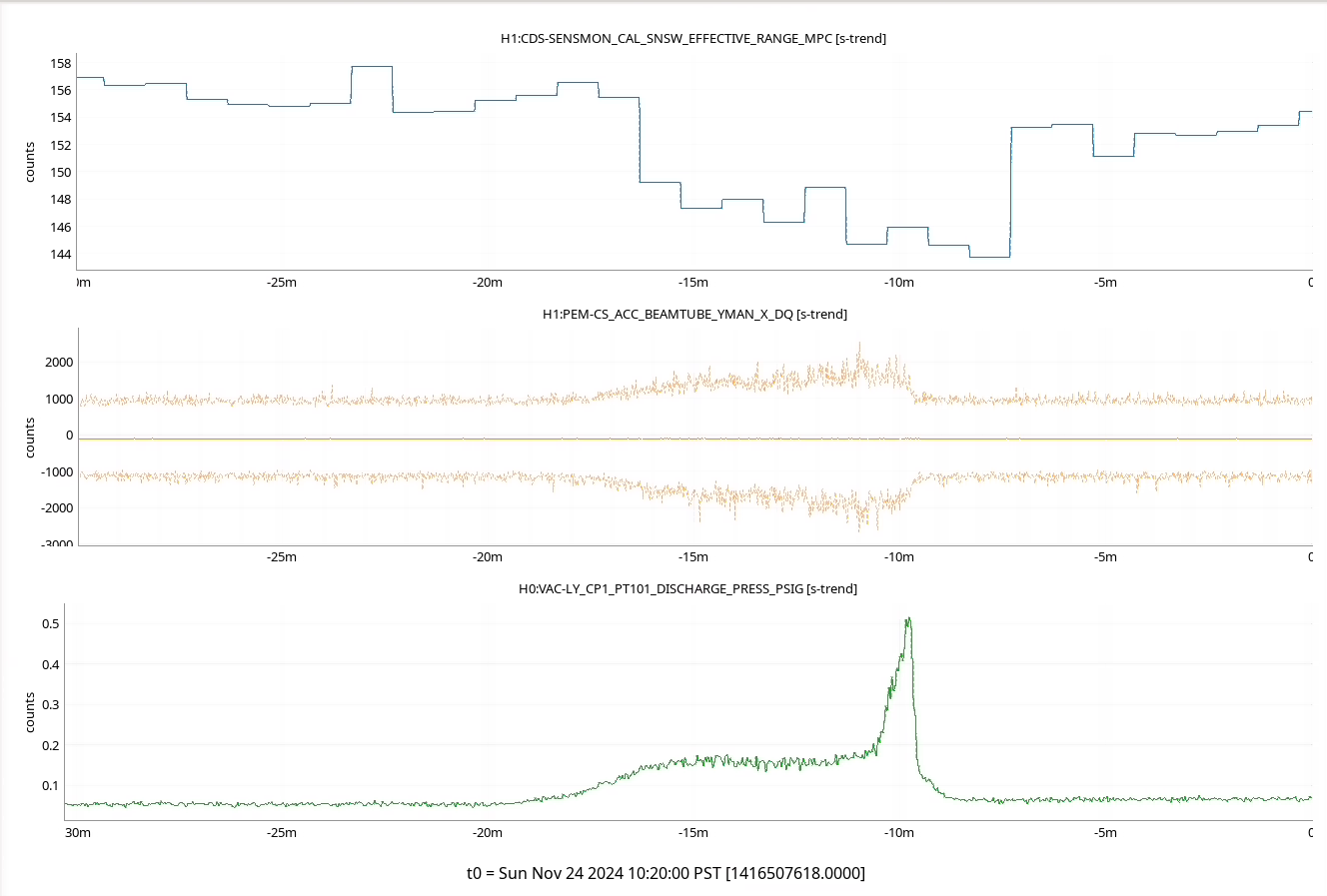
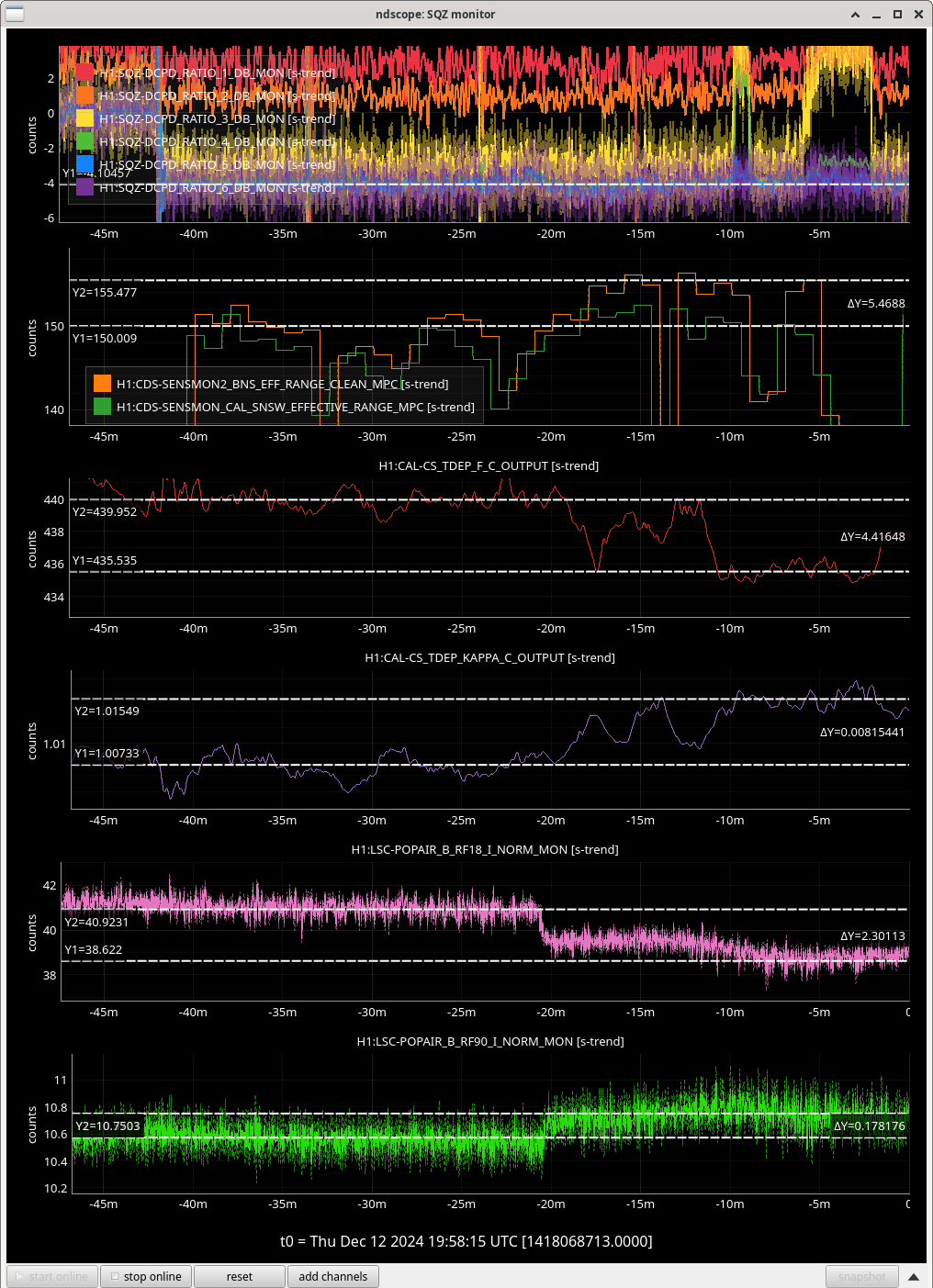
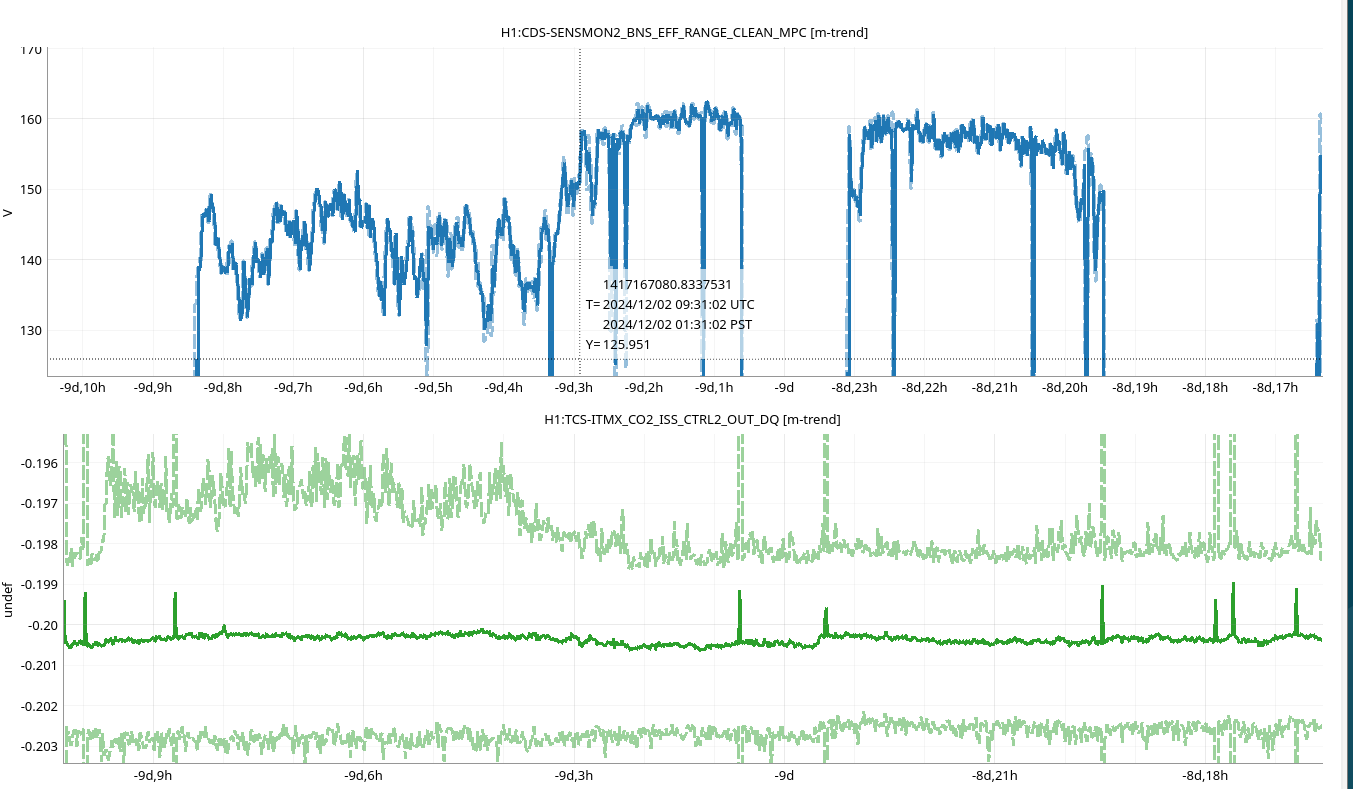
Once we reverted the changes, you can see here that the: range increased 5MPc, FCC decreased 4.4Hz, kappaC increased 0.8%, RF18 decreased, RF90 increased.
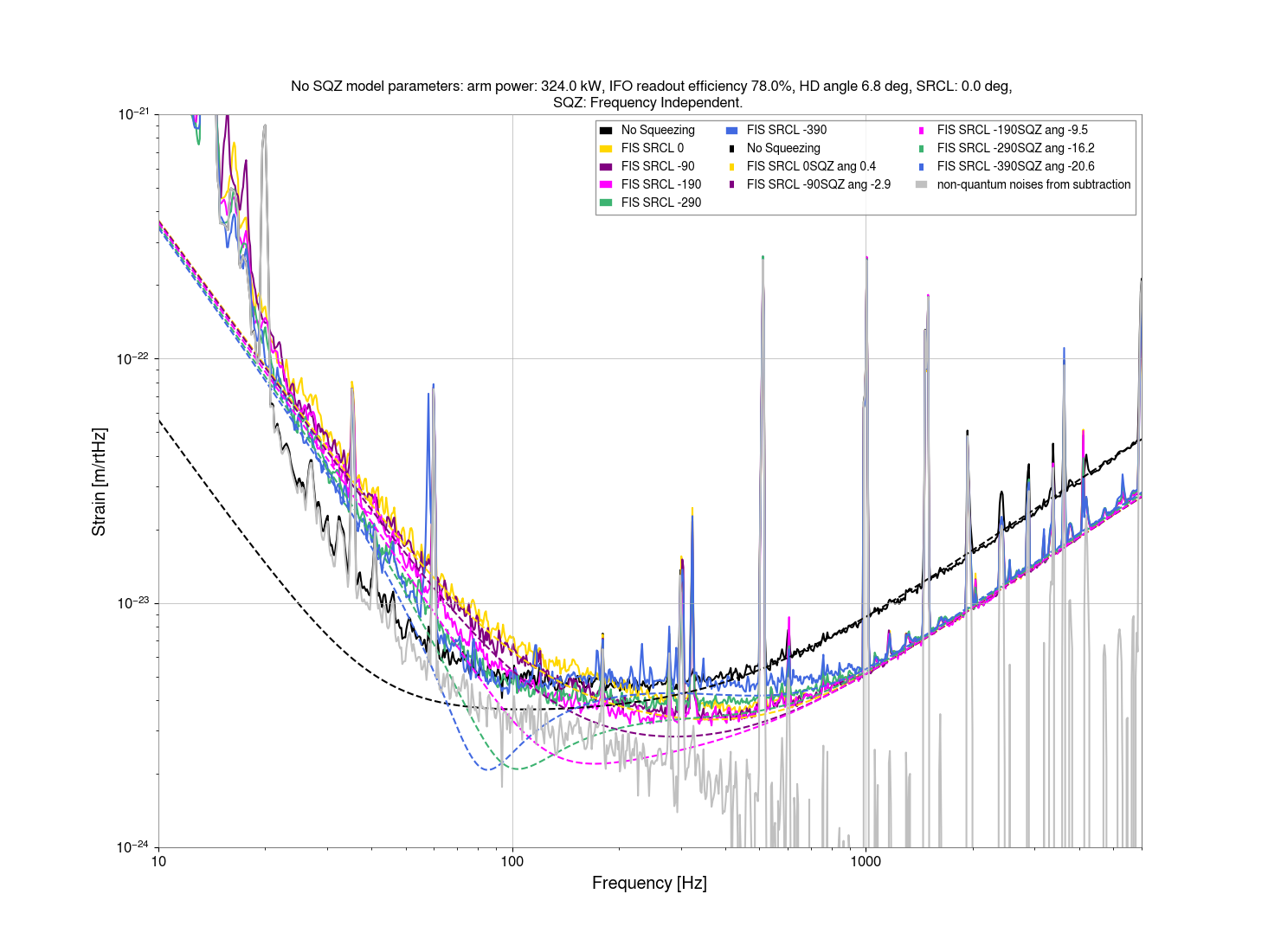
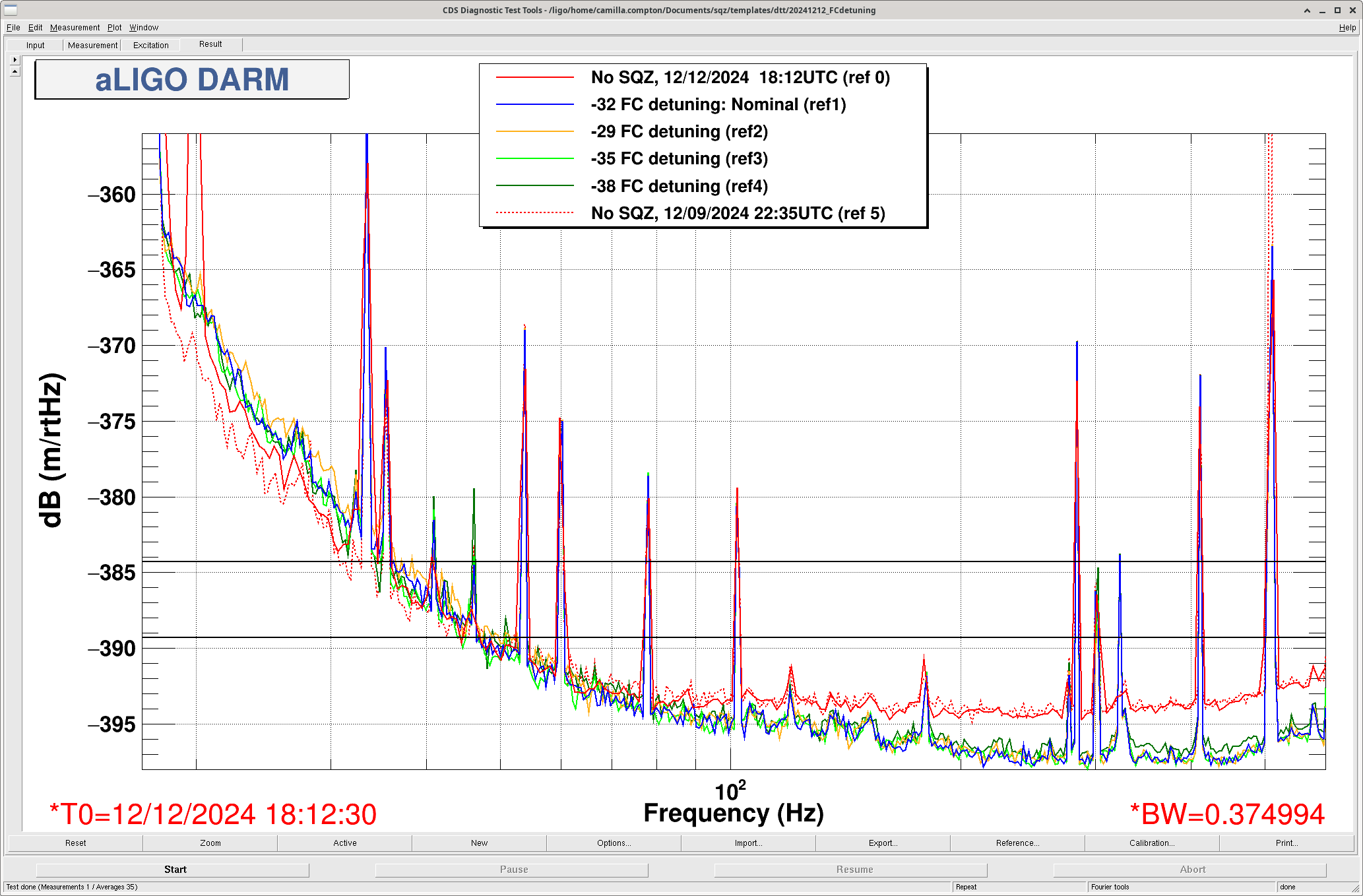
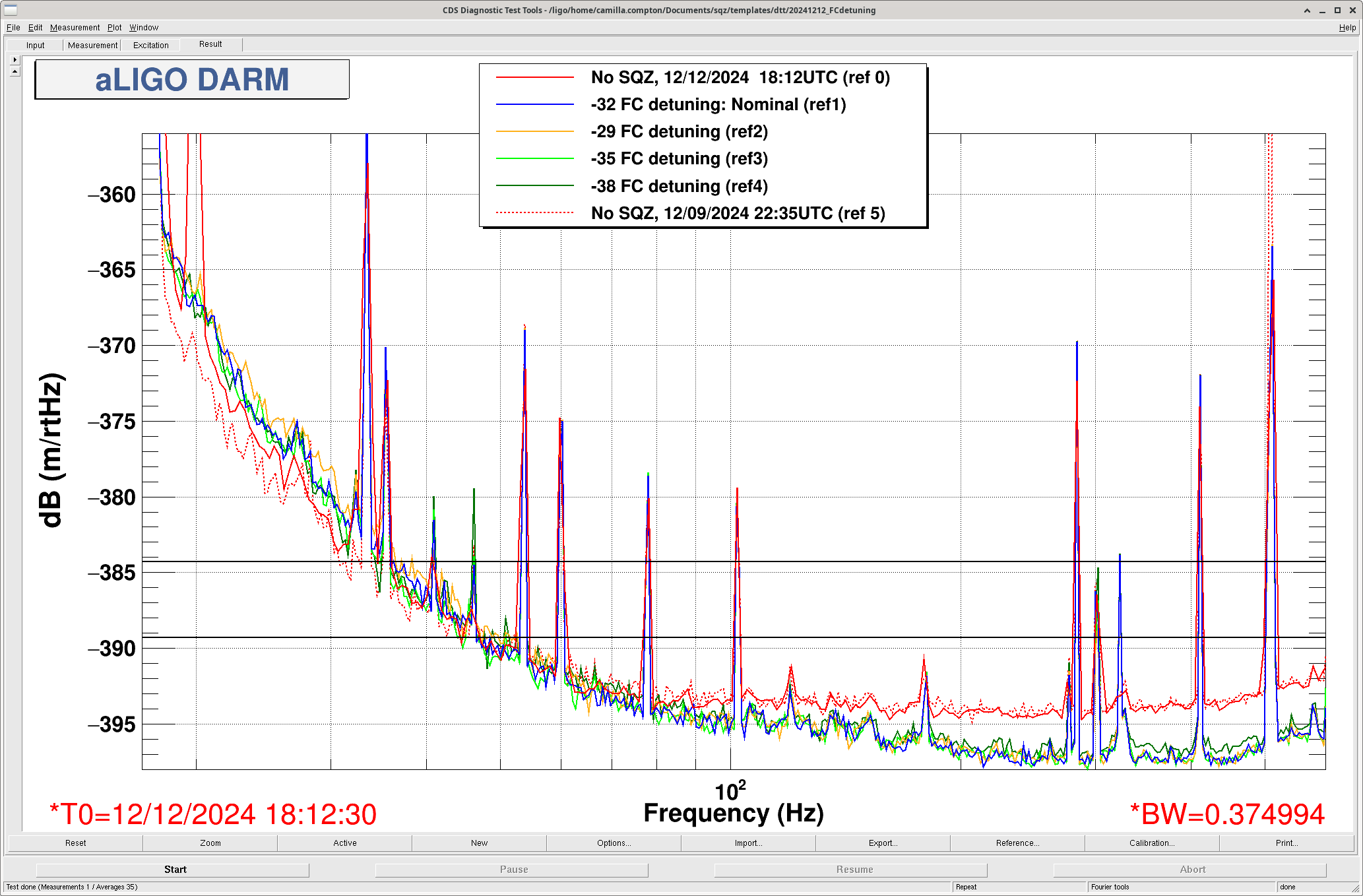
While we still had the SRCL ASC and LSC offsets in place, I tried some different FC de-tuning values from -29 to -38 (nominal is -32) 0.1Hz 50% overlap 35 average for 3minutes of data each. -35 is maybe the best FC de-tuning though there isn't much of a difference. The most interesting is that the no SQZ time is considerably worse <40Hz than the no SQZ data on 12/9 (IFO locked 2hrs) with the original SRCL offsets. Plot attached.
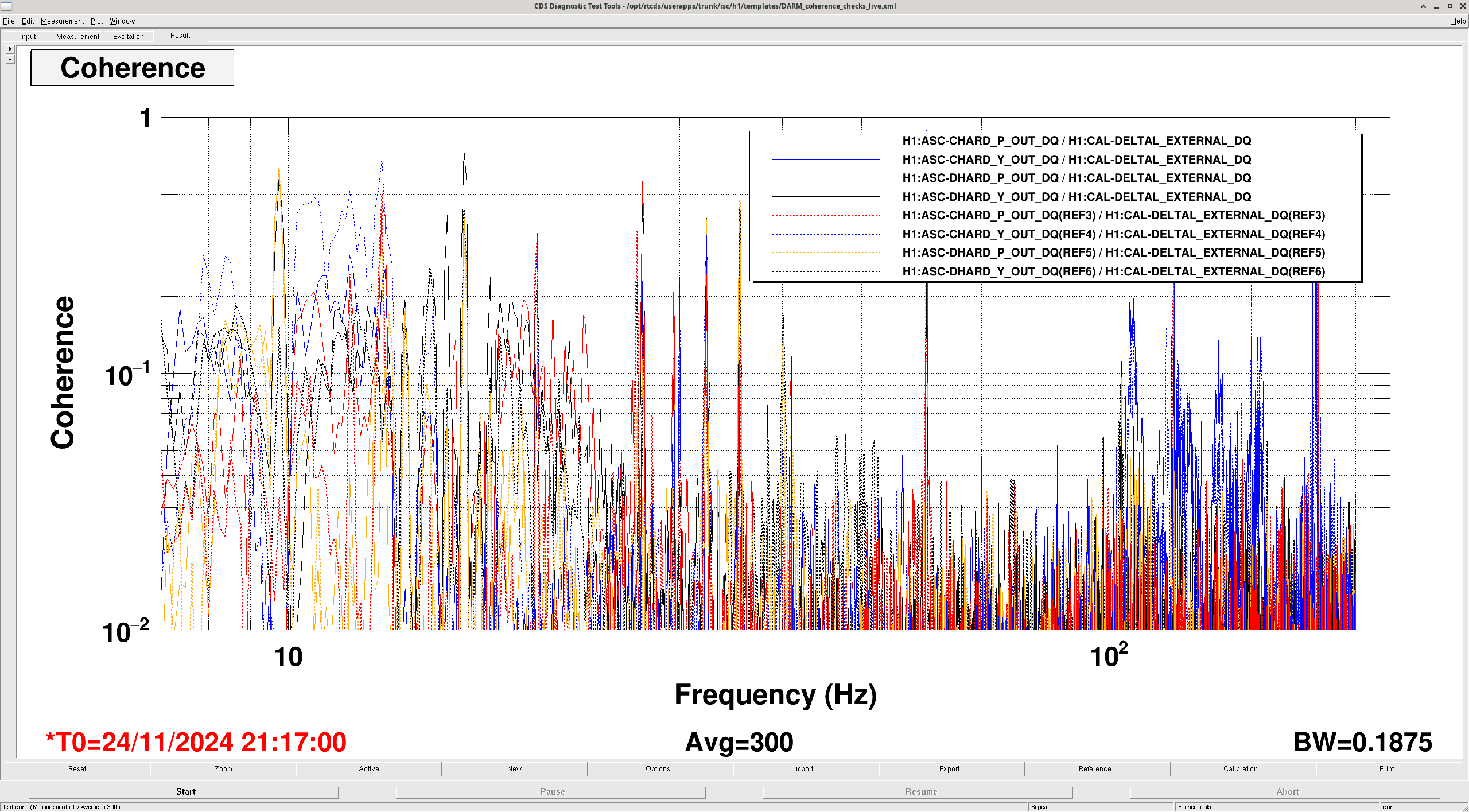
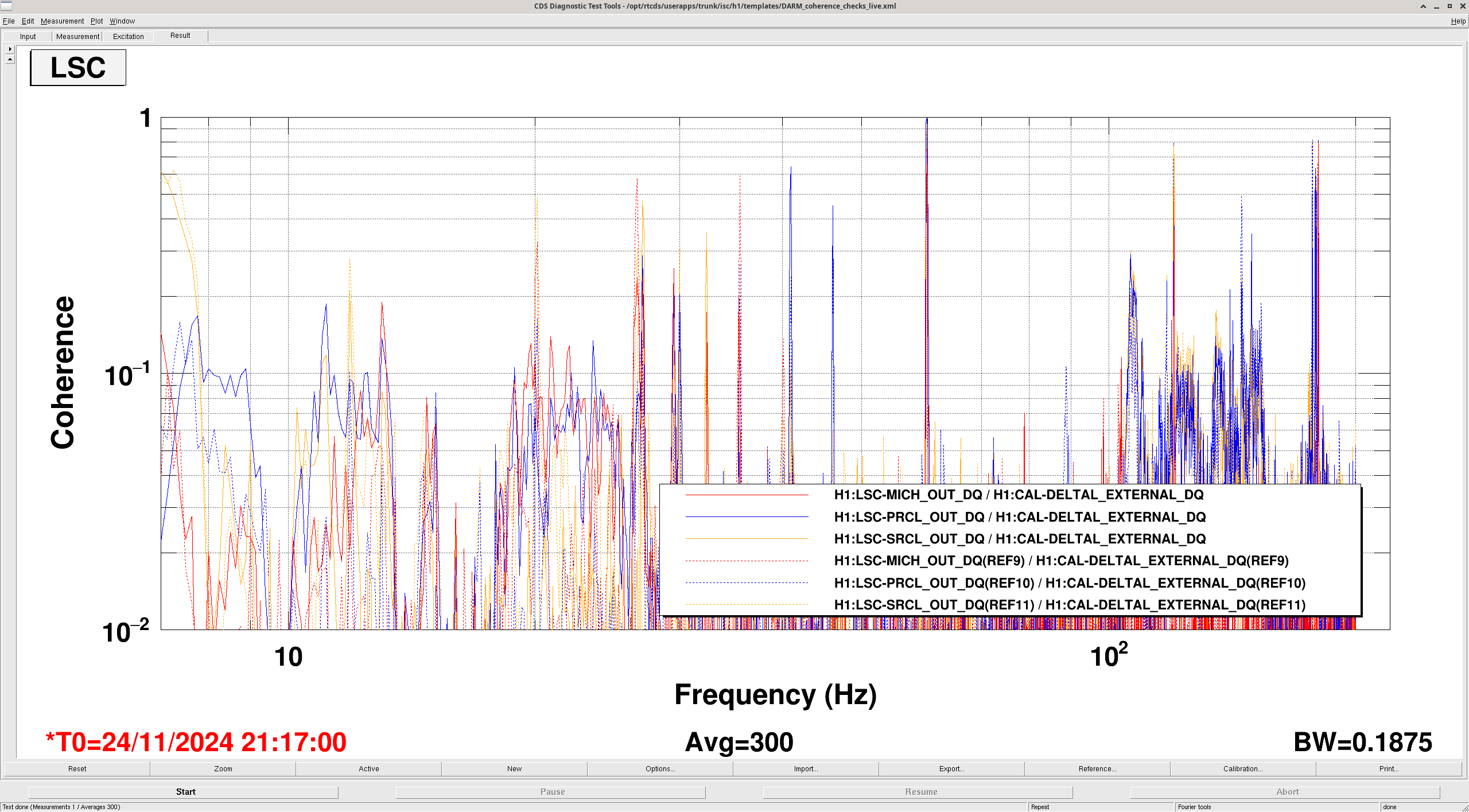
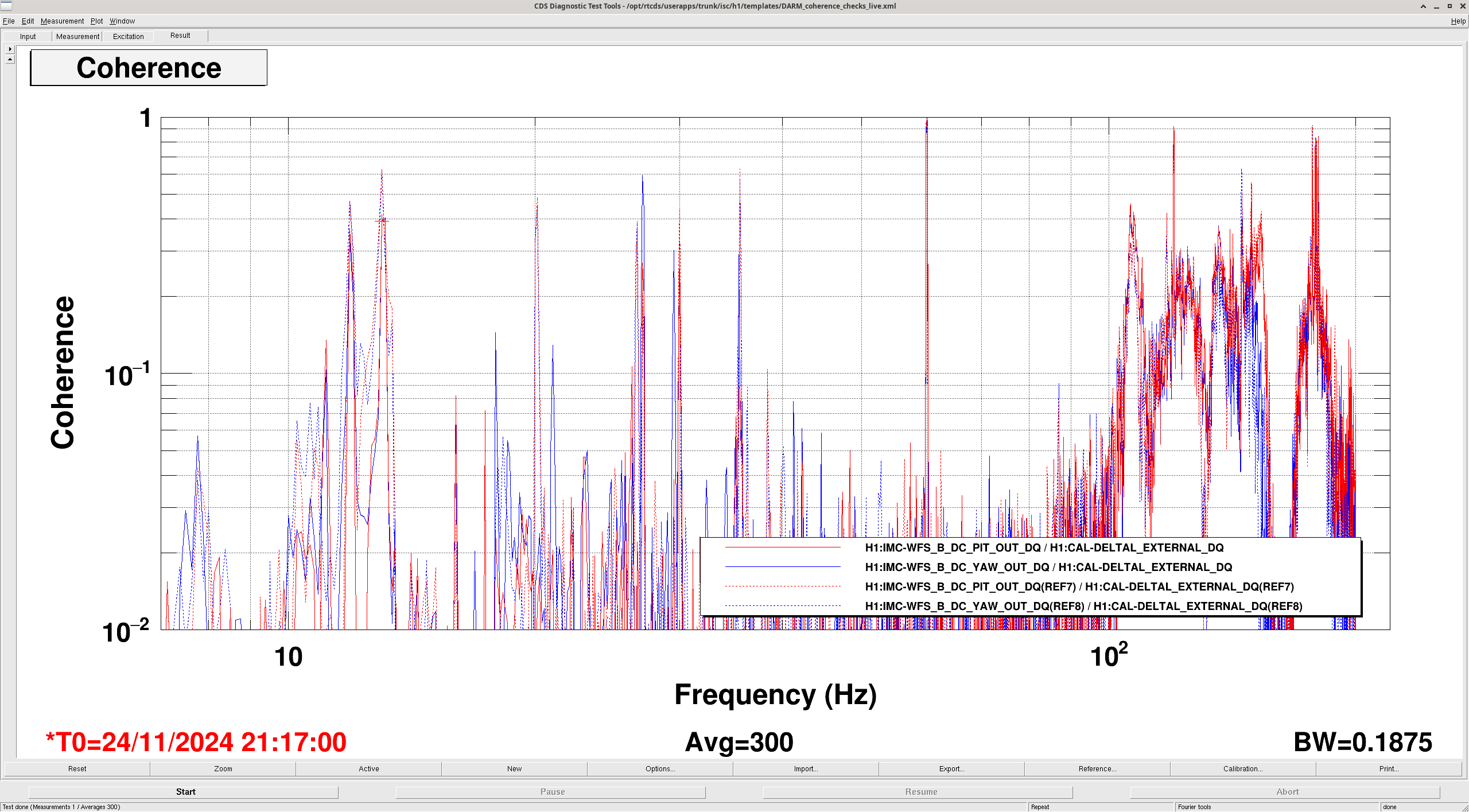
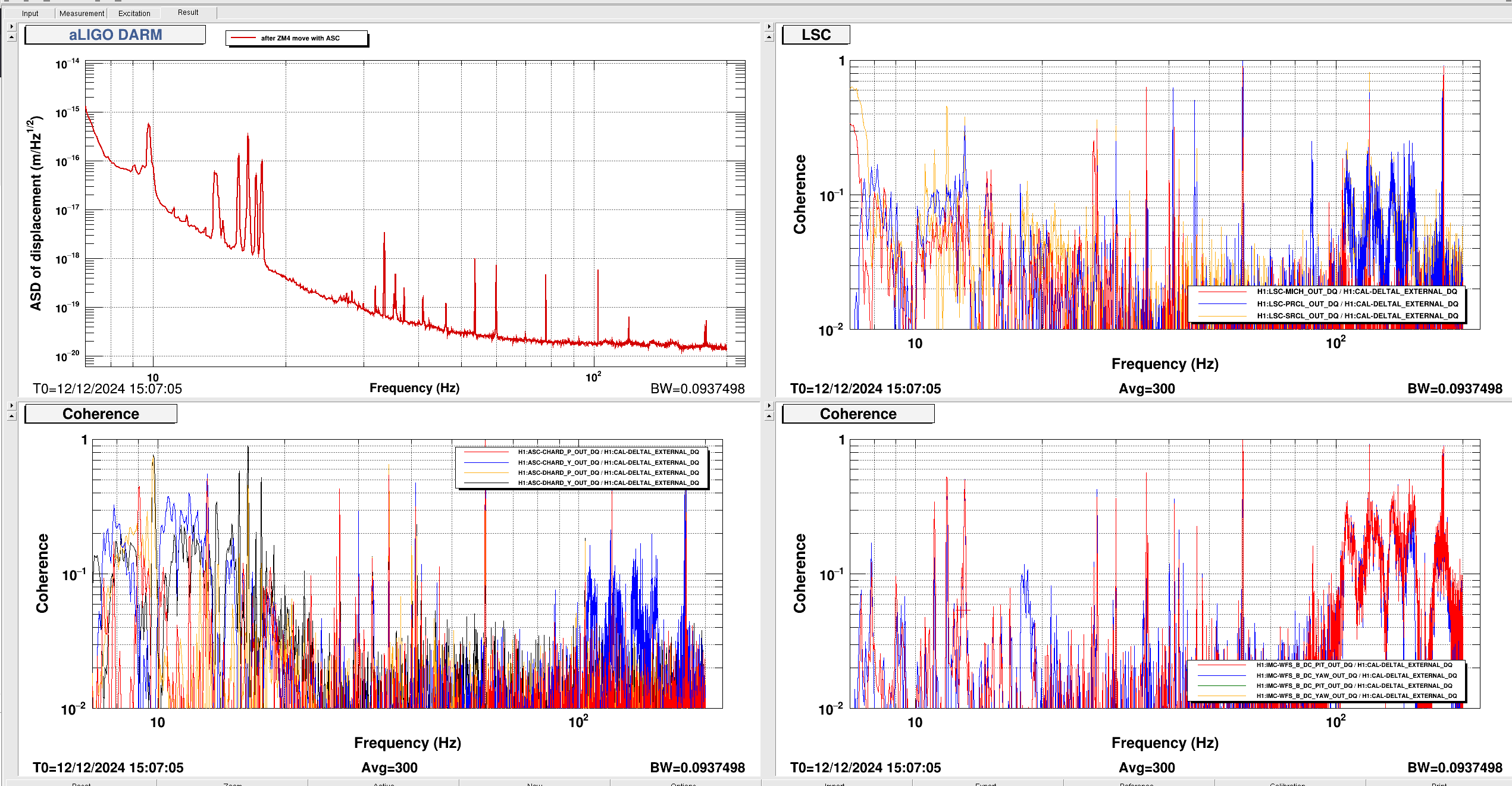
I took a quick look at the LSC coherence (MICH/PRCL/SRCL) during this change to see if it changed and that explained the worse noise. There is no change in the coherence. I also tried running a nonsens subtraction of the LSC channels on CALIB STRAIN and there was nothing of worth to subtract. Safe to say that these changes today in SRCL detuning do not worsen the LSC coupling.
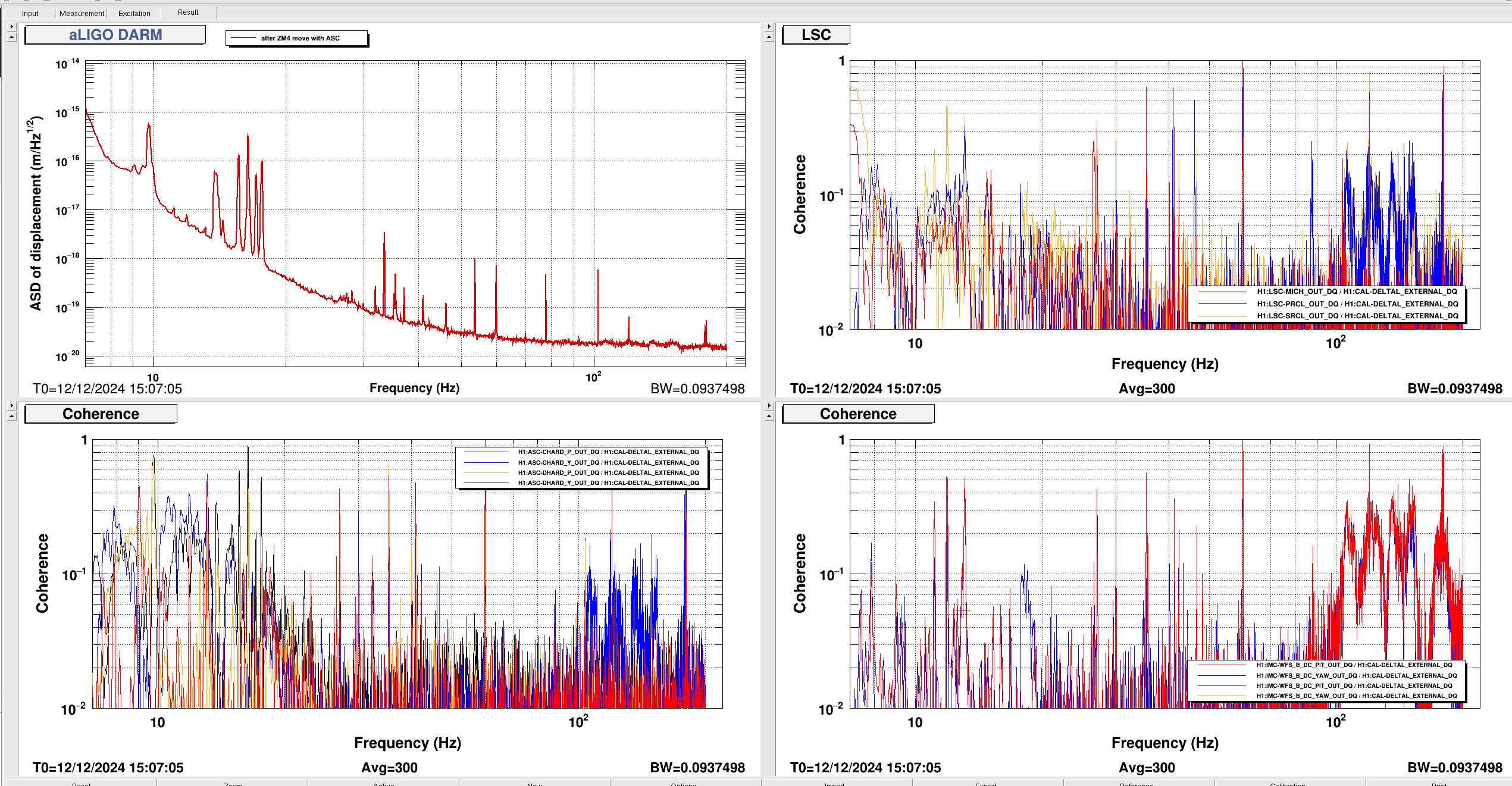

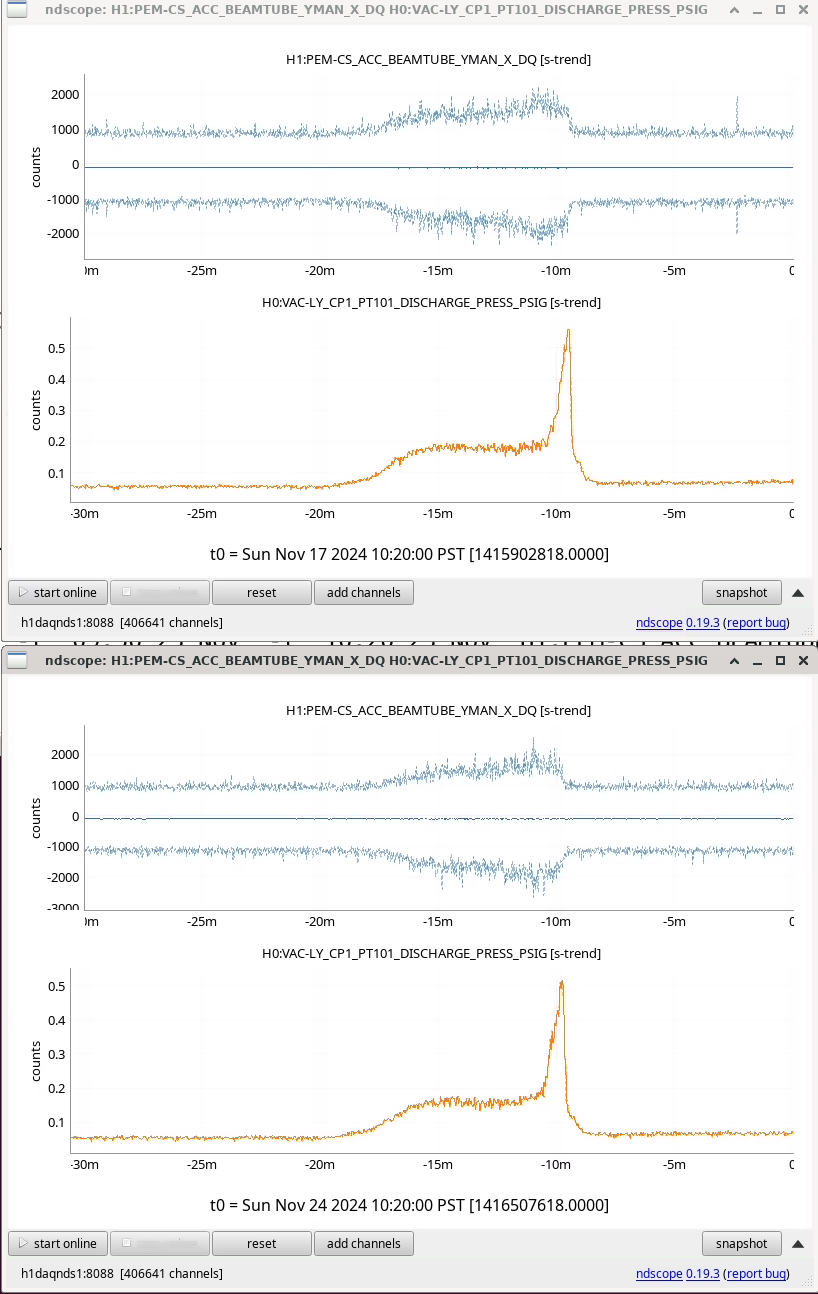
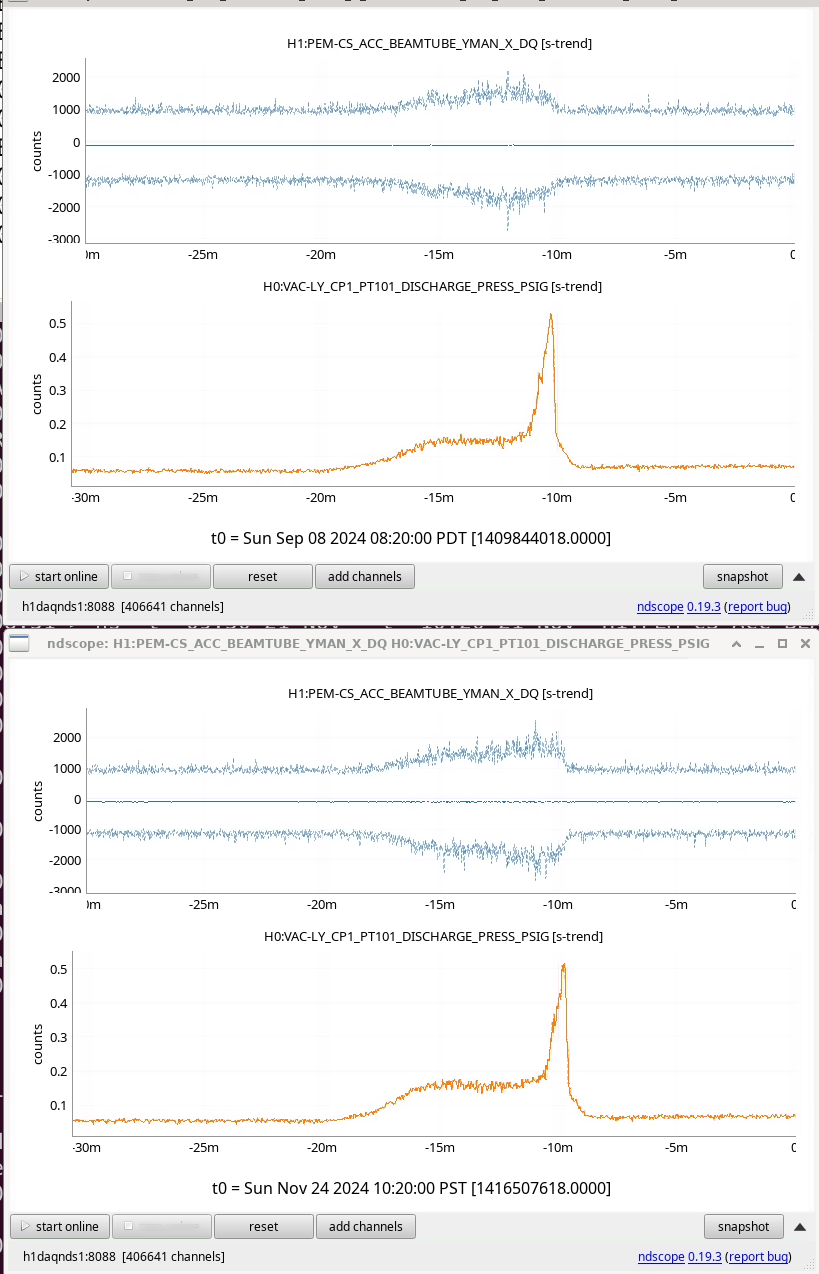
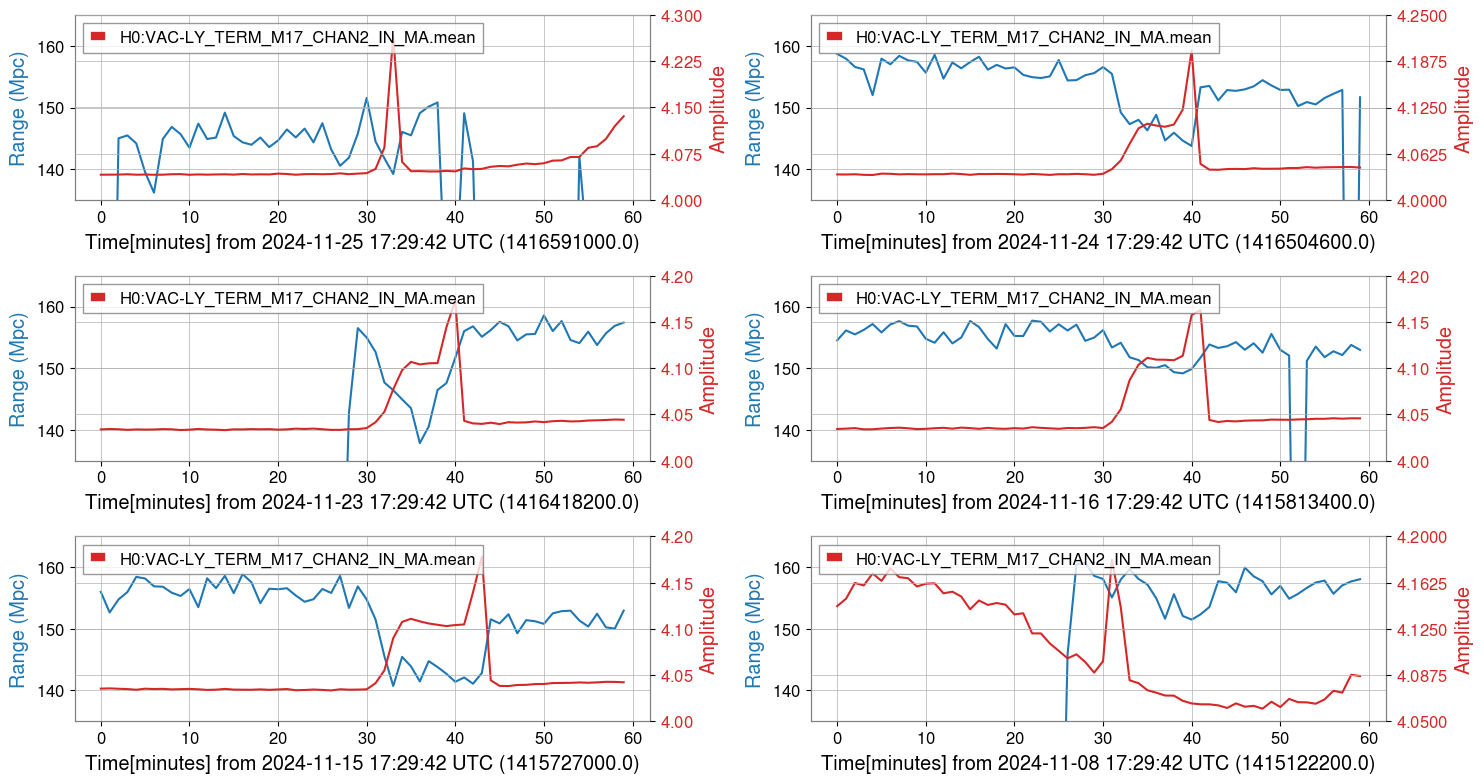
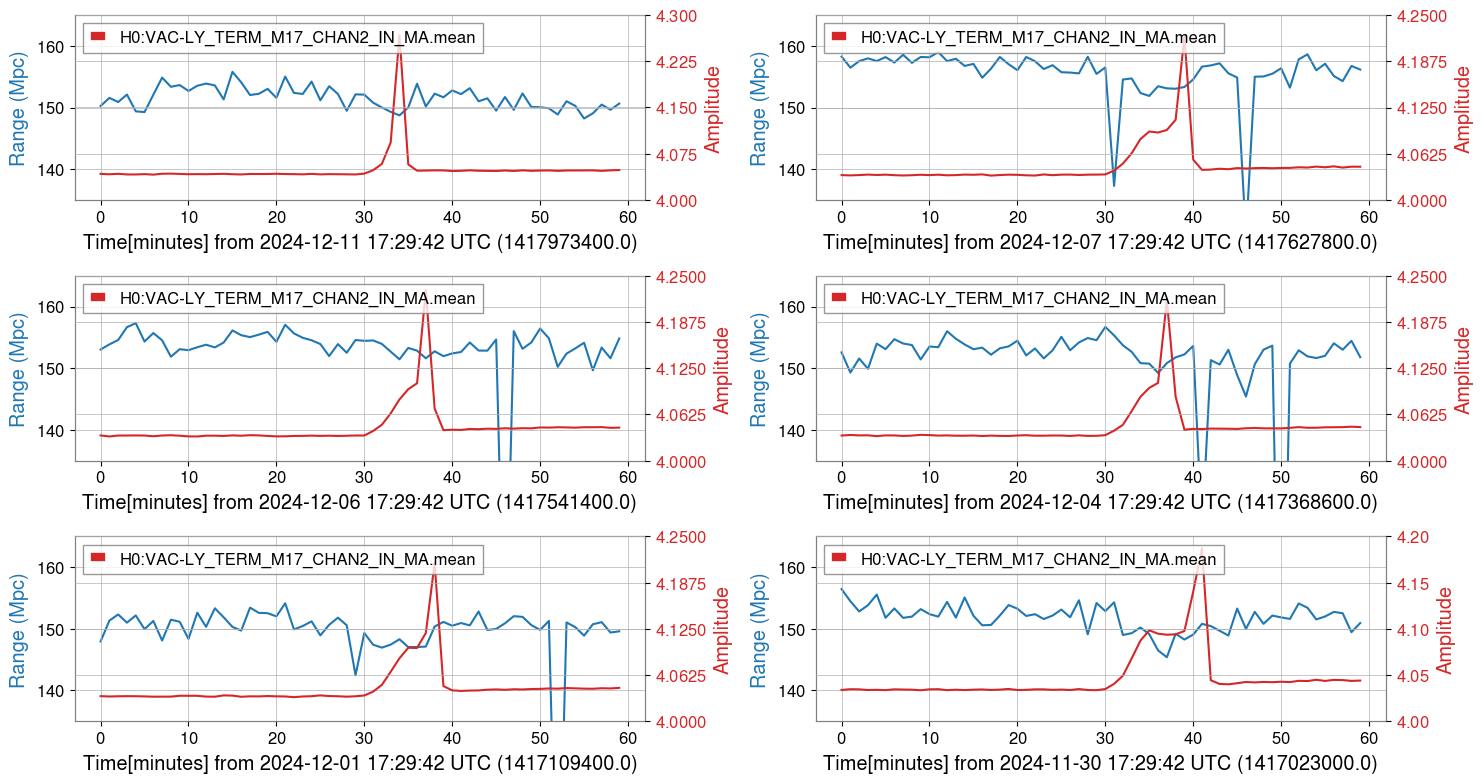
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}