PCAL team went to End Y today with PS4 to do a regular measurement and a "long measurement consisting of 15 minutes of time in each position instead of 240 seconds".
PS4 rho, kappa, u_rel on 2024-10-25 corrected to ES temperature 299.3 K : -4.71053733727373 -0.0002694340454223 4.653616030093759e-05
Copying the scripts into tD directory...
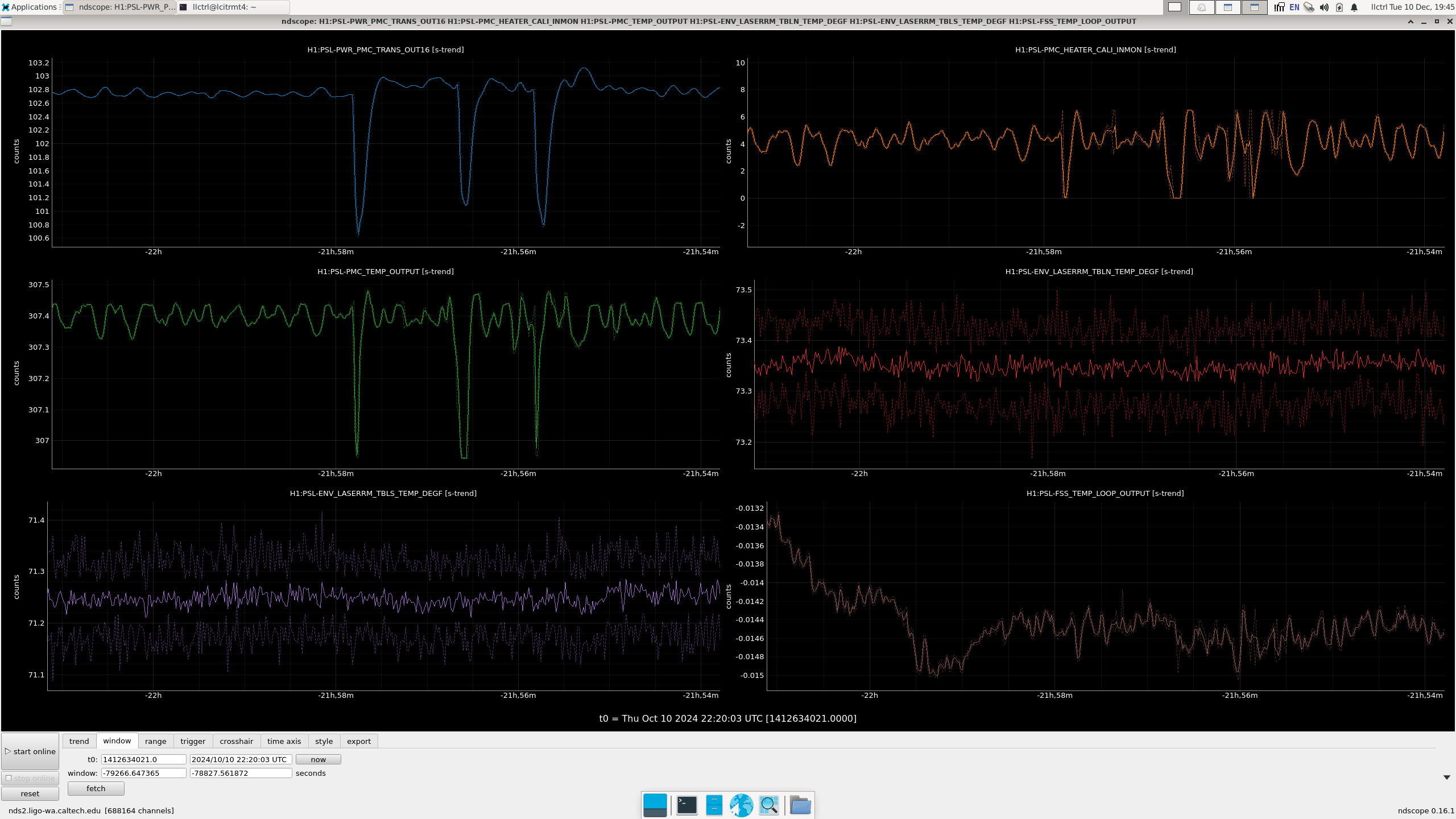
Connected to nds.ligo-wa.caltech.edu
martel run
reading data at start_time: 1417885234
reading data at start_time: 1417885750
reading data at start_time: 1417886151
reading data at start_time: 1417886600
reading data at start_time: 1417886970
reading data at start_time: 1417887305
reading data at start_time: 1417887420
reading data at start_time: 1417888020
reading data at start_time: 1417888356
Ratios: -0.5346804302935332 -0.543306389094602
writing nds2 data to files
finishing writing
Background Values:
bg1 = 18.604505; Background of TX when WS is at TX
bg2 = 5.391990; Background of WS when WS is at TX
bg3 = 18.556794; Background of TX when WS is at RX
bg4 = 5.396890; Background of WS when WS is at RX
bg5 = 18.642247; Background of TX
bg6 = -0.202112; Background of RX
The uncertainty reported below are Relative Standard Deviation in percent
Intermediate Ratios RatioWS_TX_it = -0.534680;
RatioWS_TX_ot = -0.543306;
RatioWS_TX_ir = -0.527163;
RatioWS_TX_or = -0.534899;
RatioWS_TX_it_unc = 0.055923;
RatioWS_TX_ot_unc = 0.051445;
RatioWS_TX_ir_unc = 0.062749;
RatioWS_TX_or_unc = 0.054710;
Optical Efficiency
OE_Inner_beam = 0.986010;
OE_Outer_beam = 0.984479;
Weighted_Optical_Efficiency = 0.985245;
OE_Inner_beam_unc = 0.044504;
OE_Outer_beam_unc = 0.041112;
Weighted_Optical_Efficiency_unc = 0.060587;
Martel Voltage fit:
Gradient = 1637.914766;
Intercept = 0.150812;
Power Imbalance = 0.984123;
Endstation Power sensors to WS ratios::
Ratio_WS_TX = -0.927655;
Ratio_WS_RX = -1.384163;
Ratio_WS_TX_unc = 0.044122;
Ratio_WS_RX_unc = 0.042178;
=============================================================
============= Values for Force Coefficients =================
=============================================================
Key Pcal Values : GS = -5.135100; Gold Standard Value in (V/W)
WS = -4.710537; Working Standard Value
costheta = 0.988362; Angle of incidence
c = 299792458.000000; Speed of Light
End Station Values : /ligo/gitcommon/Calibration/pcal
TXWS = -0.927655; Tx to WS Rel responsivity (V/V)
sigma_TXWS = 0.000409; Uncertainity of Tx to WS Rel responsivity (V/V)
RXWS = -1.384163; Rx to WS Rel responsivity (V/V)
sigma_RXWS = 0.000584; Uncertainity of Rx to WS Rel responsivity (V/V)
e = 0.985245; Optical Efficiency sigma_e = 0.000597; Uncertainity in Optical Efficiency
Martel Voltage fit :
Martel_gradient = 1637.914766;
Martel to output channel (C/V)
Martel_intercept = 0.150812;
Intercept of fit of Martel to output (C/V)
Power Loss Apportion : beta = 0.998844; Ratio between input and output (Beta)
E_T = 0.992021; TX Optical efficiency
sigma_E_T = 0.000301; Uncertainity in TX Optical efficiency
E_R = 0.993169; RX Optical Efficiency
sigma_E_R = 0.000301; Uncertainity in RX Optical efficiency
Force Coefficients :
FC_TxPD = 9.138978e-13; TxPD Force Coefficient
FC_RxPD = 6.216600e-13; RxPD Force Coefficient
sigma_FC_TxPD = 4.923605e-16; TxPD Force Coefficient
sigma_FC_RxPD = 3.250921e-16; RxPD Force Coefficient
data written to ../../measurements/LHO_EndY/tD20241210/
Before beam spot looking a little oblonged but not too bad.
Martel Voltage Test plots
WS_at_RX plots
WS at RX Side with Both Beams
WS at Transmitter Module
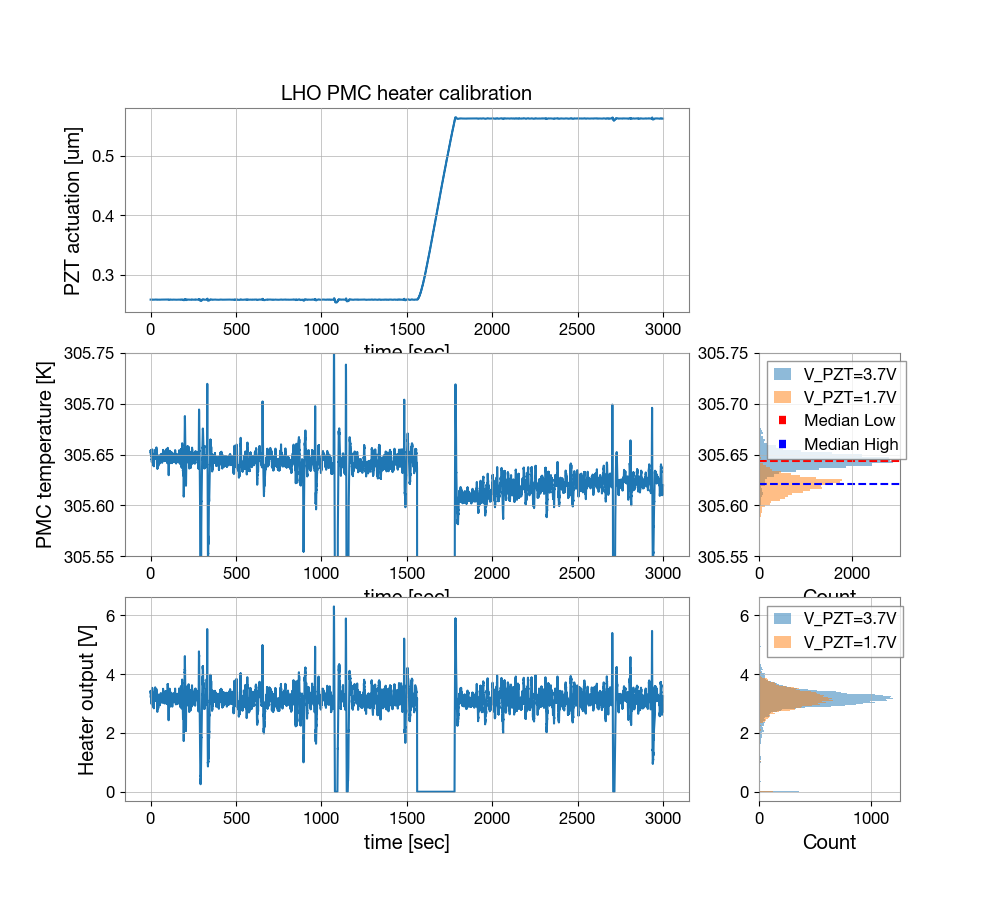
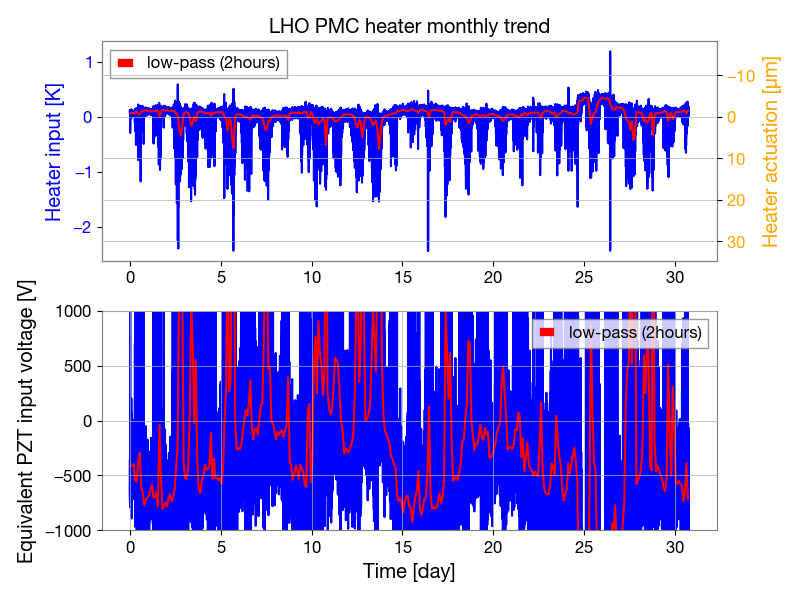
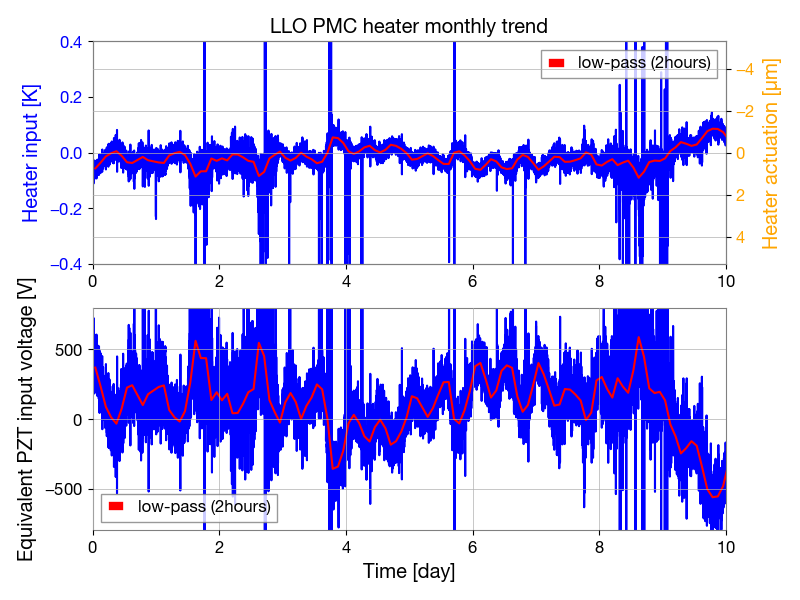
PCAL ES procedure & Log DCC T1500062 ( Modified for long measurement)
After beam spot
The analysis for the long measurement is still pending.
This adventure was brought to you by Dripta & Tony S.

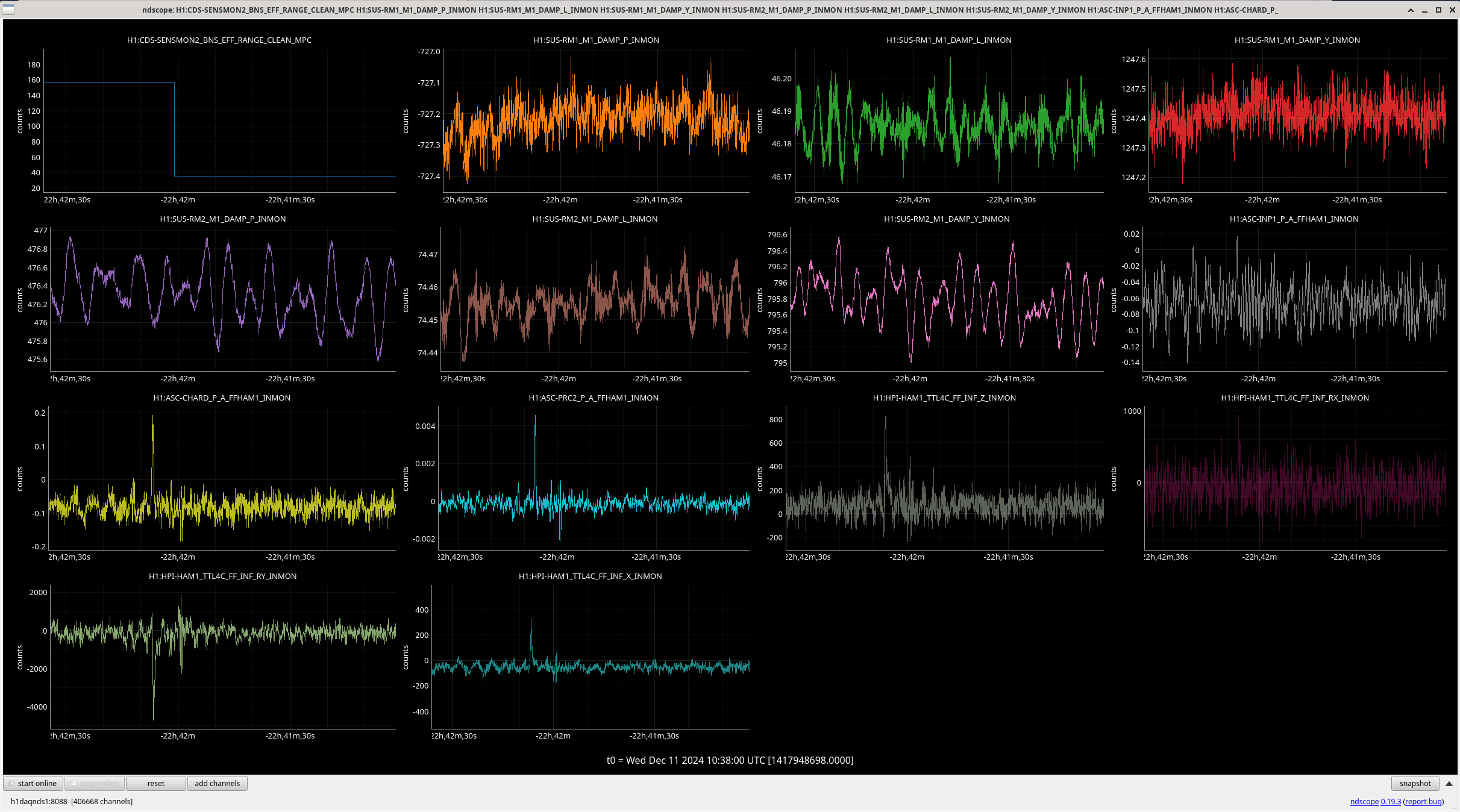
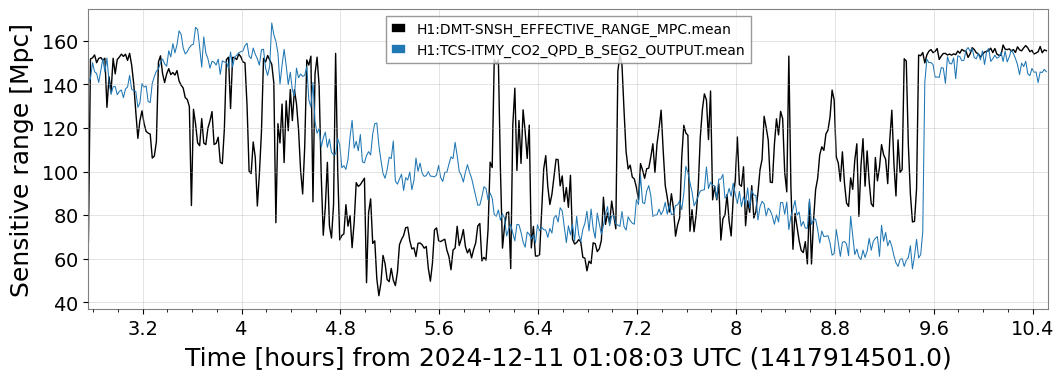
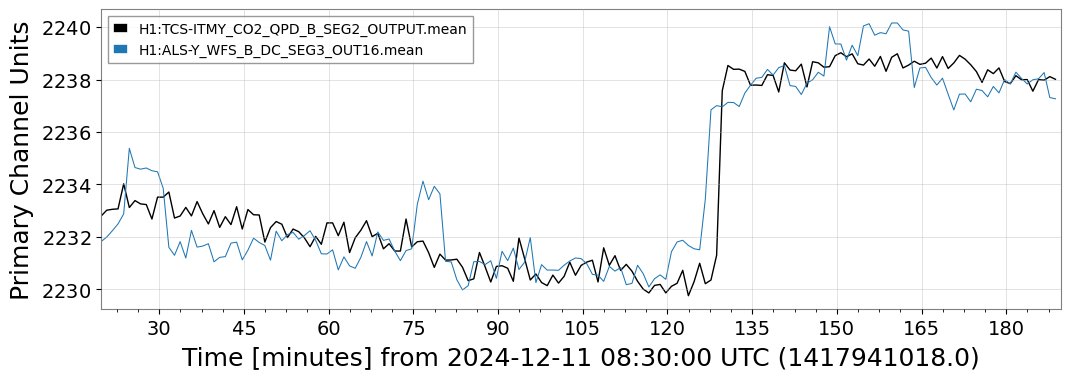
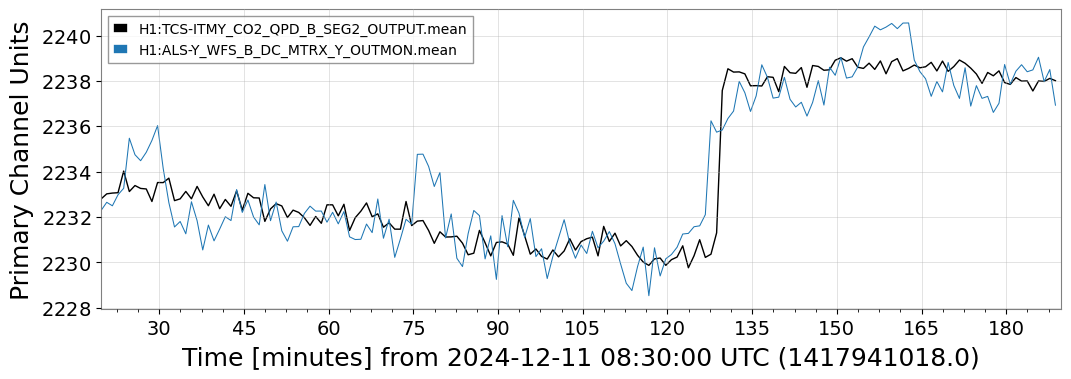
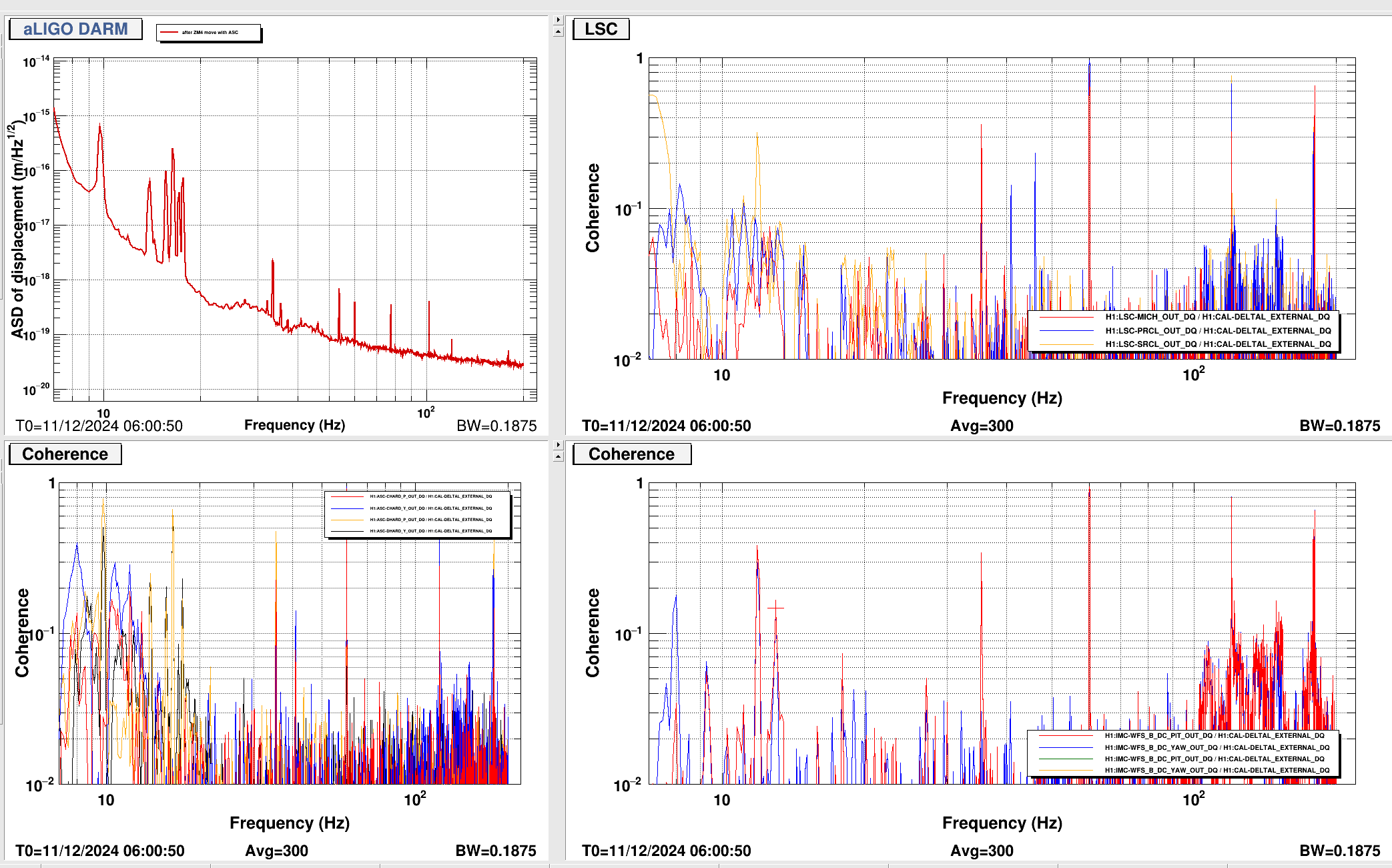
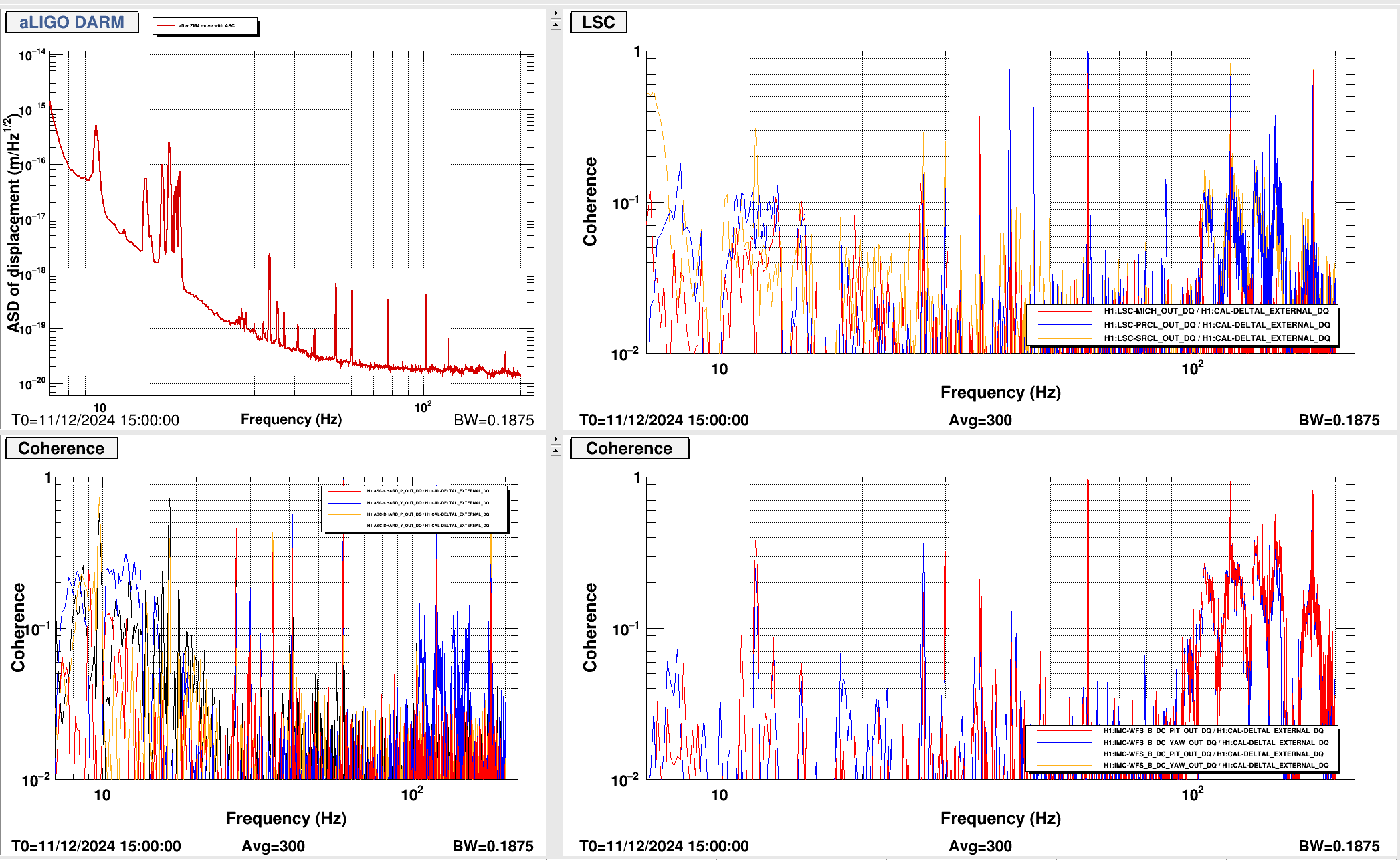
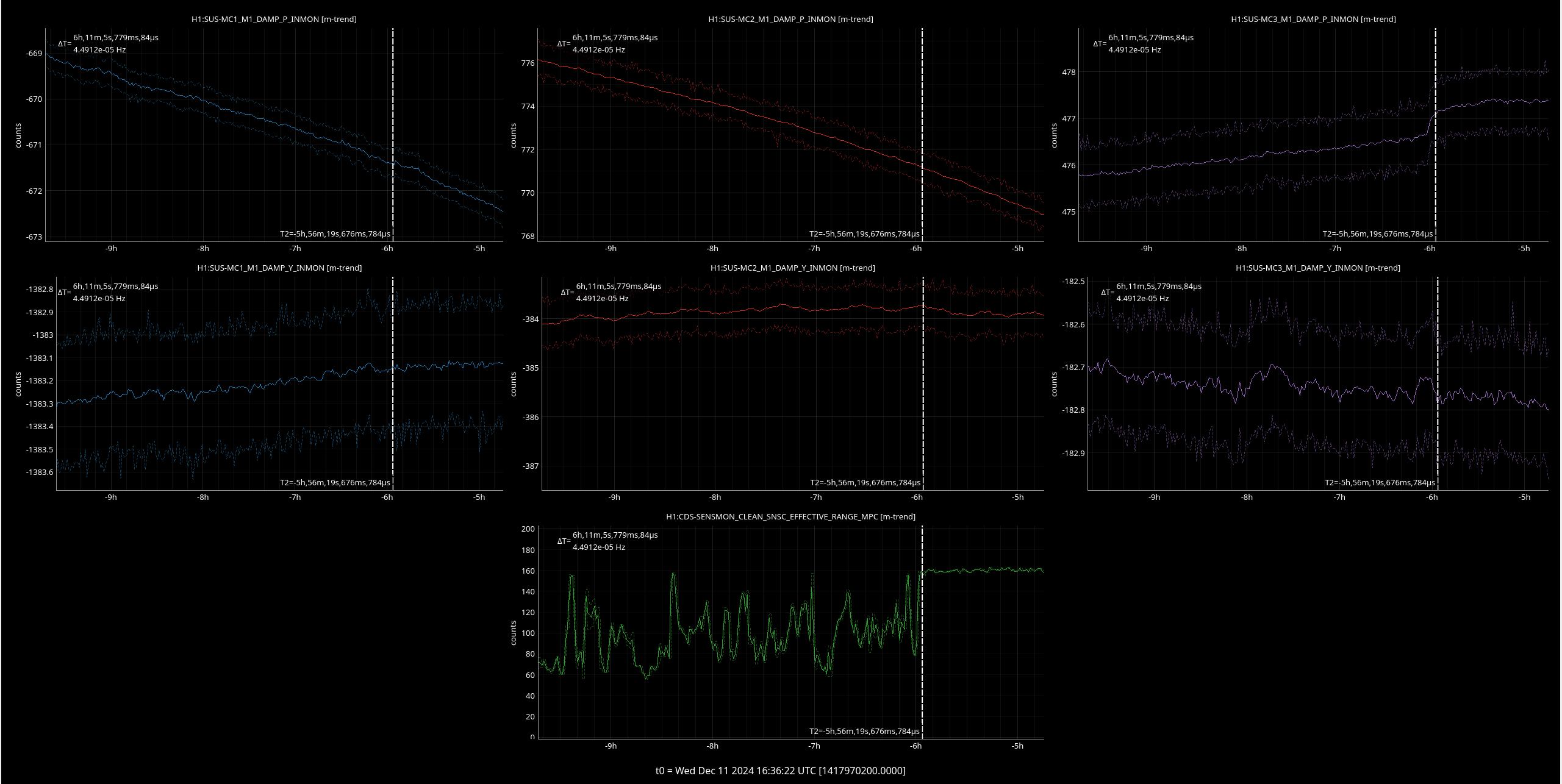
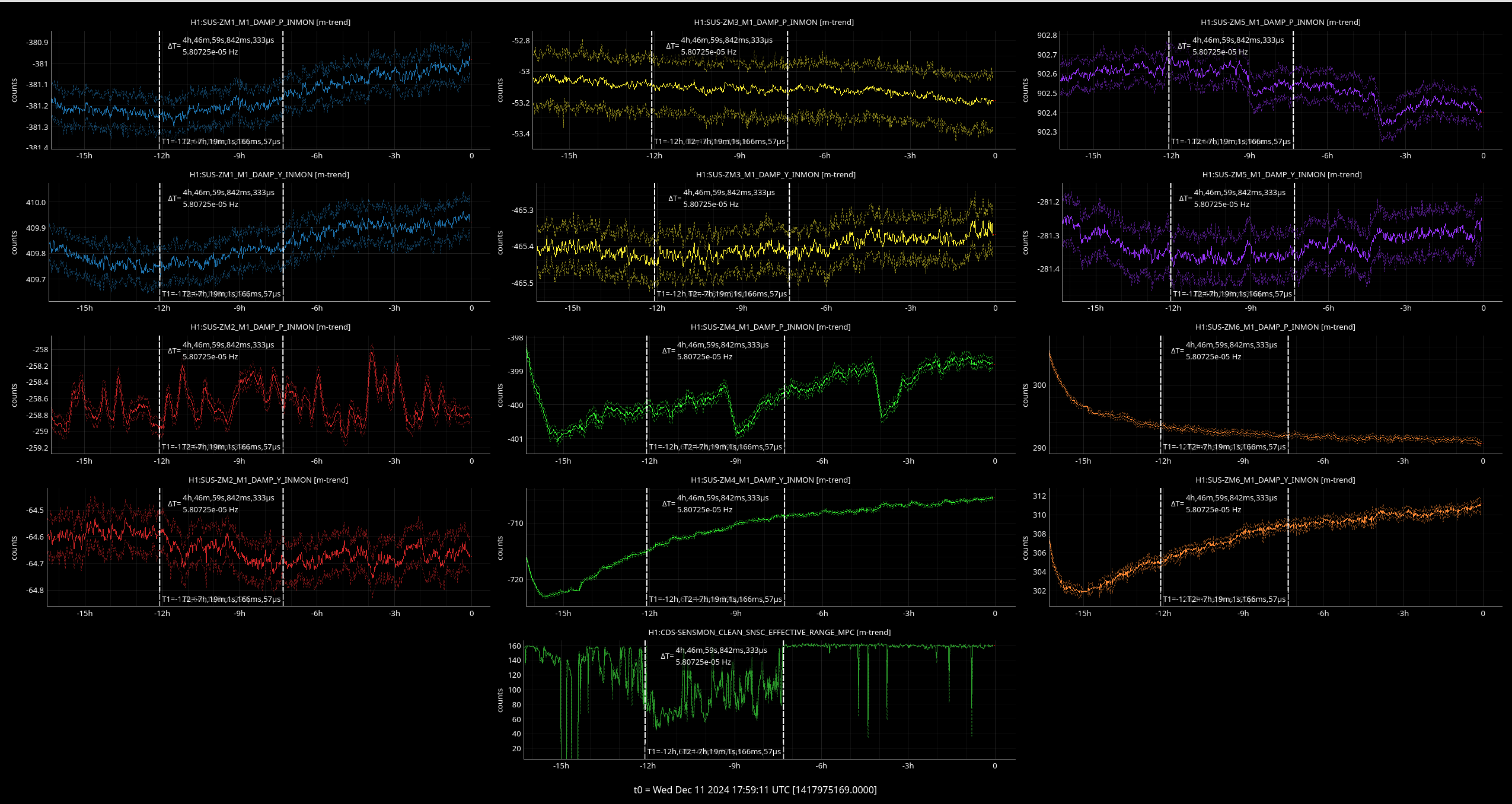
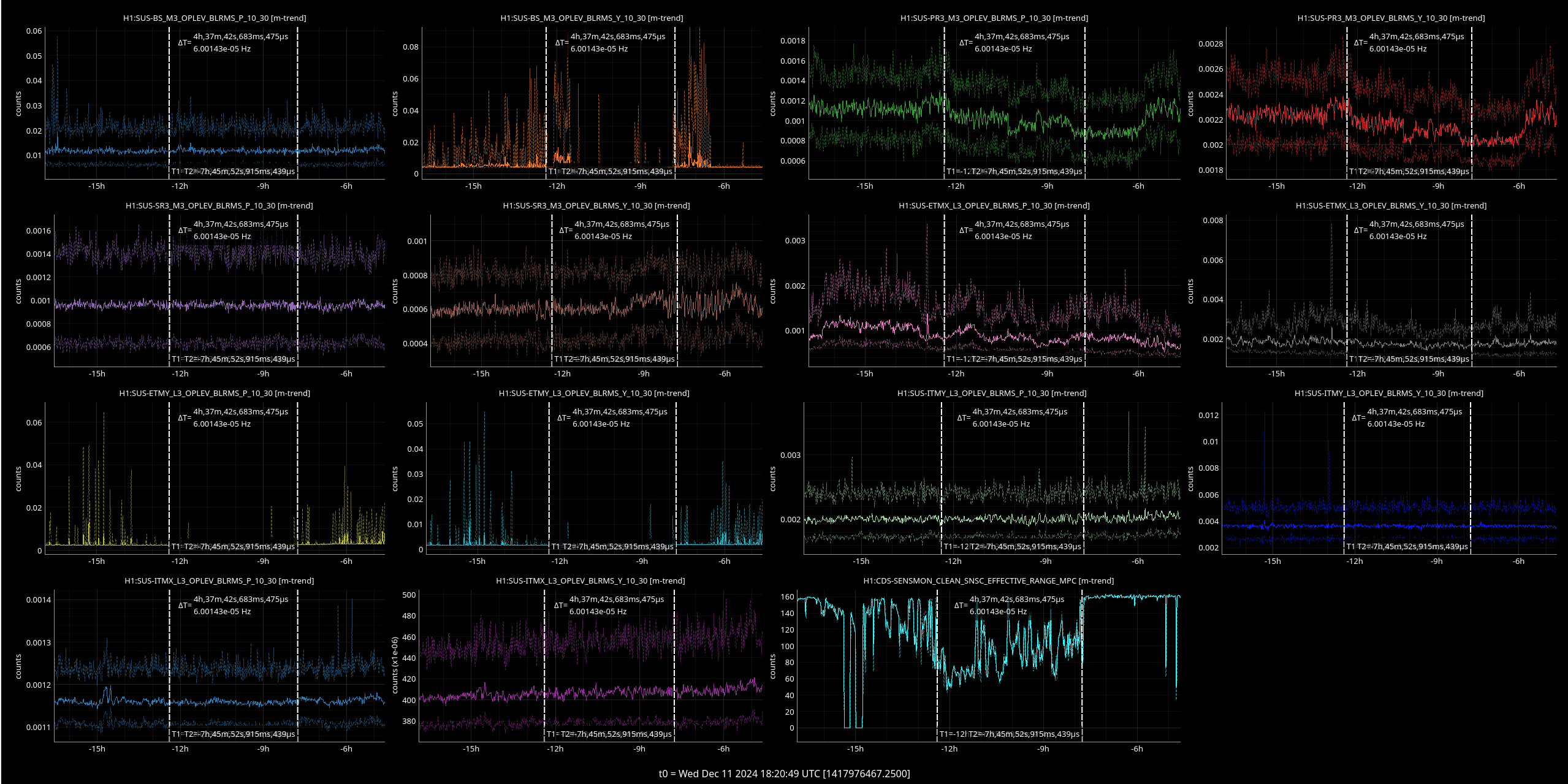
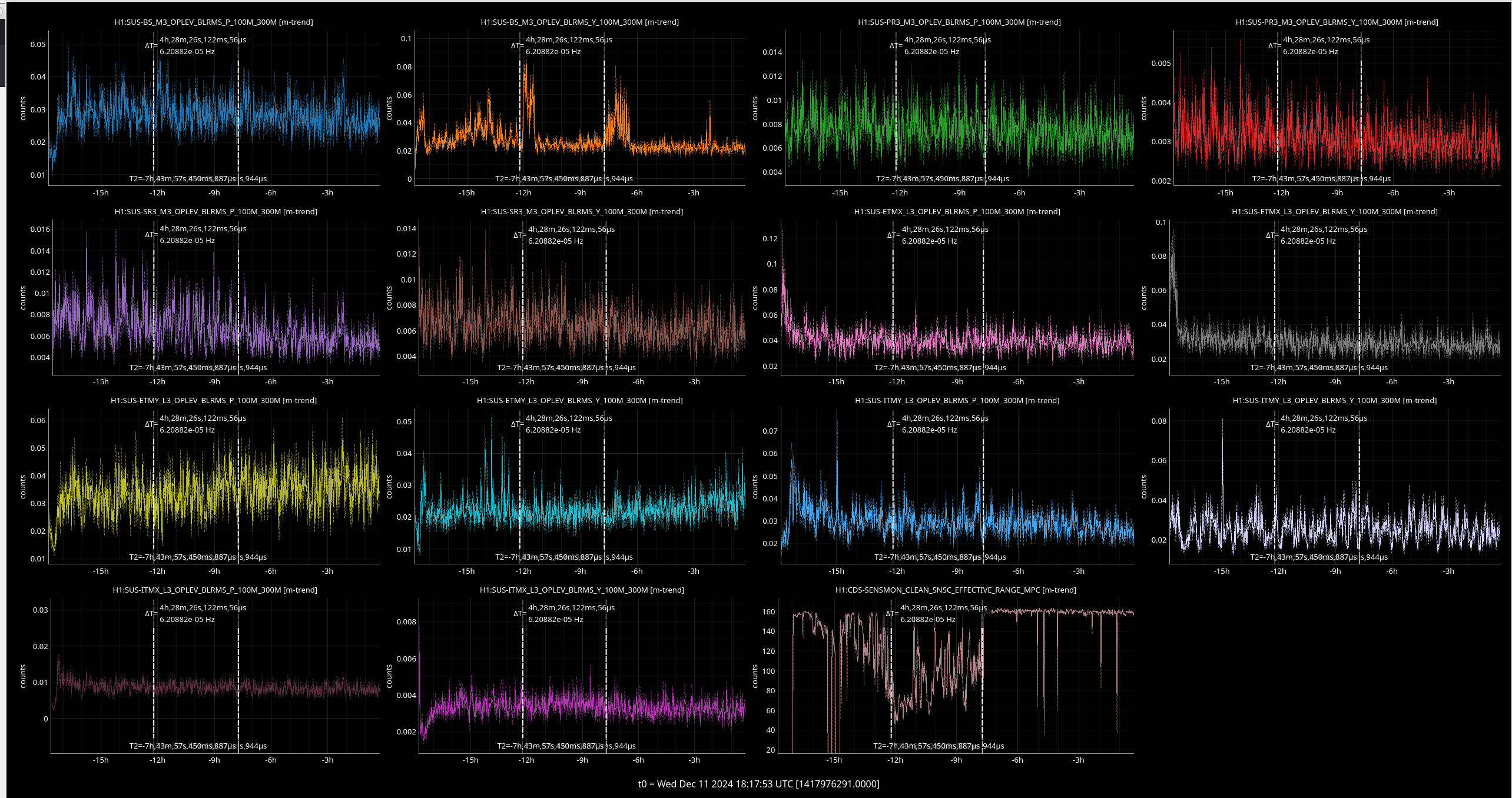



{kind=link}
{kind=link}
{kind=link}
{kind=link}
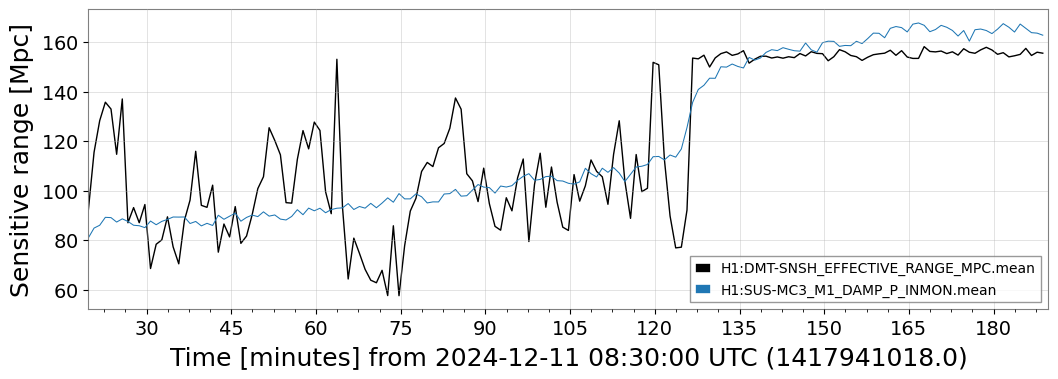{kind=link}
{kind=link}
{kind=link}
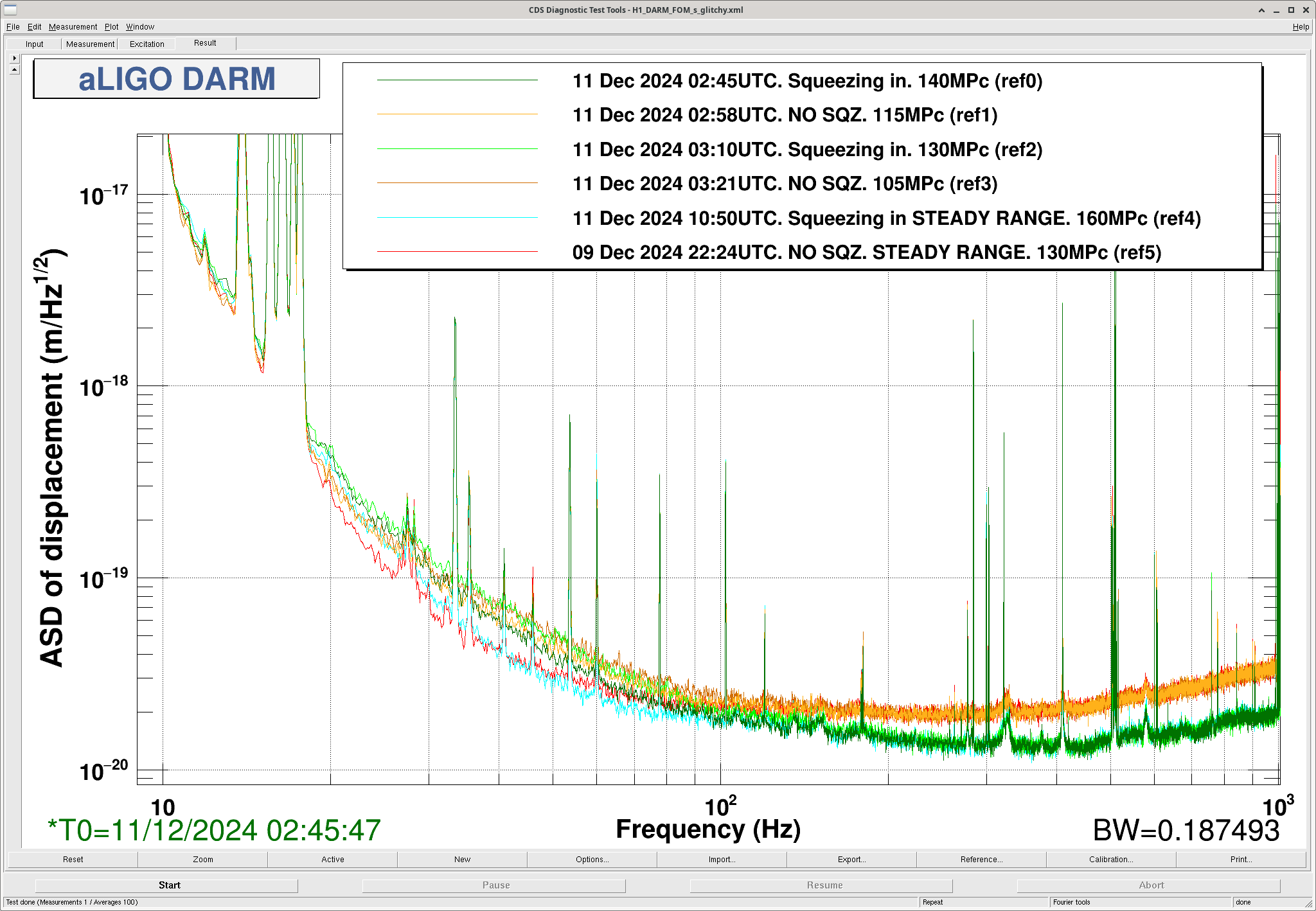{kind=link}
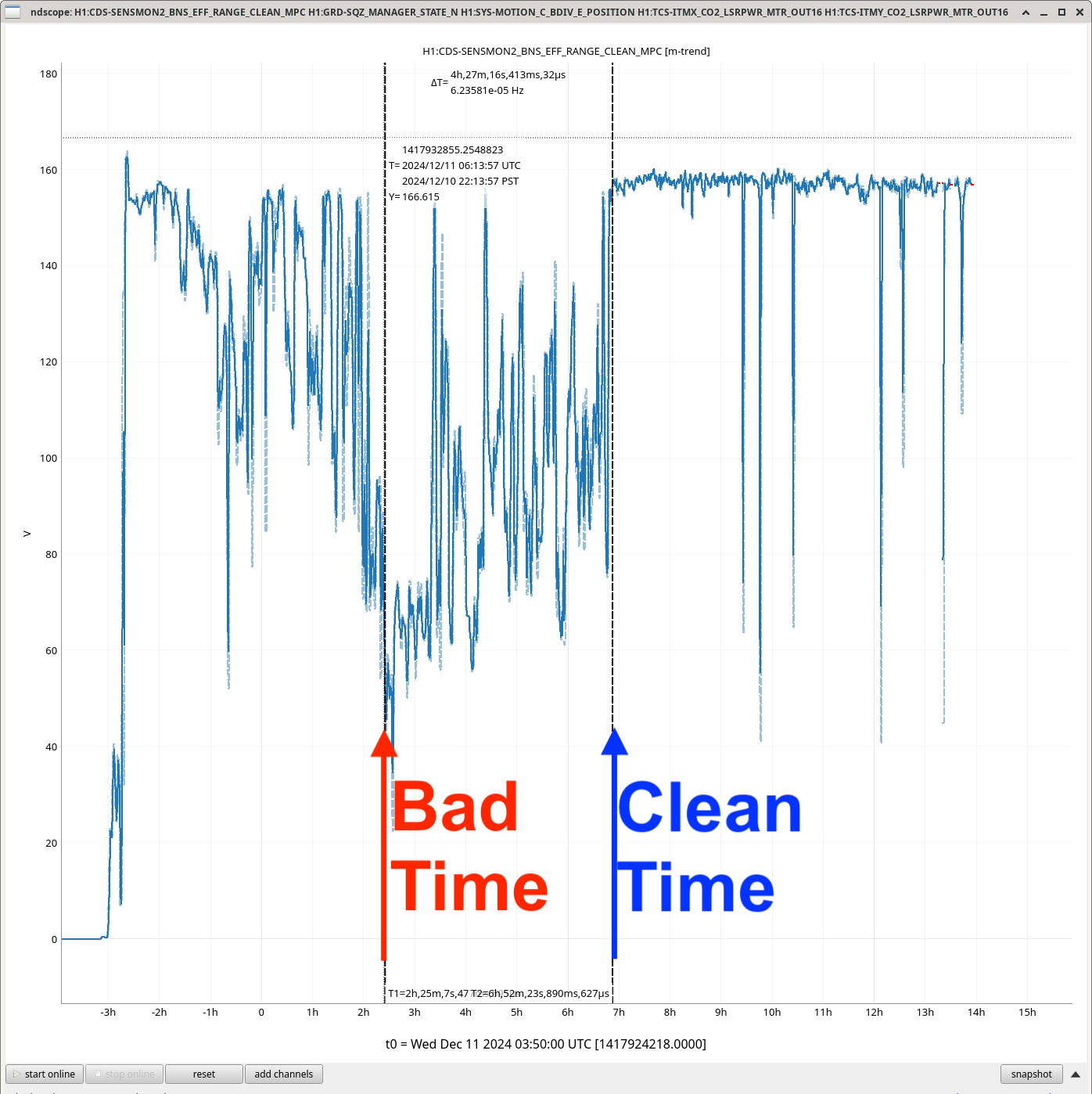{kind=link}
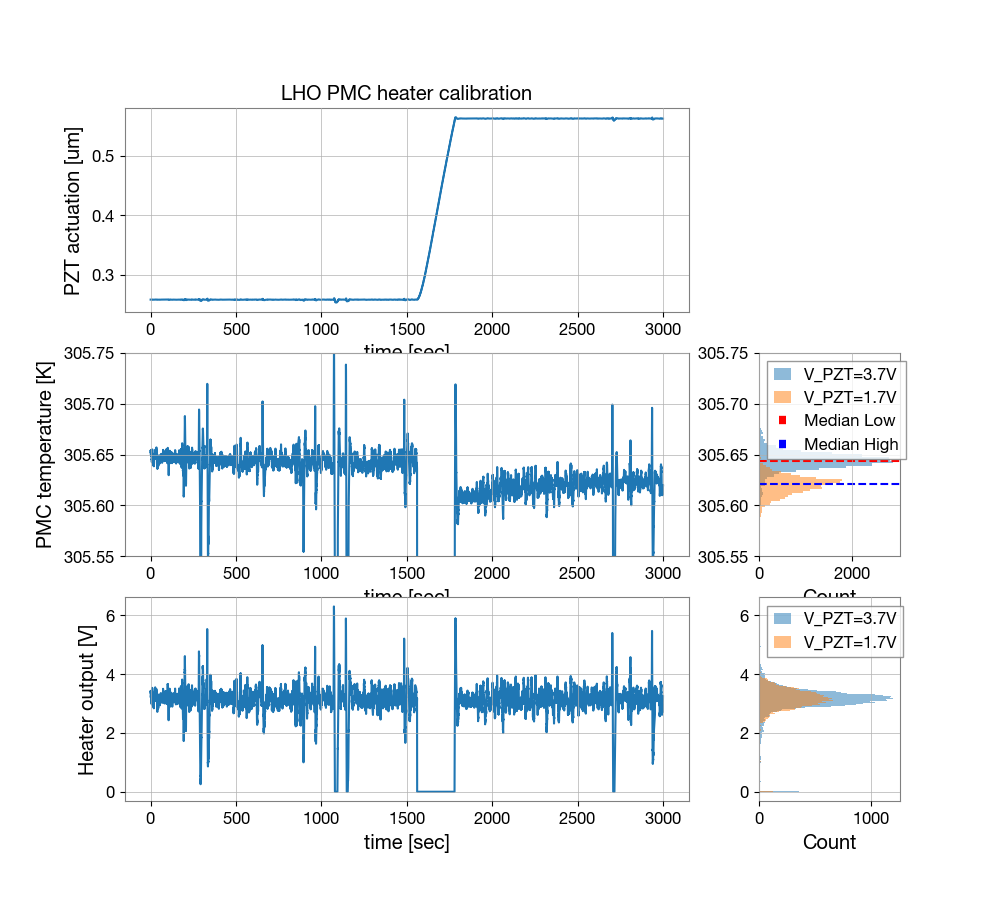{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}