IFO is in NLN and OBSERVING as of 11:15 UTC.
IMC/EX Rail/Non-Lockloss Lockloss Investigation:
In this order and according to the plots, this is what I believe happened.
I believe EX saturated, prompting IMC to fault while guardian was in DRMI_LOCKED_CHECK_ASC (23:17 PT), putting guardian in a weird fault state but keeping it in DRMI, without unlocking (still a mystery). Ryan C noticed this (23:32 PT) and requested IMC_LOCK to DOWN (23:38 PT), tripping MC2’s M2 and M3 (M3 first by a few ms). This prompted Guardian to call me (23:39 PT). What is strange is that even after Ryan C successfully put IMC in DOWN, guardian was unable to realize that IMC was in DOWN, and STAYED in DRMI_LOCKED_CHECK_ASC until Ryan C requested it to go to INIT. Only after then did the EX Saturations stop. While the EX L3 stage is what saturated before IMC, I don’t know what caused EX to saturate like this. The wind and microseism were not too bad so this could definitely be one of the other known glitches happening before all of this, causing EX to rail.
Here’s the timeline (Times in PT)
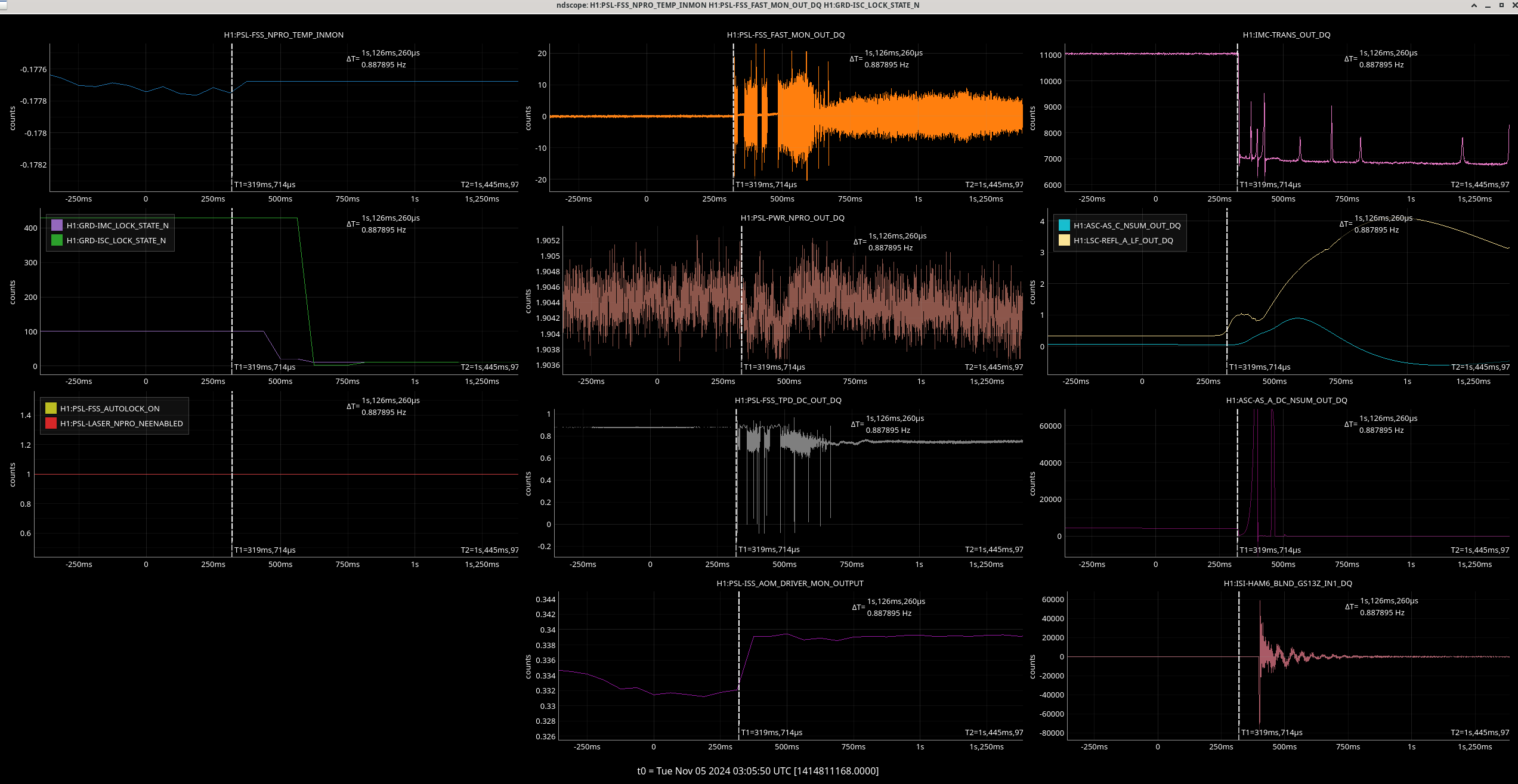
23:17: EX saturates. 300ms later, IMC faults as a cause of this.
23:32: Ryan C notices this weird behavior in IMC lock and MC2 and texted me. He noticed that IMC lost lock and faulted, but that this didn’t prompt an IFO Lockloss. Guardian was still at DRMI_LOCKED_CHECK_ASC, but not understanding that IMC is unlocked and EX is still railing.
23:38: In response, Ryan C put IMC Lock to DOWN, which tripped MC2’s M3 and M2 stages. This called me. I was experiencing technical issues logging in, so ventured to site (made it on-site 00:40 UTC).
00:00: Ryan C successfully downed IFO by requesting INIT. Only then did EX stop saturating.
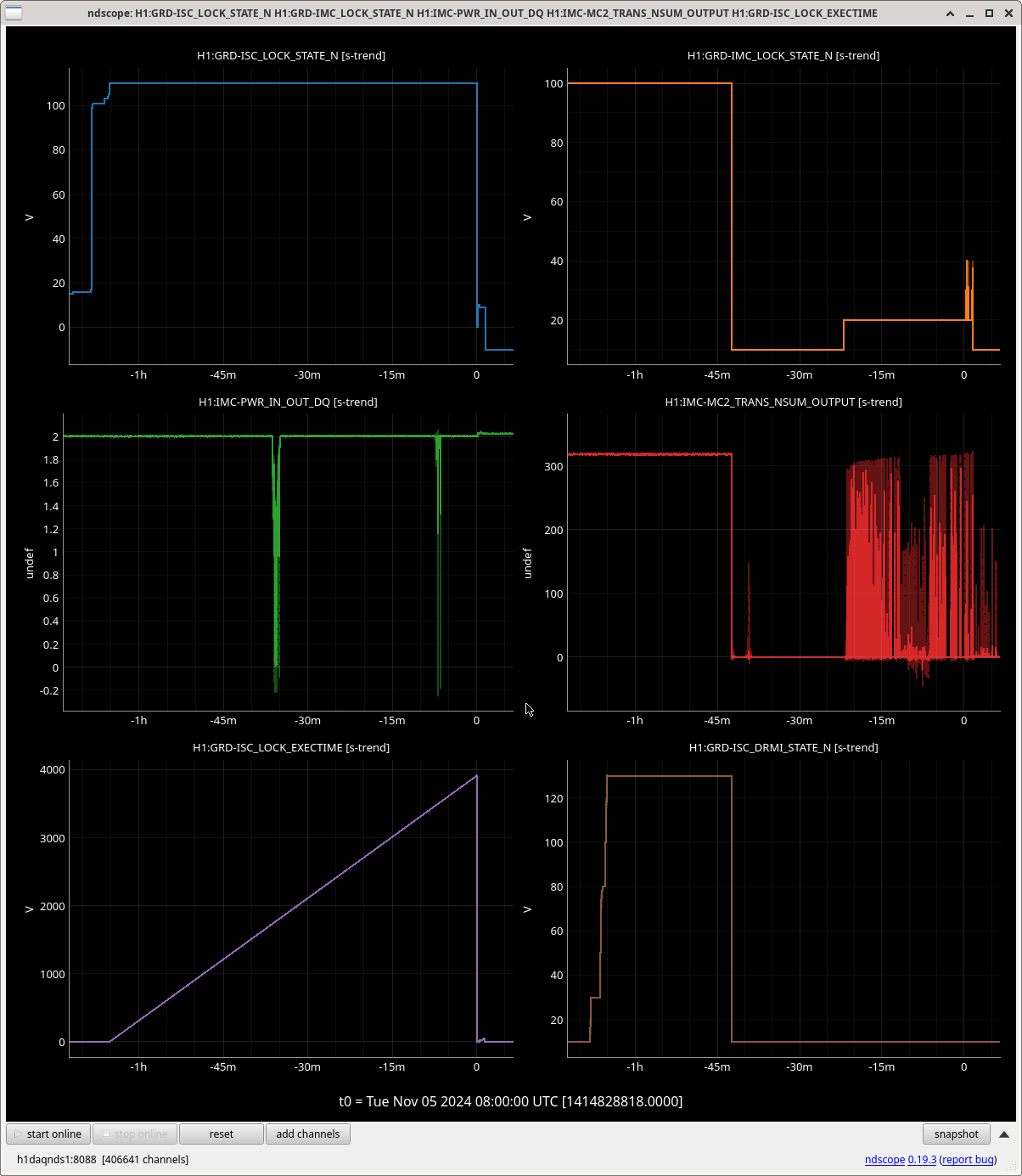
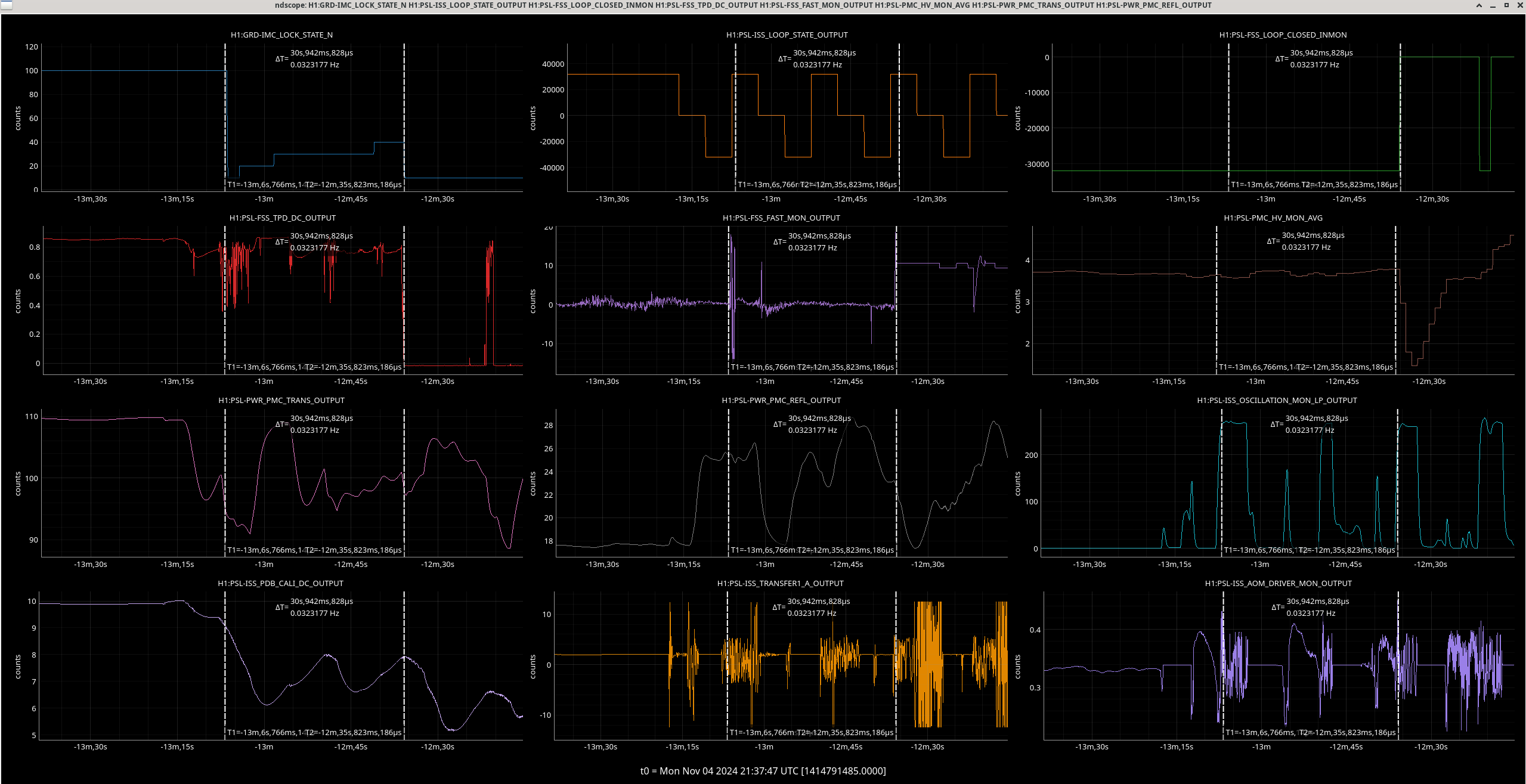
00:40: I start investigating this weird IMC fault. I also untrip MC2 and start an initial alignment (fully auto). We lose lock at LOWNOISE_ESD_ETMX, seemingly due to large sus instability probably from the prior railing since current wind and microseism aren’t absurdly high. (EY, IX, HAM6 and EX saturate). The LL tool is showing an ADS excursion tag.
03:15: NLN and OBSERVING achieved. We got to OMC_Whitening at 02:36 but violins were understandably quite high after this weird issue.
Evidence in plots explained:
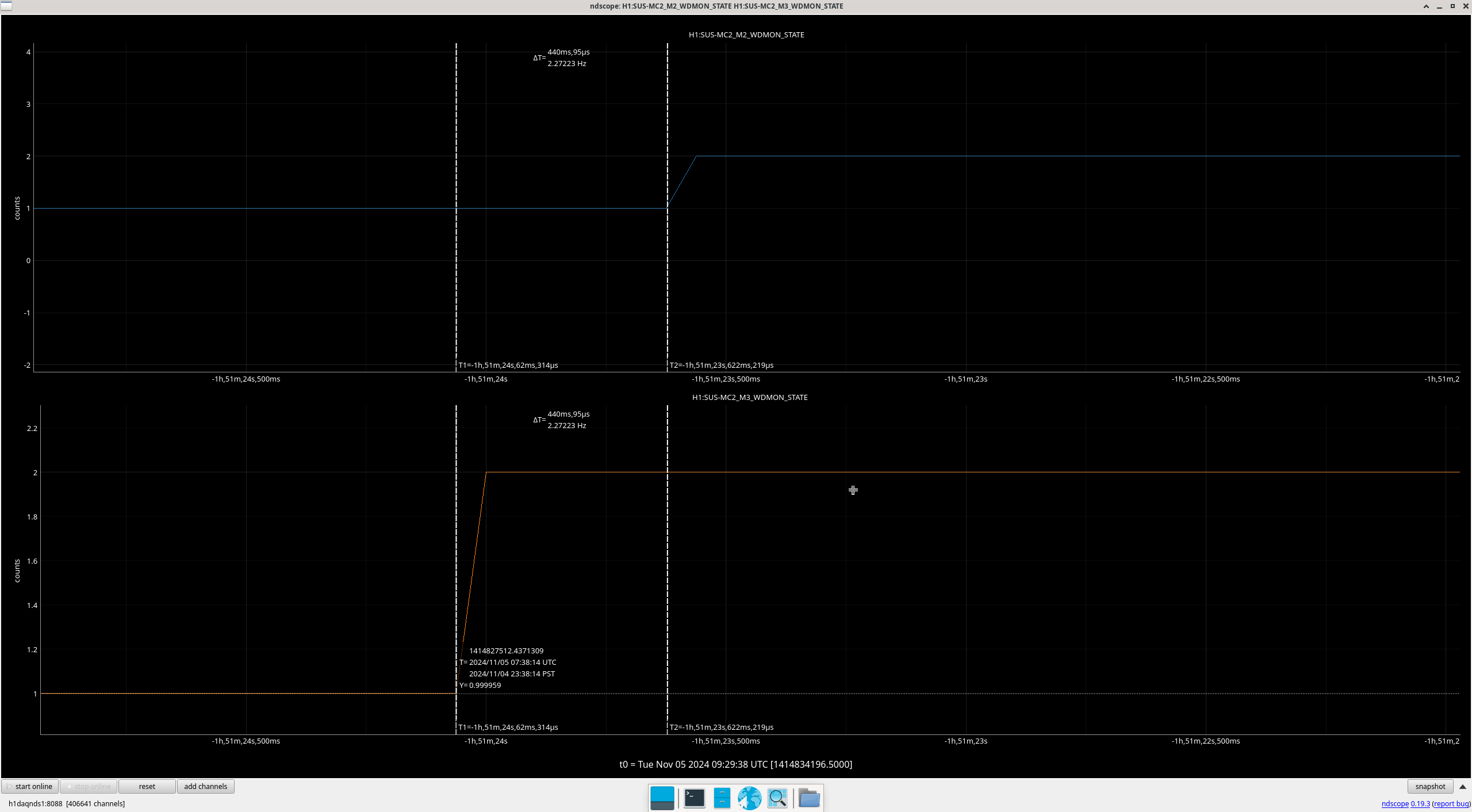
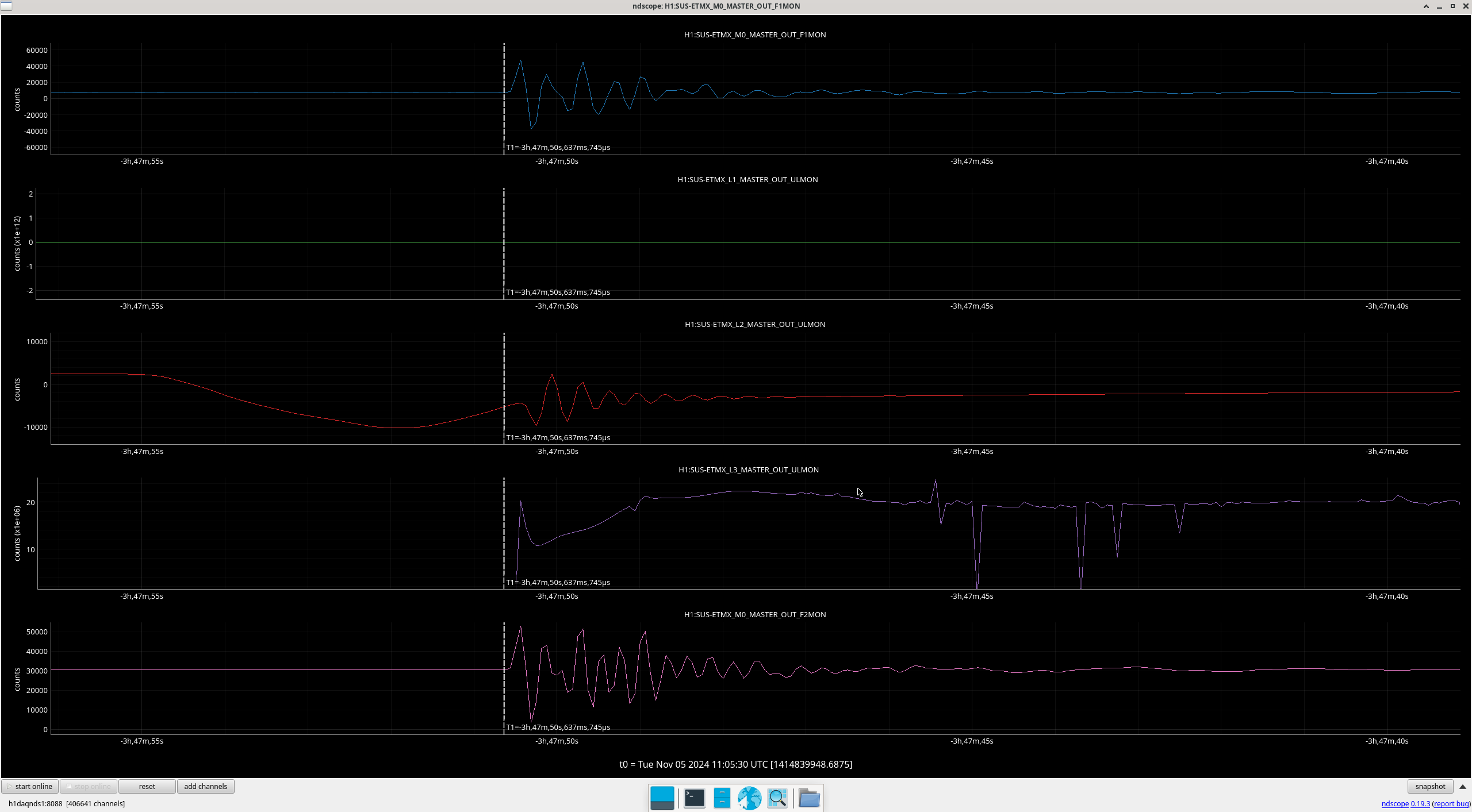
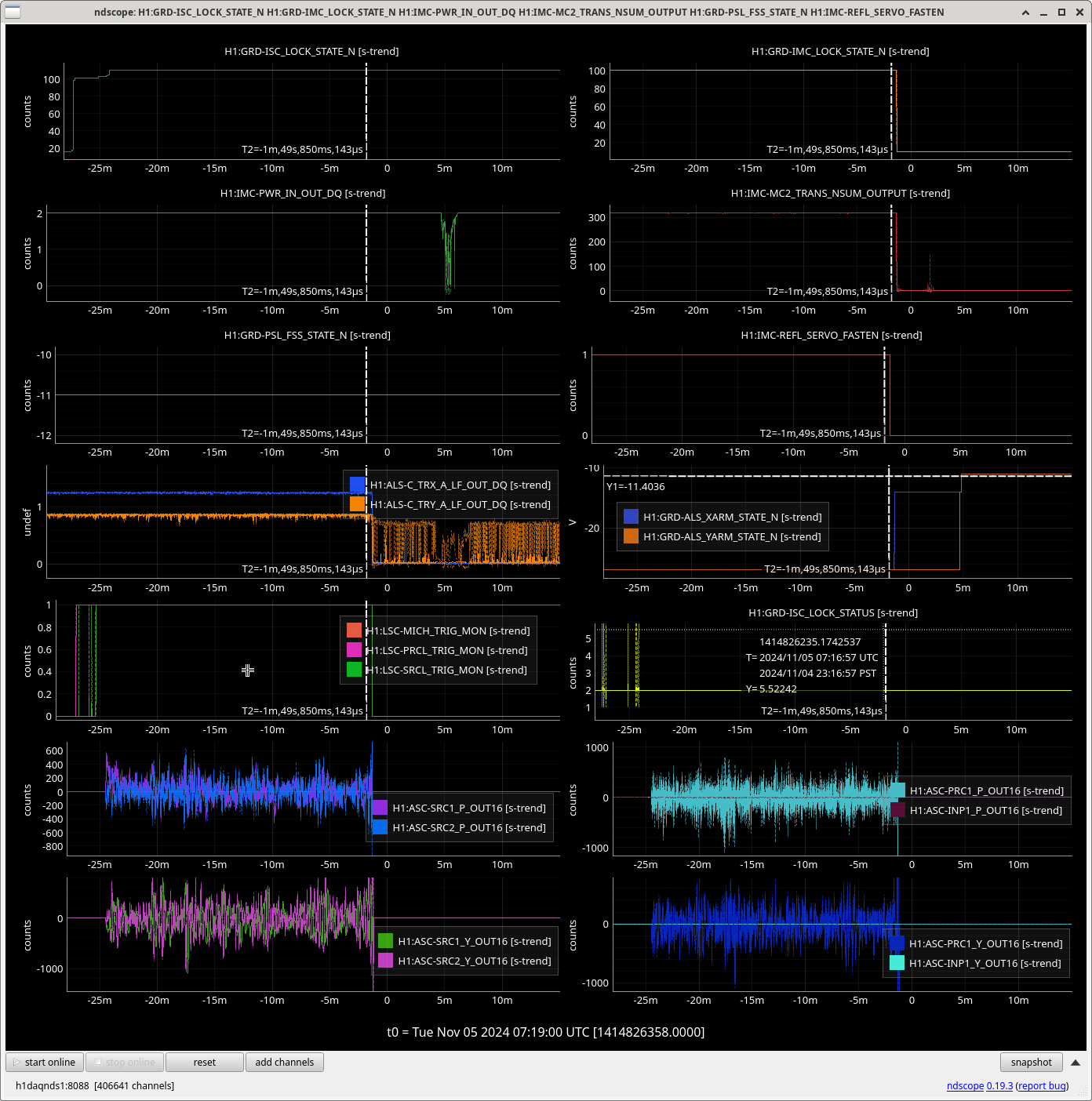
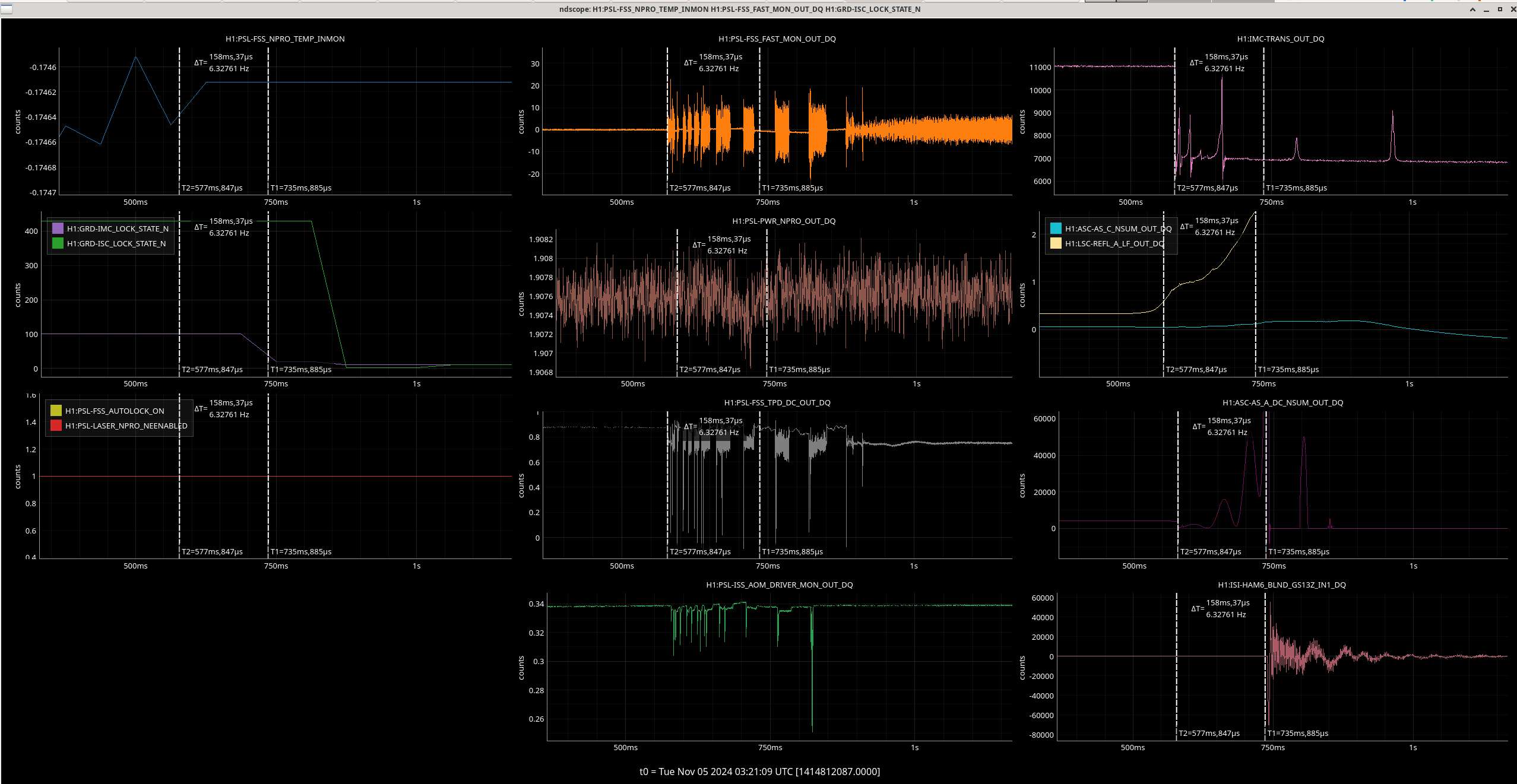
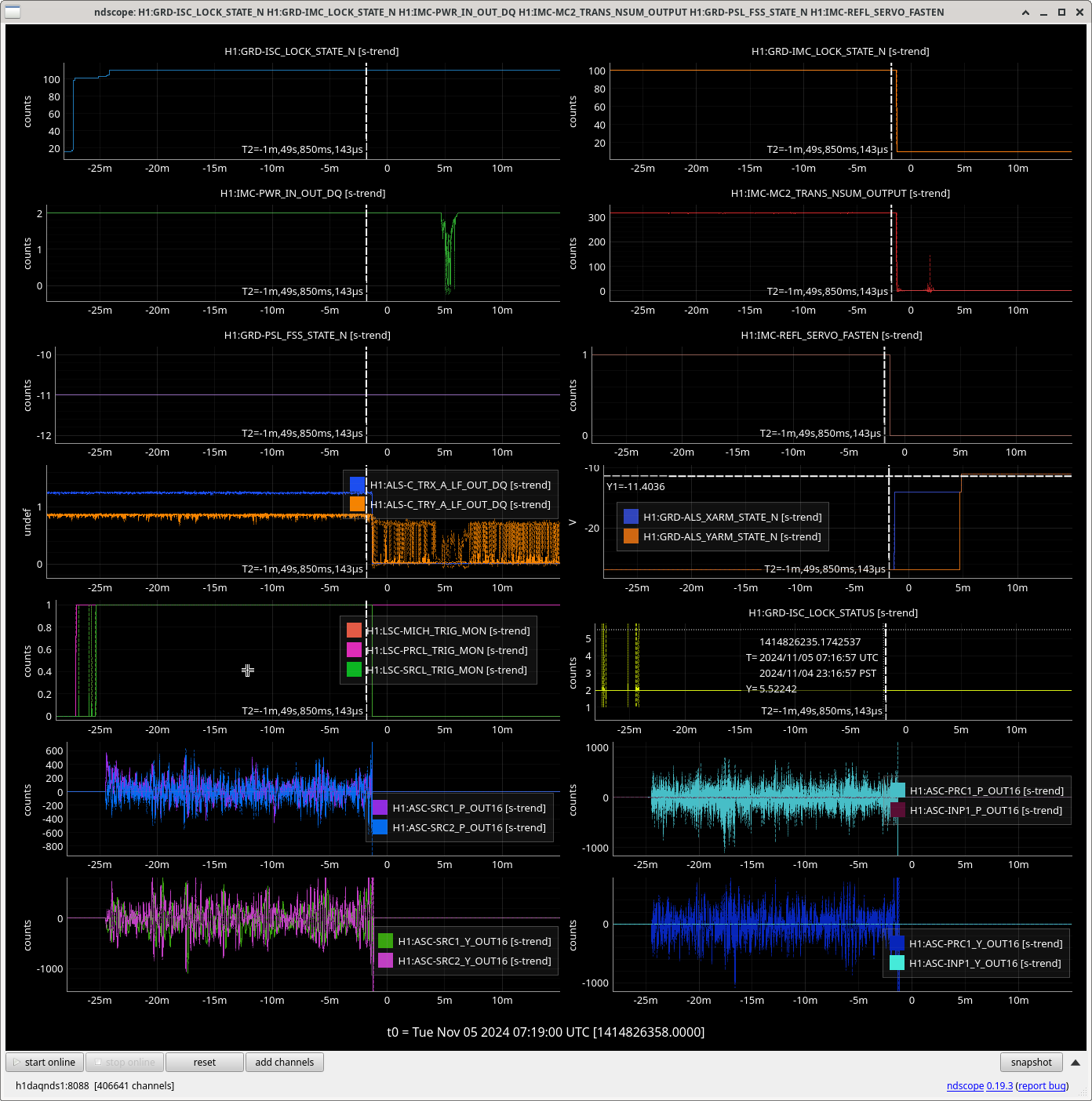
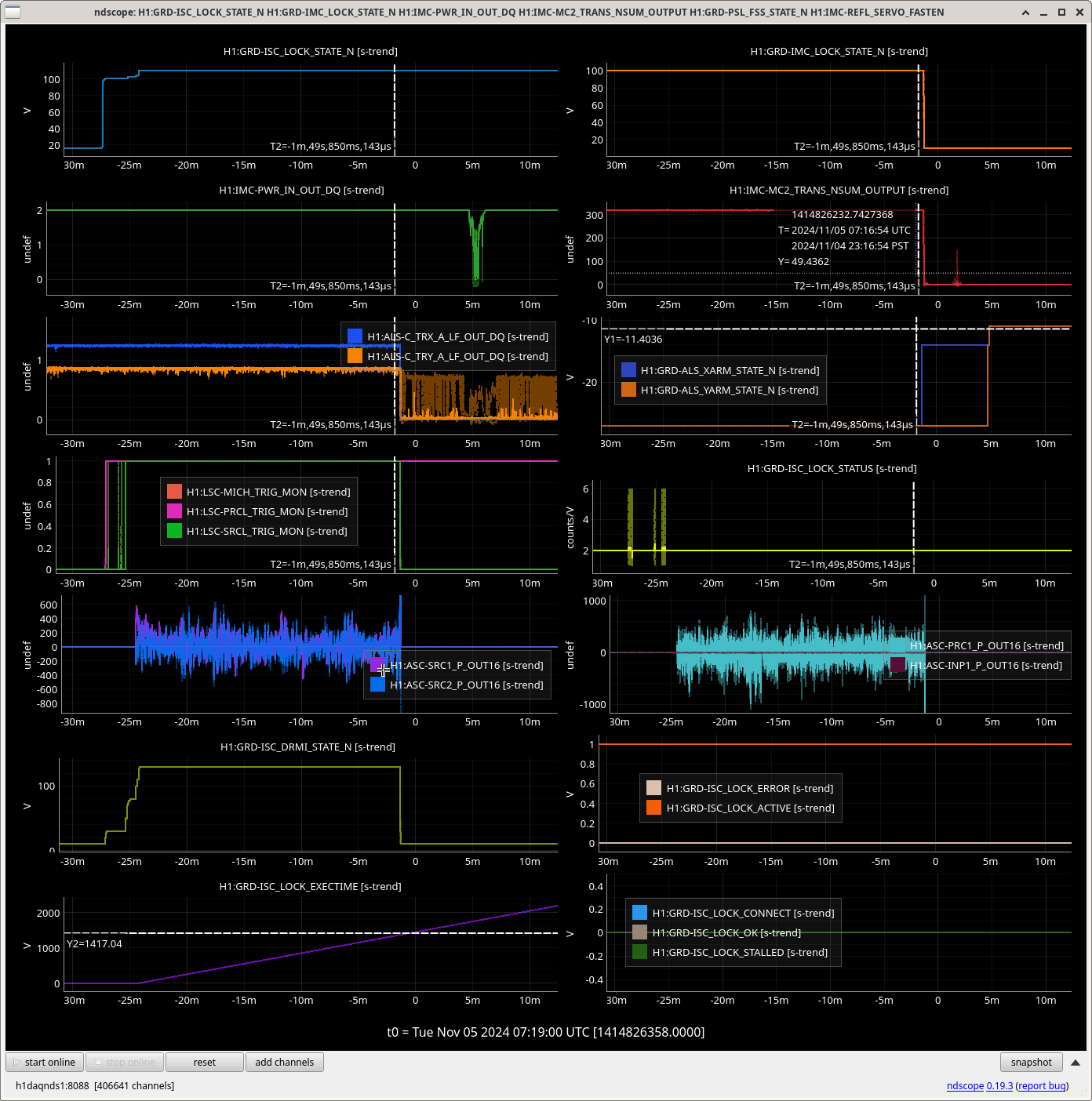
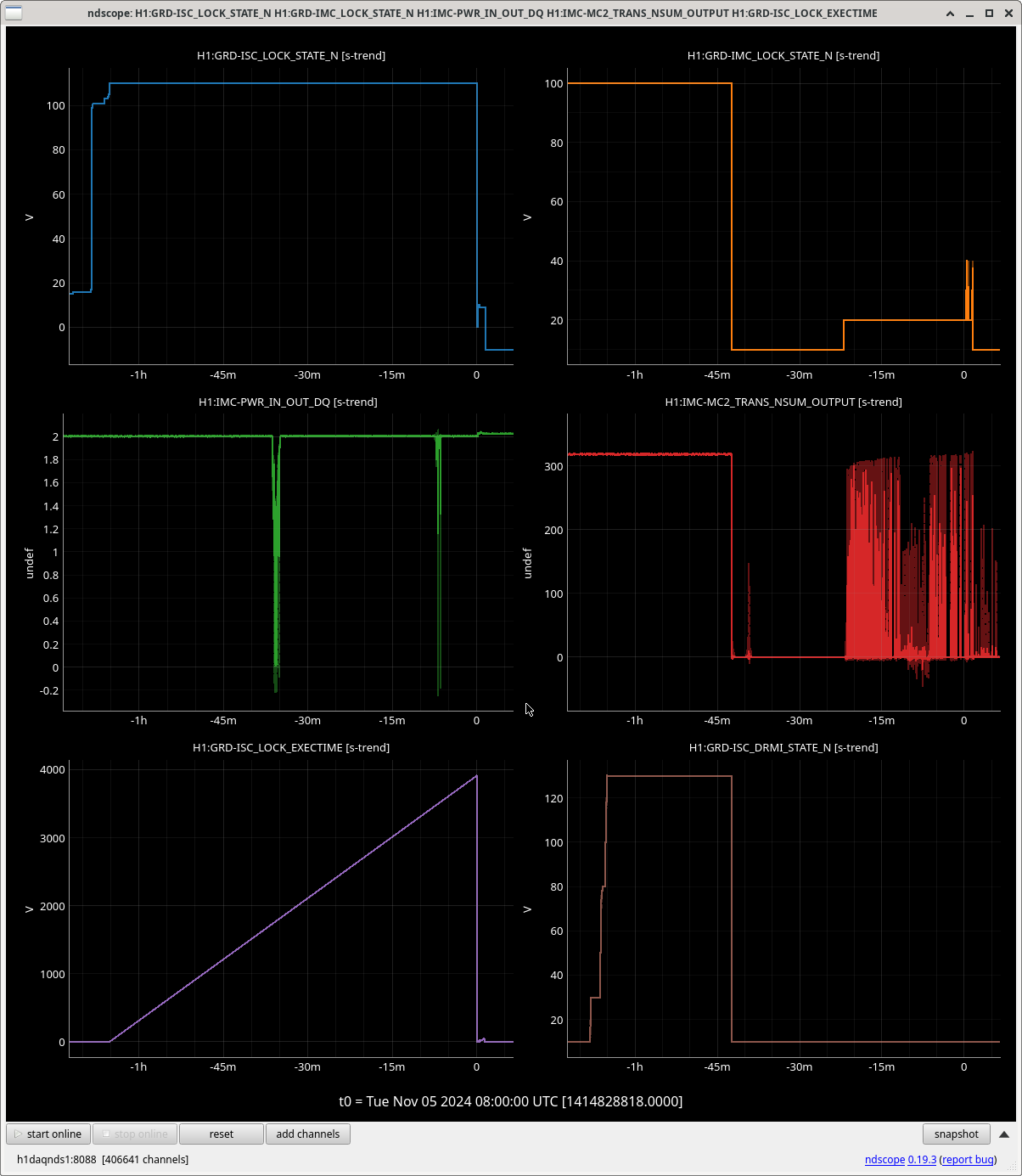
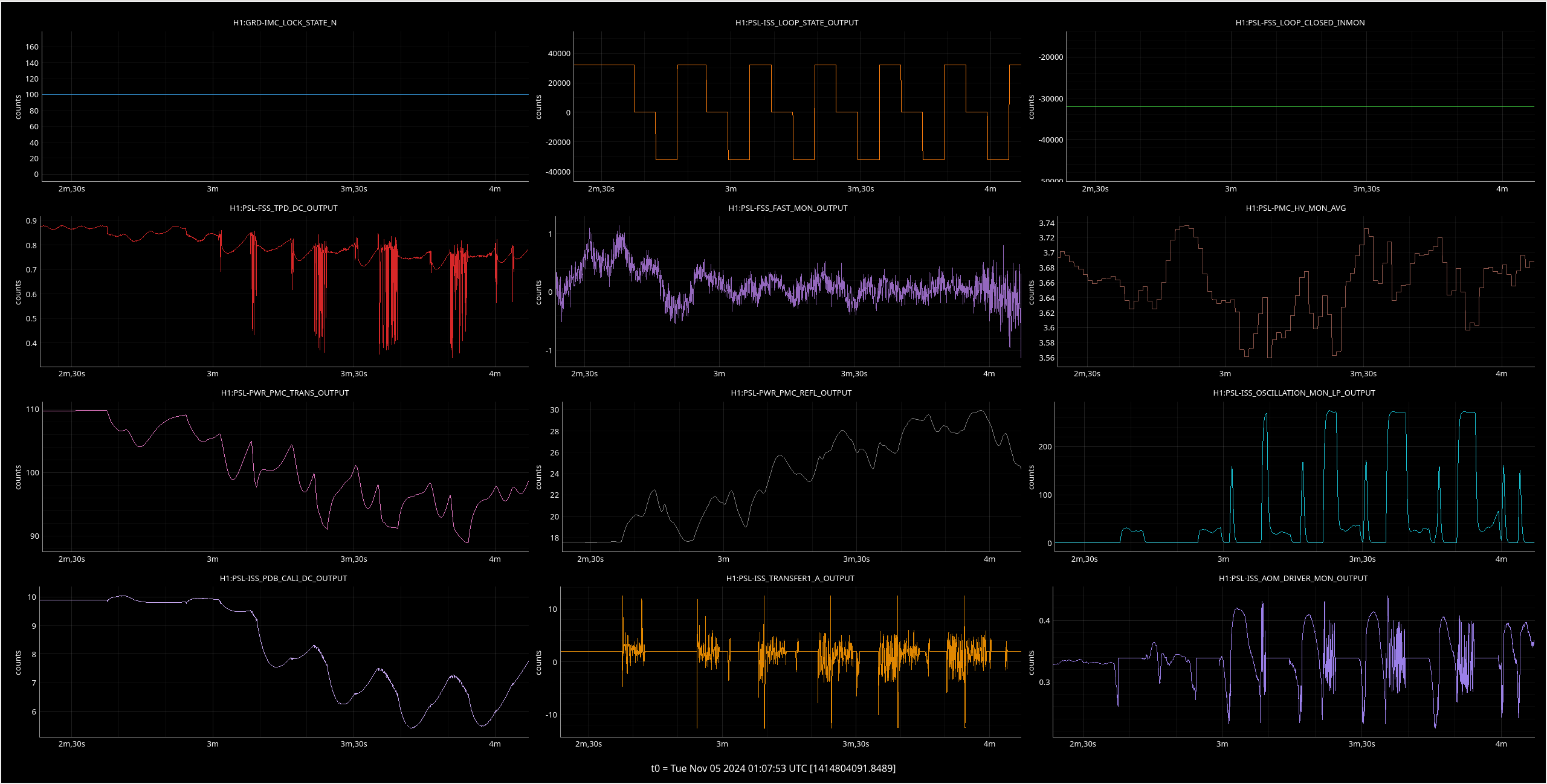
Img 1: M3 trips 440ms before M2. Doesn’t say much but was suspicious before I found out that EX saturated first. Was the first thing I investigated since it was the reason for call (I think).
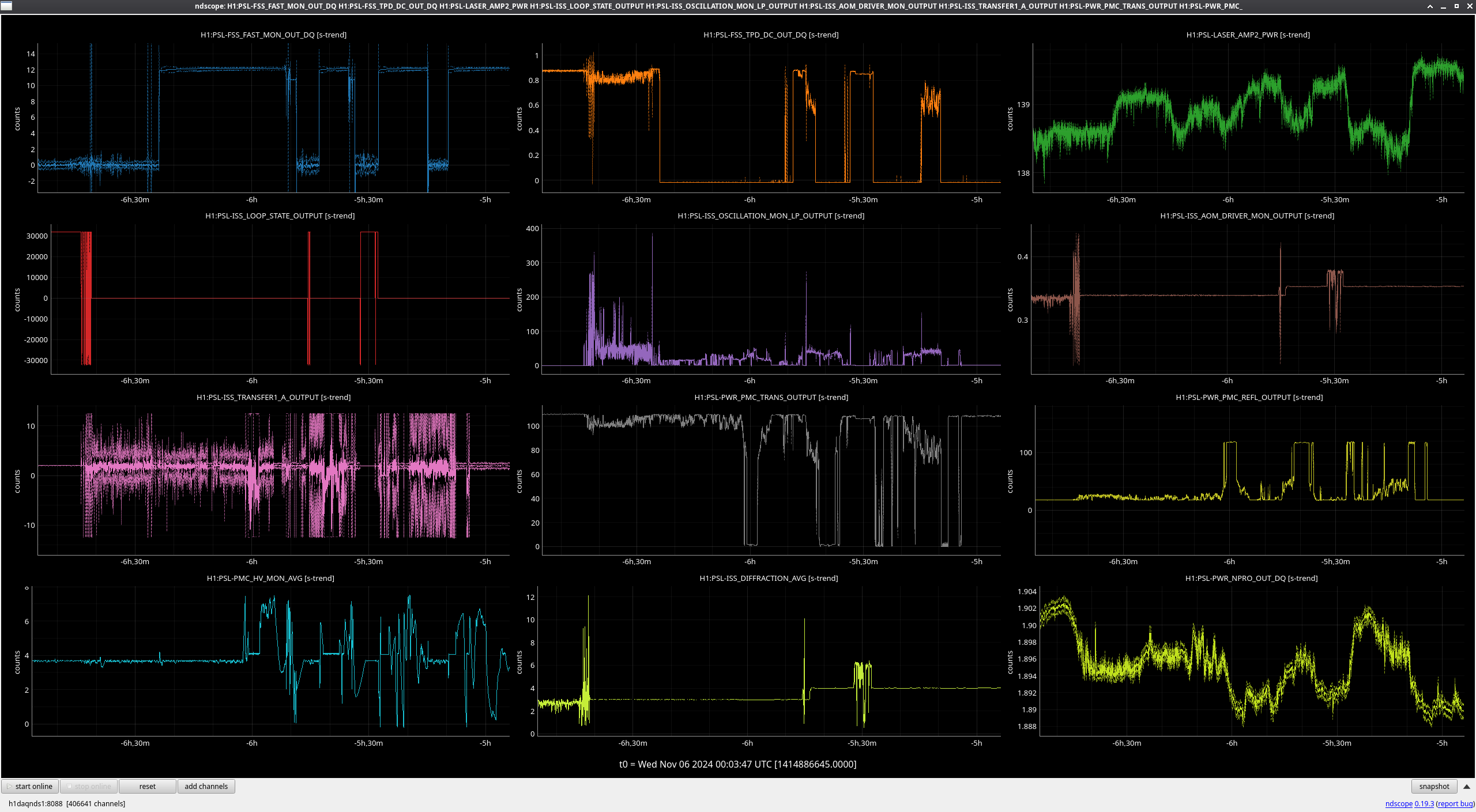
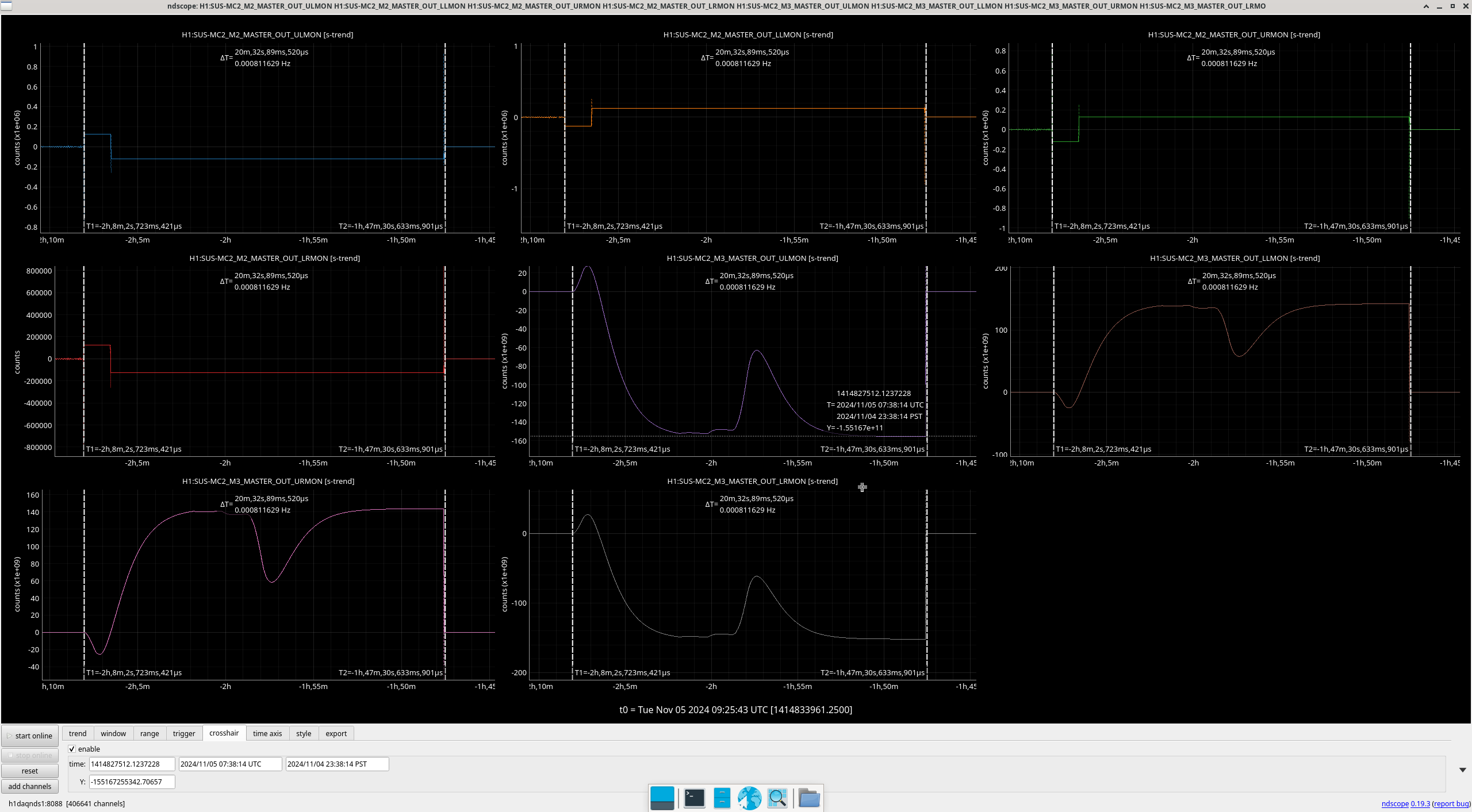
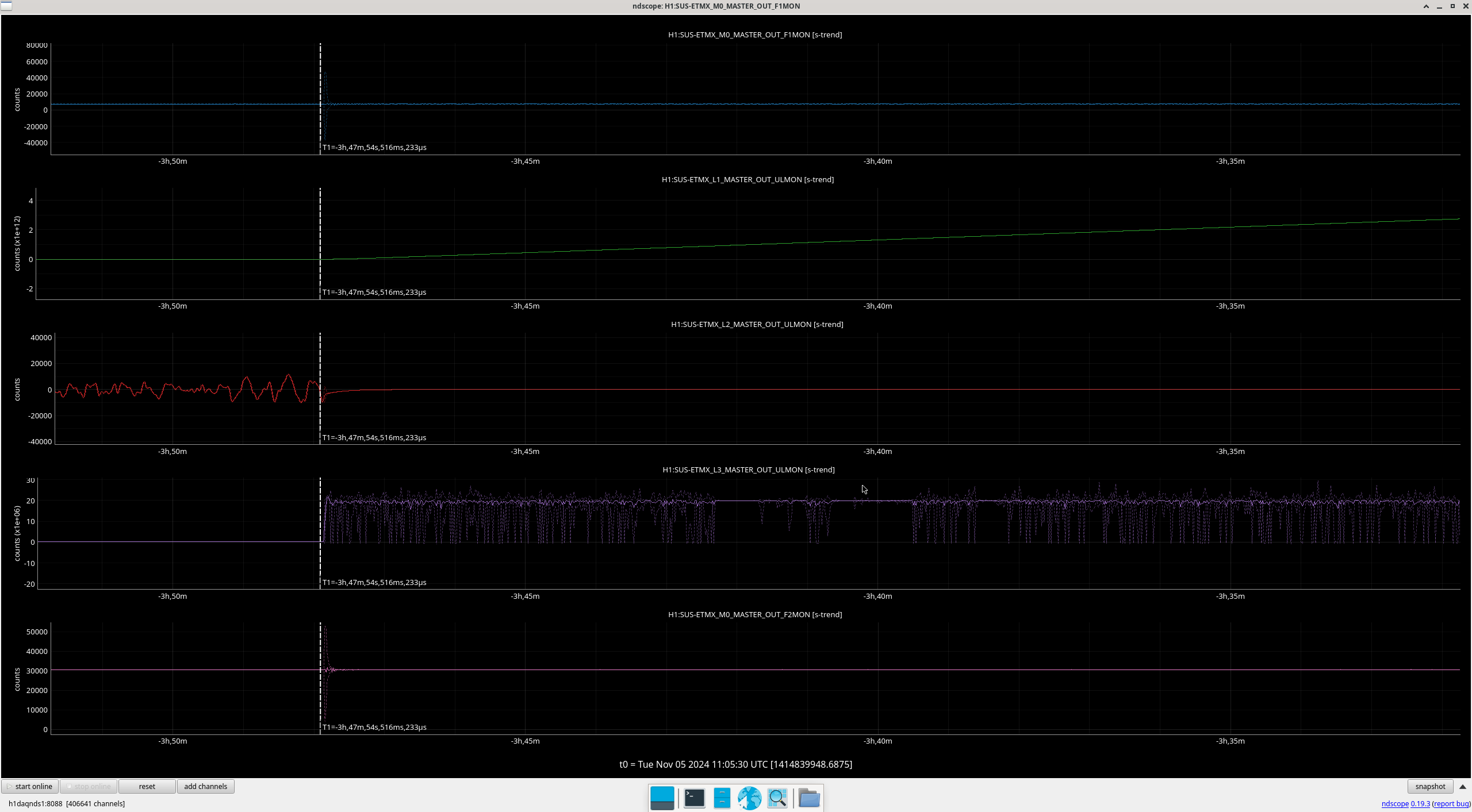
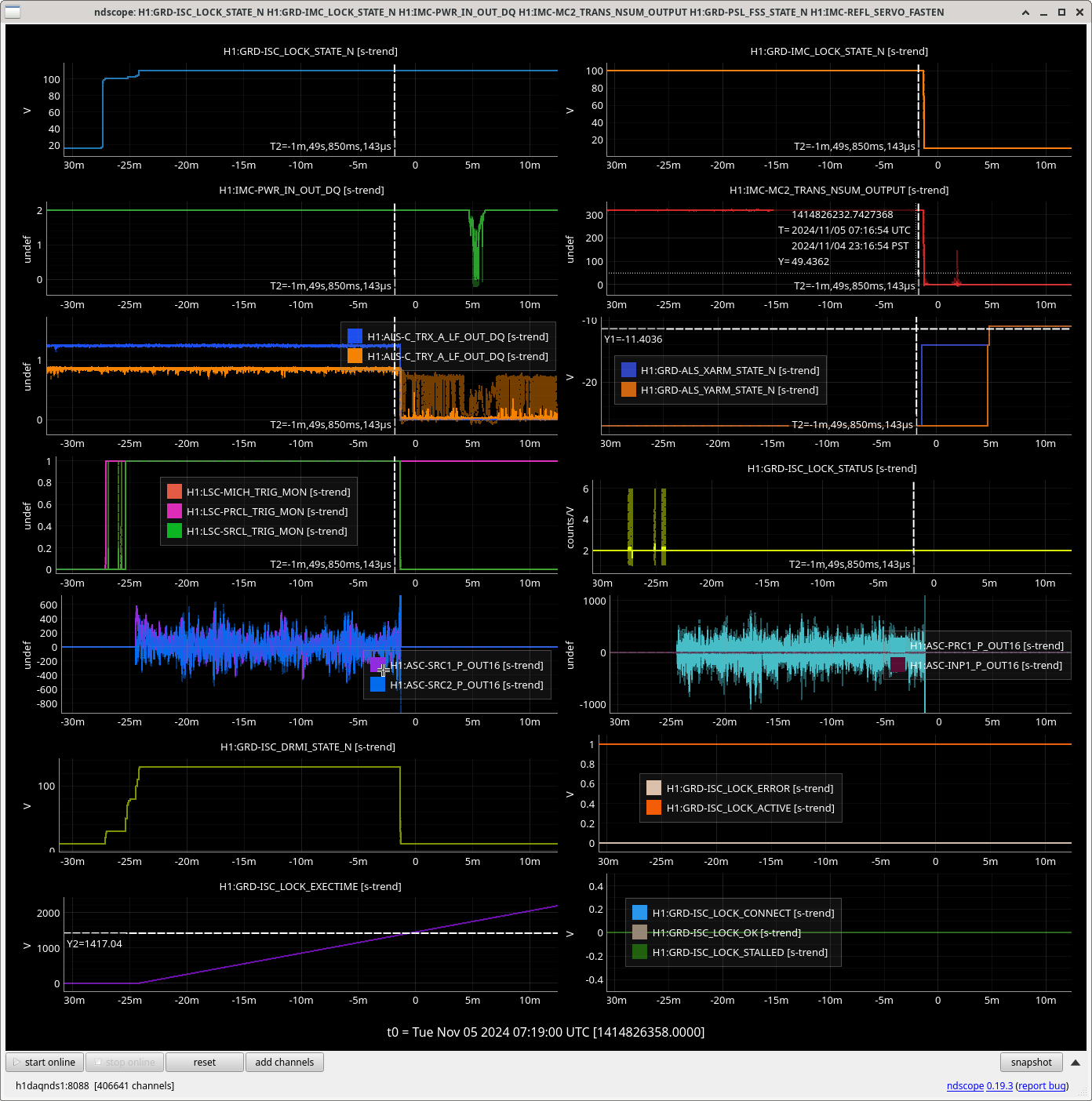
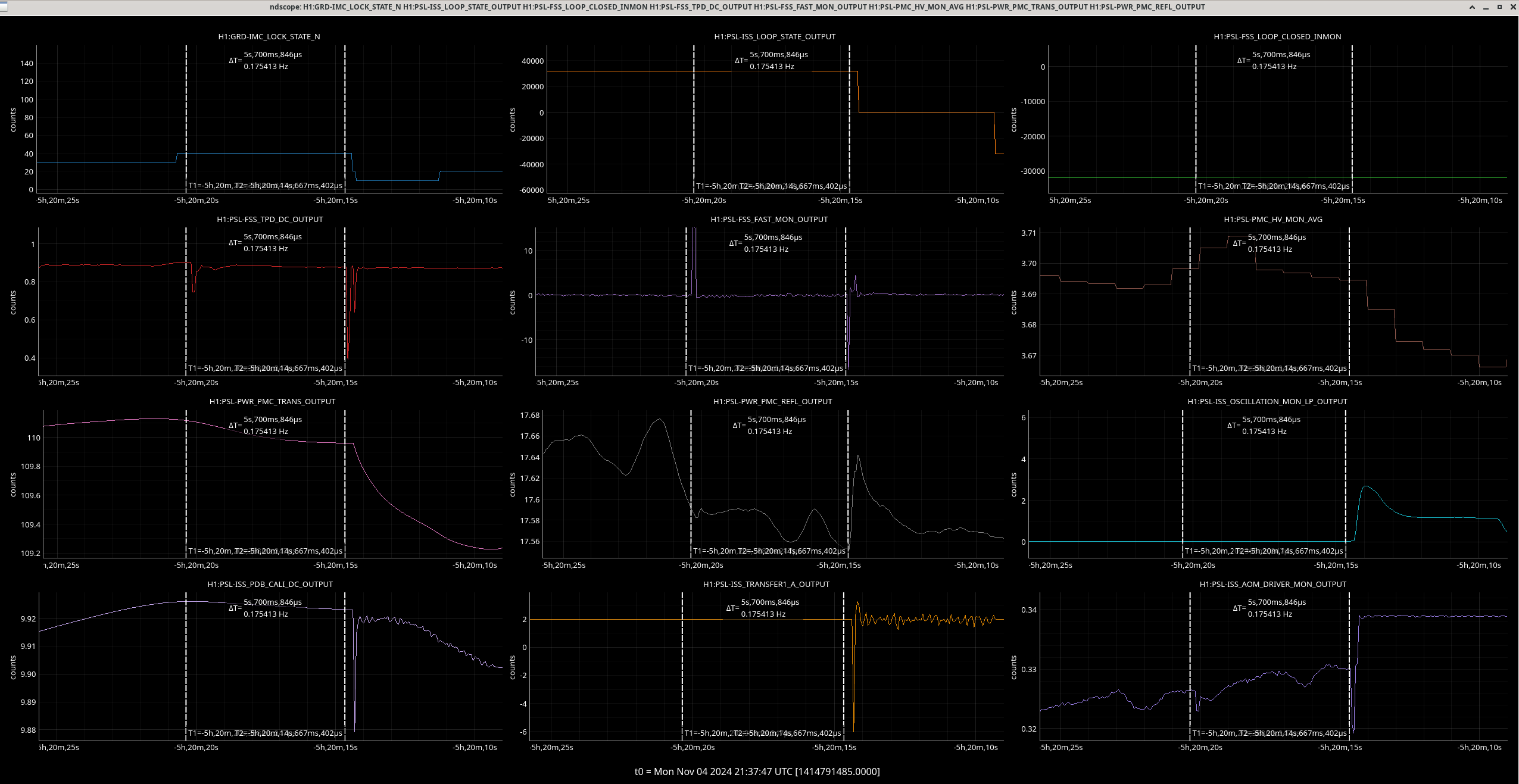
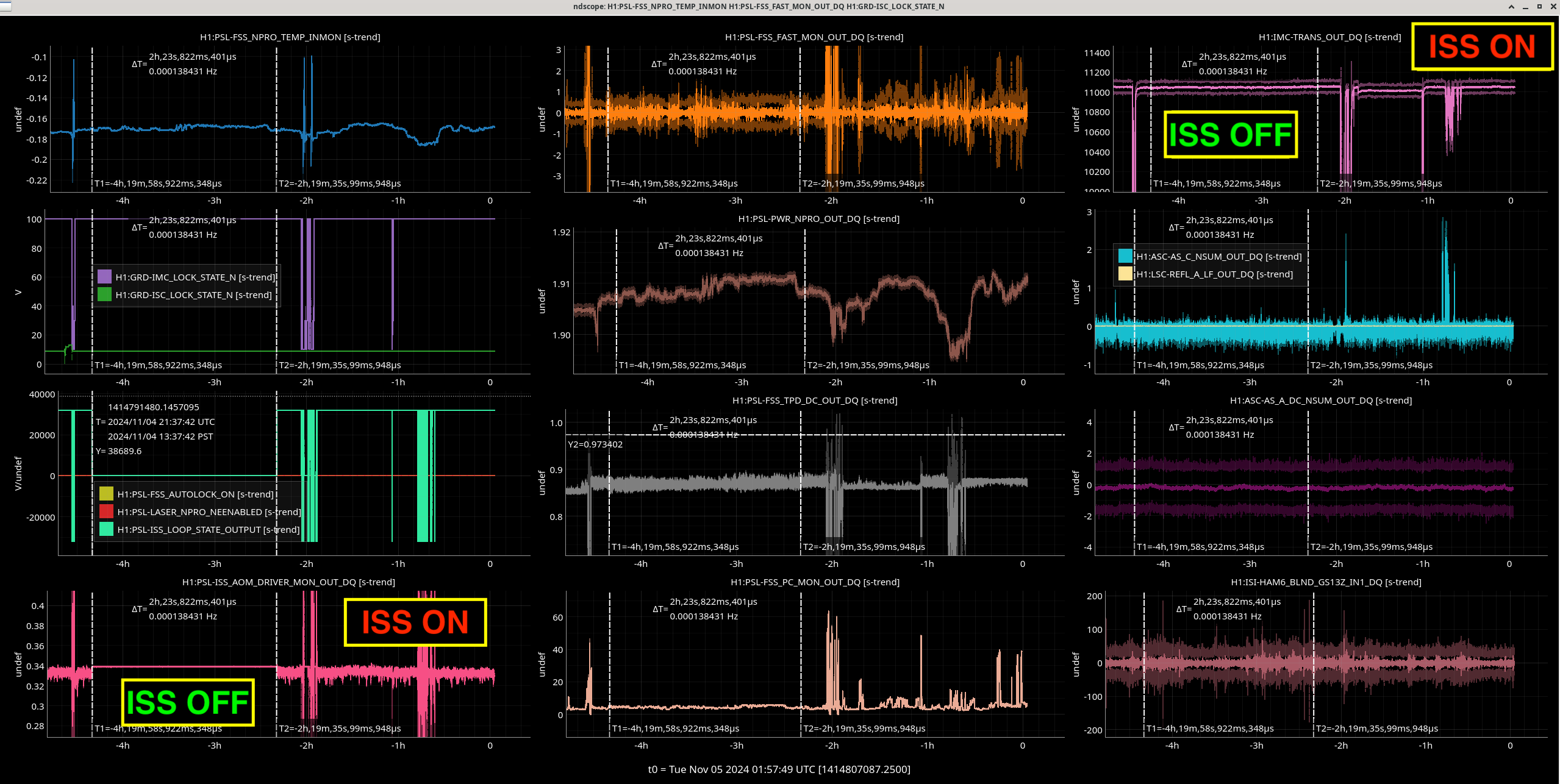
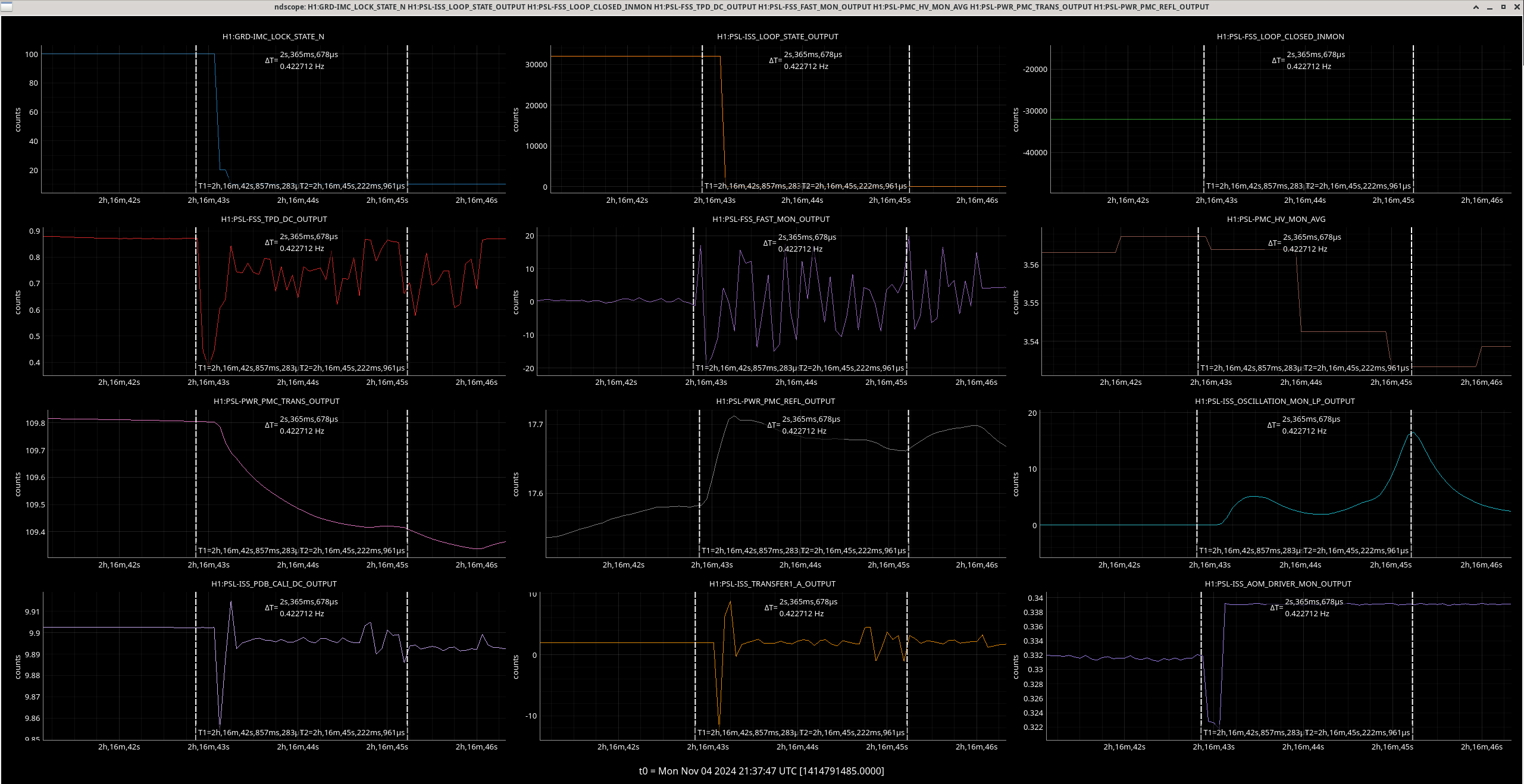
Img 2: M3 and M2 stages of MC2 showing IMC fault beginning 23:17 as a result of EX saturations (later img). All the way until Ryan C downs IMC at 23:38, which is also when the WD tripped and when I was called.
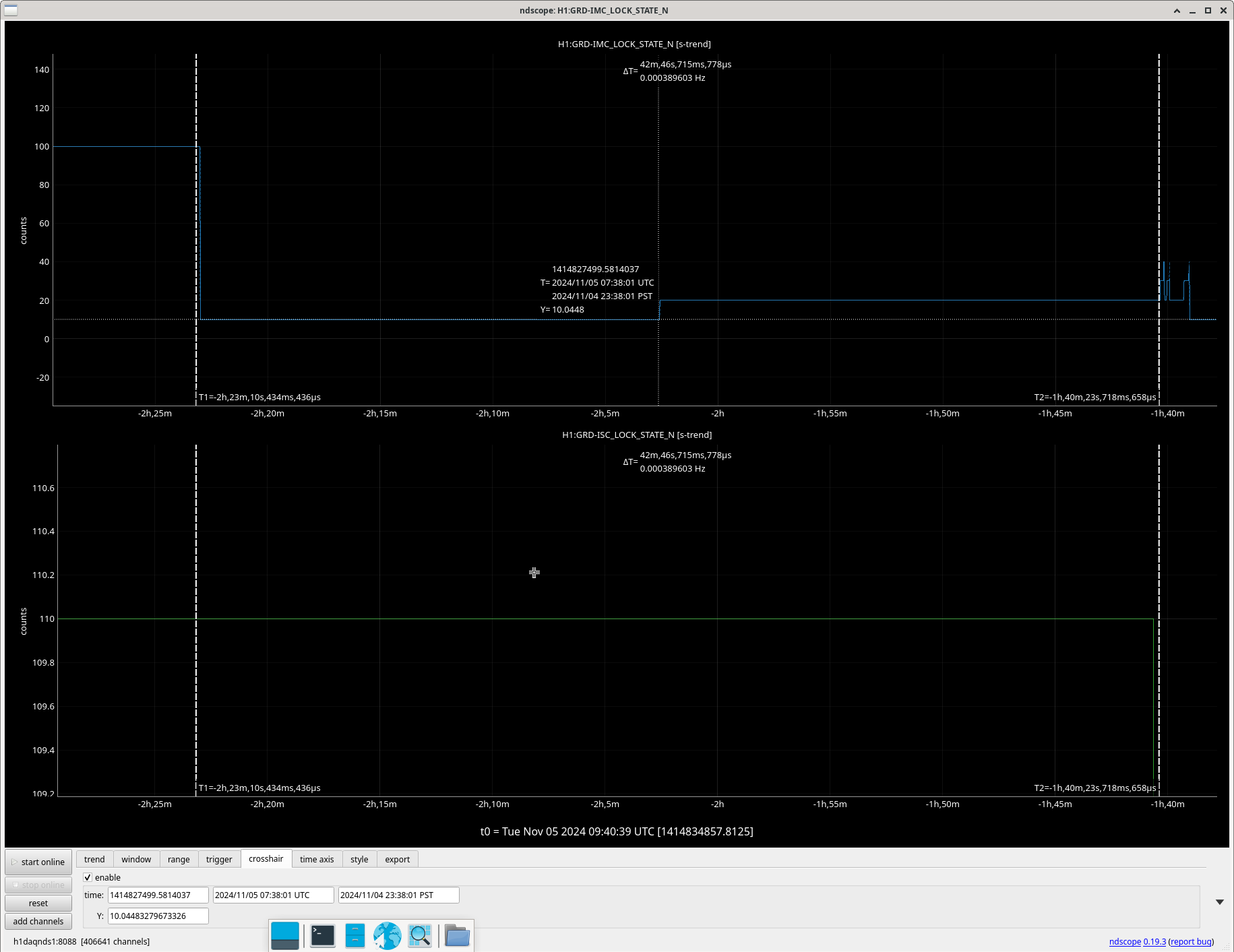
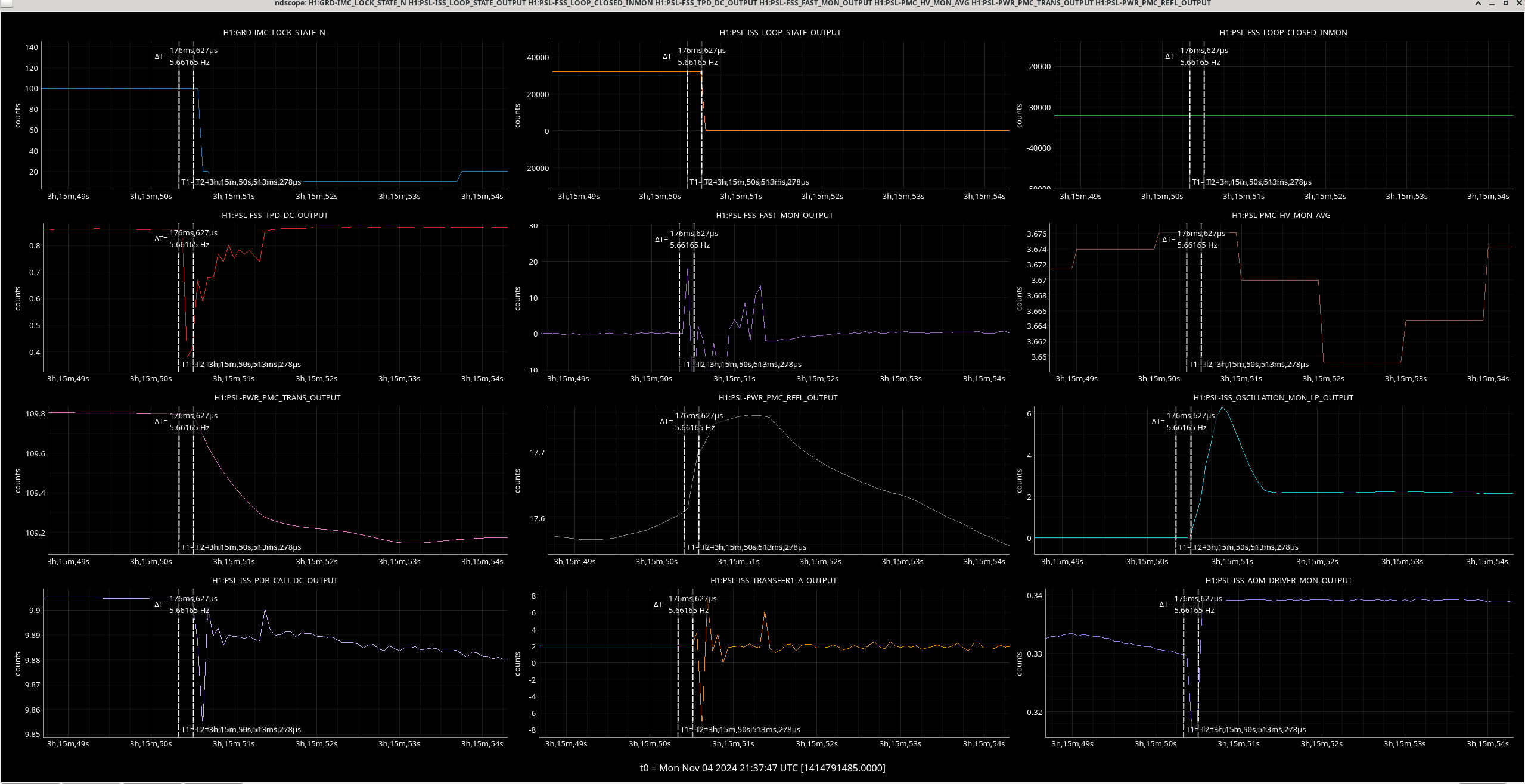
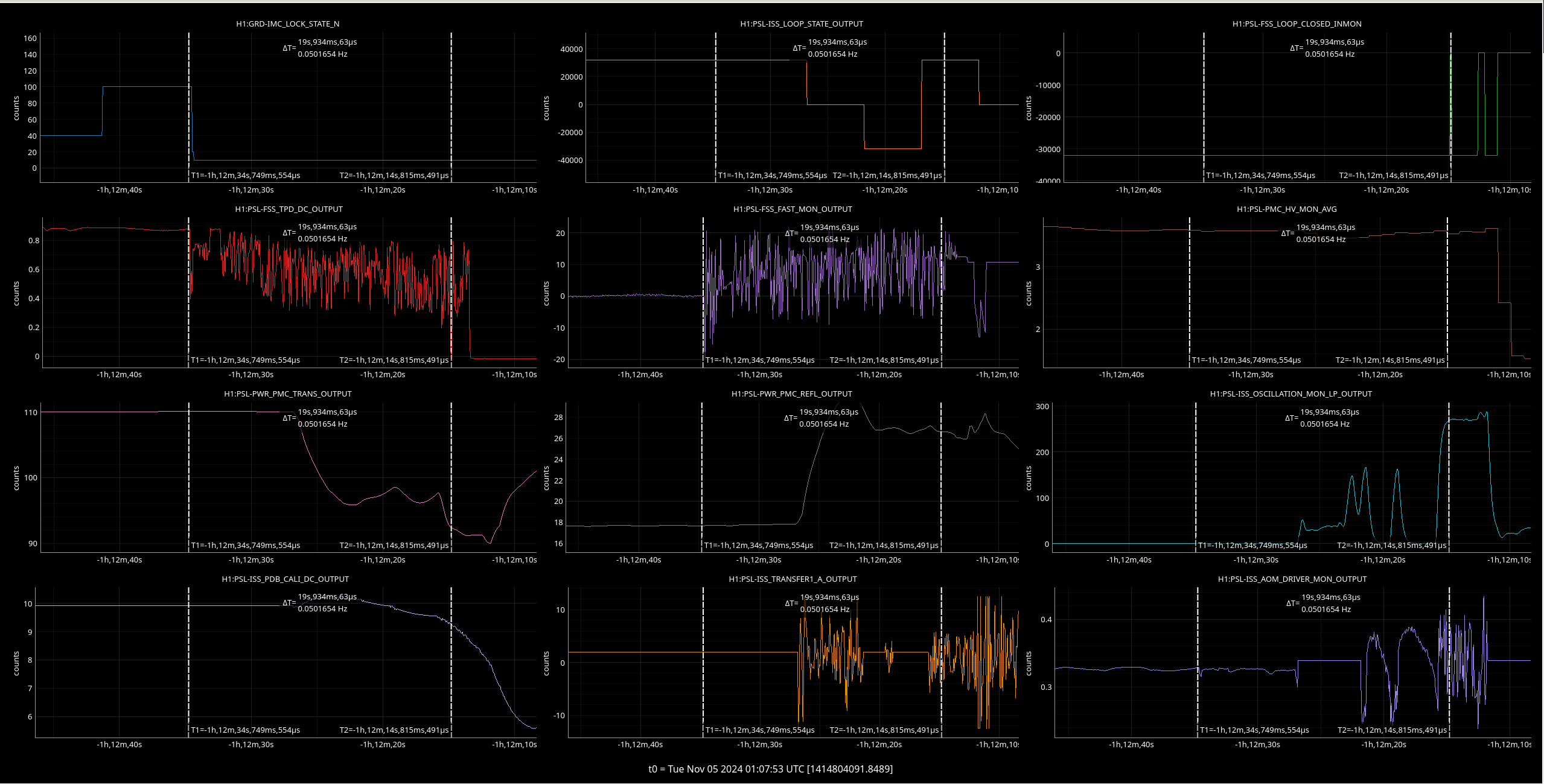
Img 3: IMC lock faulting but NOT causing ISC_LOCK to go to lose lock. This plot shows that guardian did not put IFO in DOWN or cause it to lose lock. IFO is in DRMI_LOCKED_CHECK_ASC but IMC is faulting. Even when Ryan C downed the IMC (which is where the crosshair is), this did not cause a ISC to go to DOWN. The end time axis is when Ryan C put IFO in INIT, finally causing a Lockloss and ending the railing in EX (00:00).
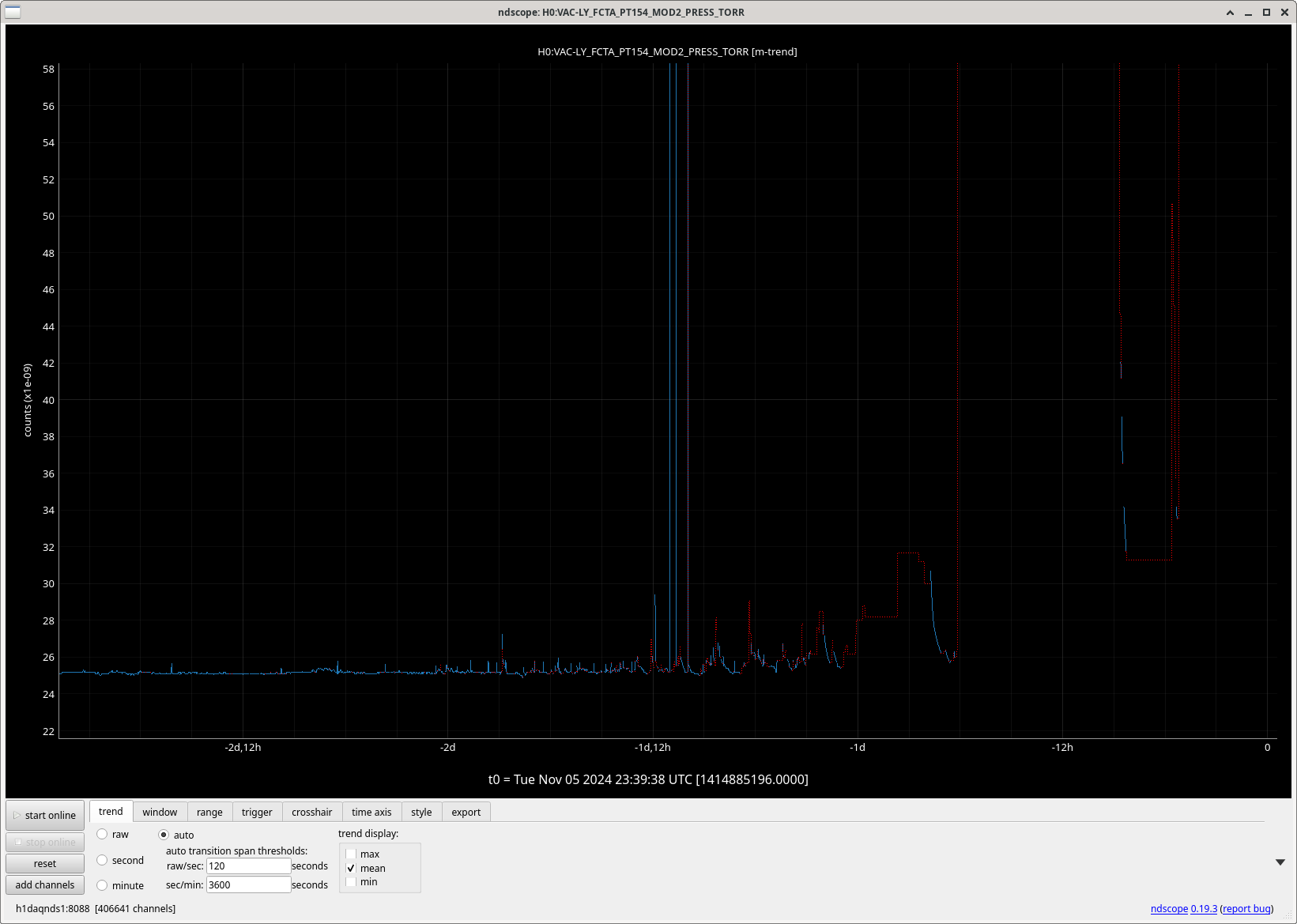
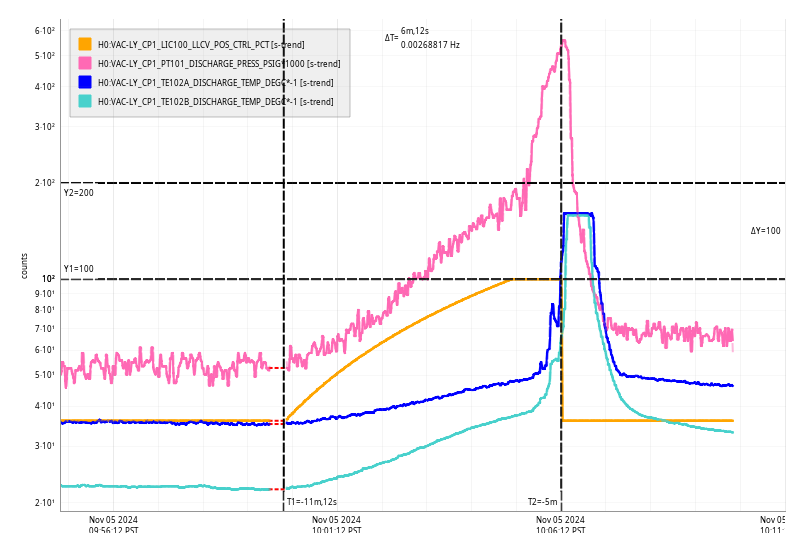
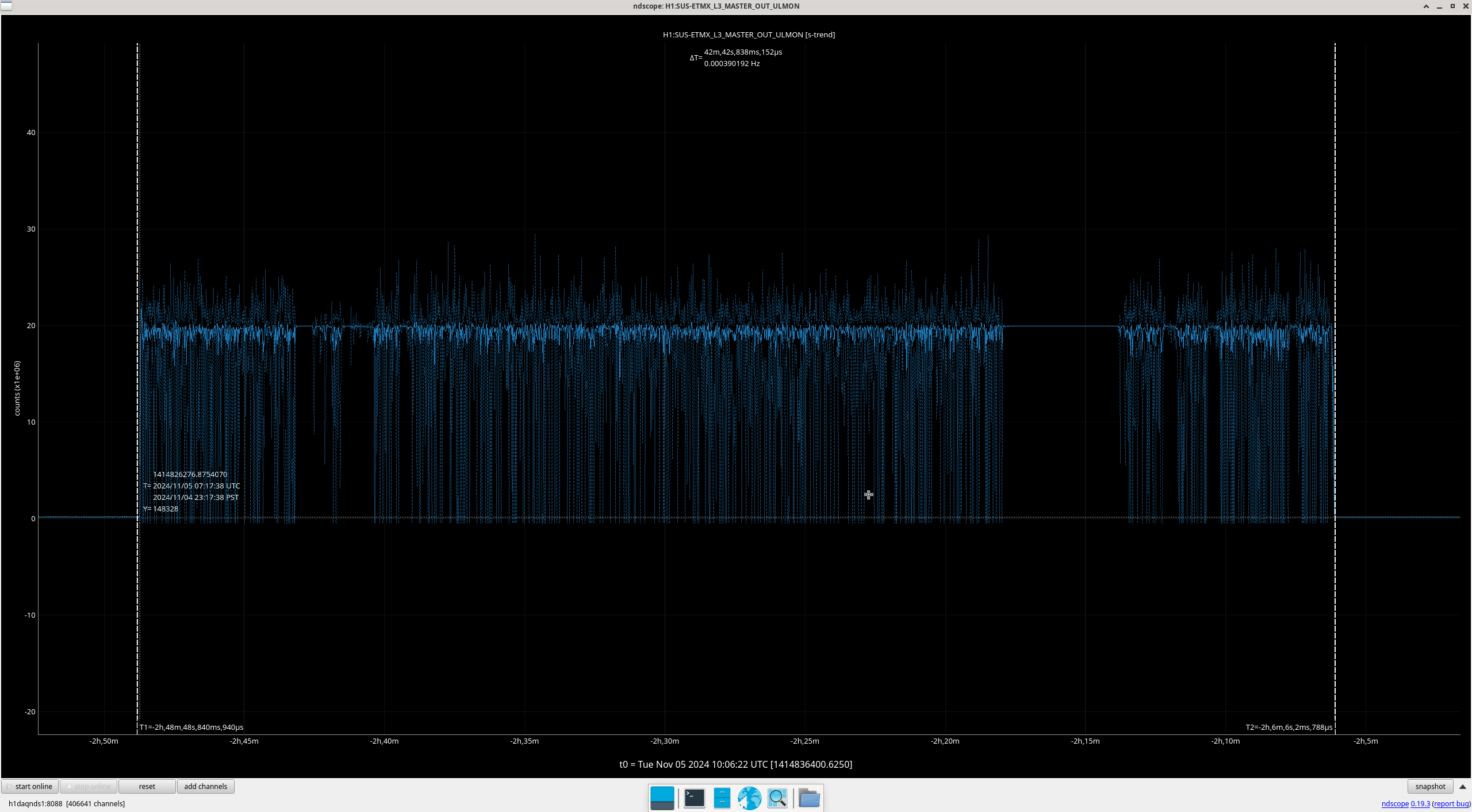
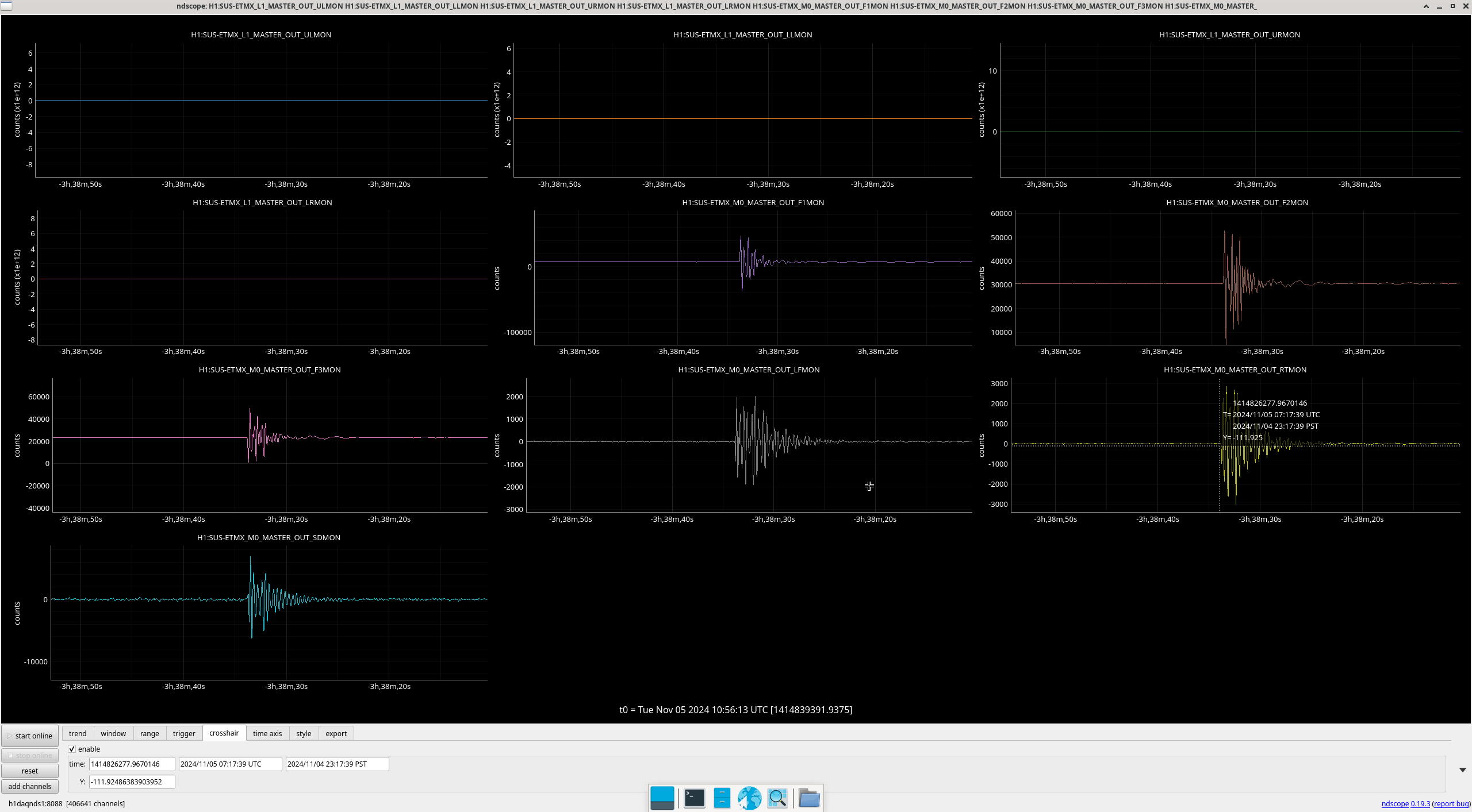
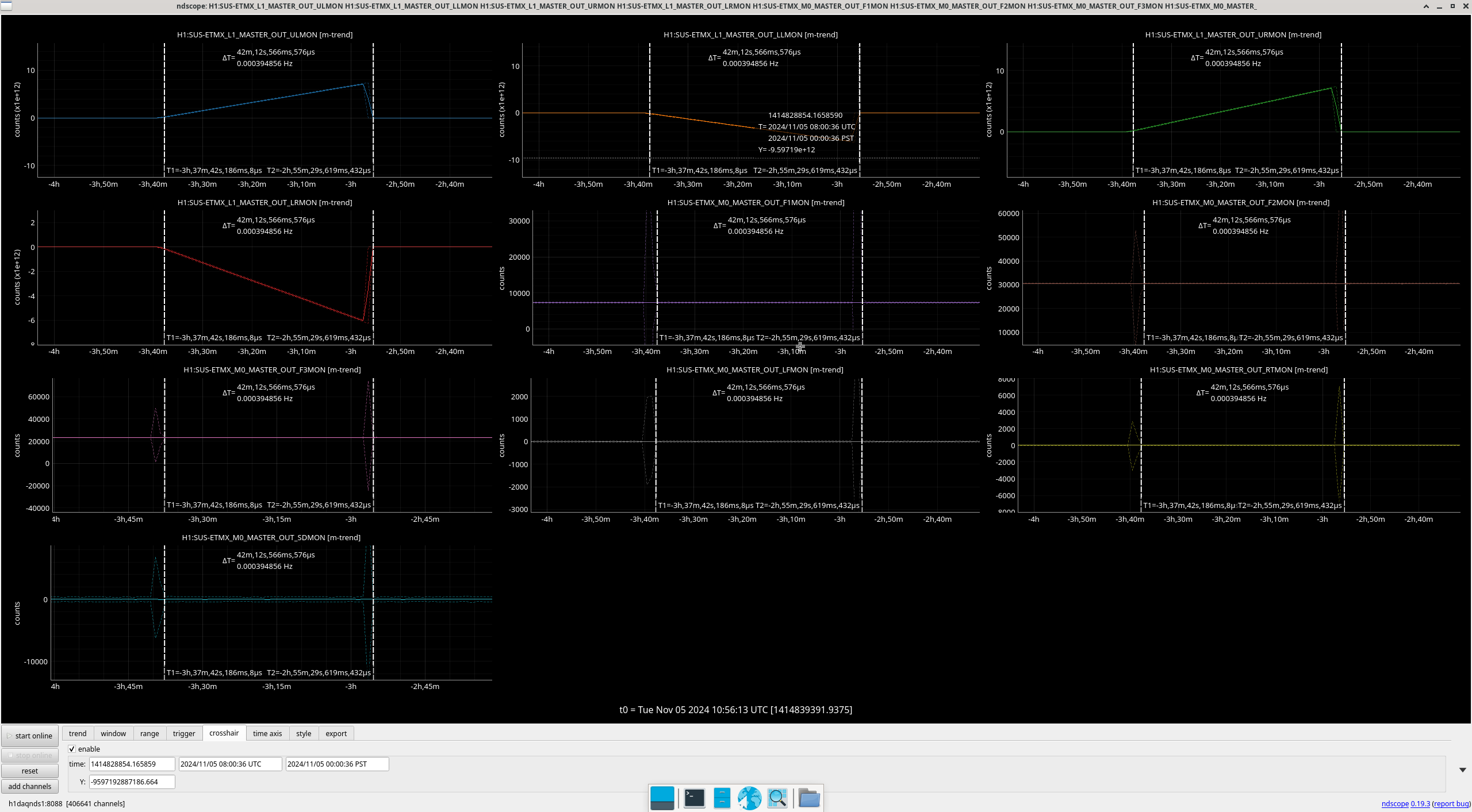
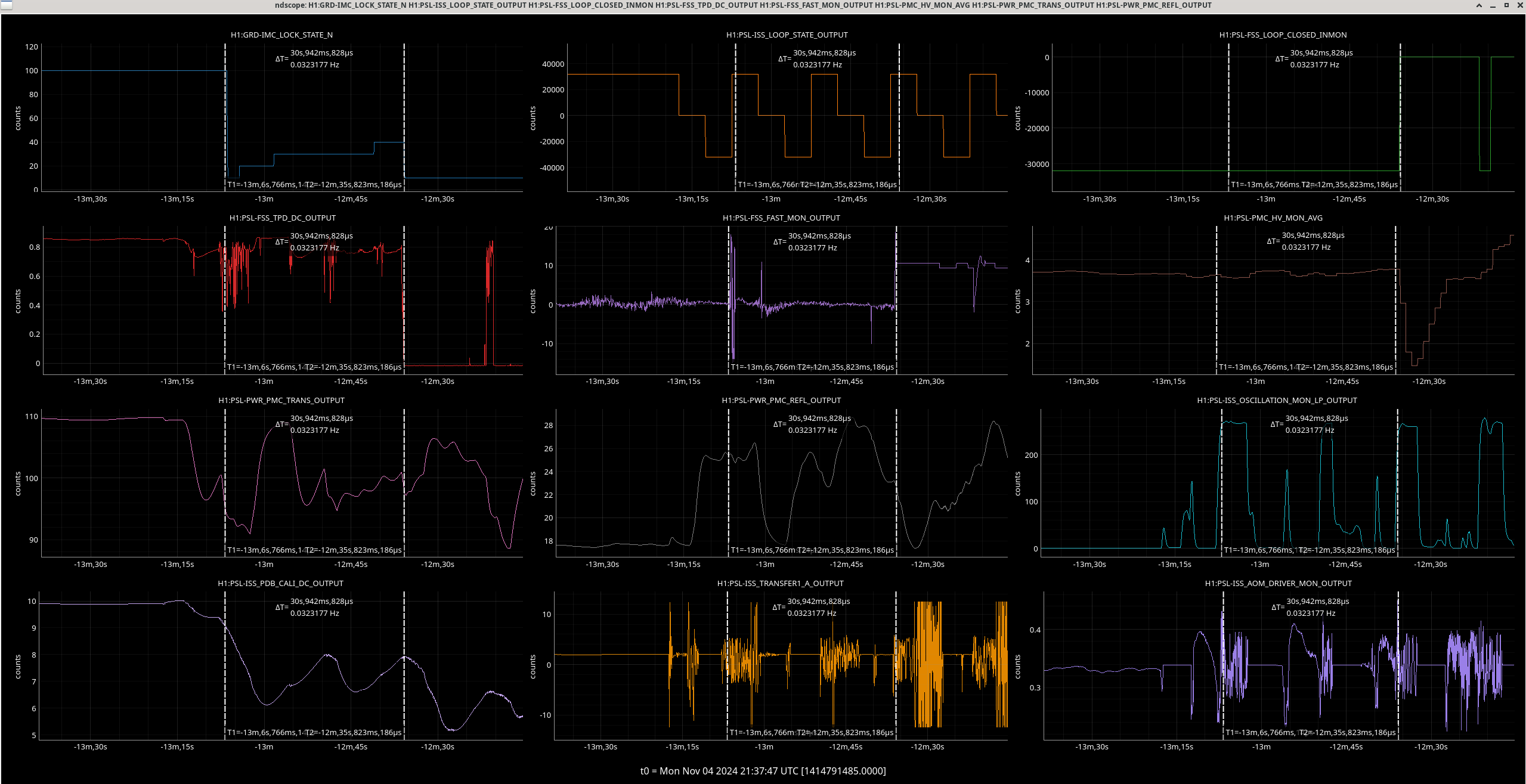
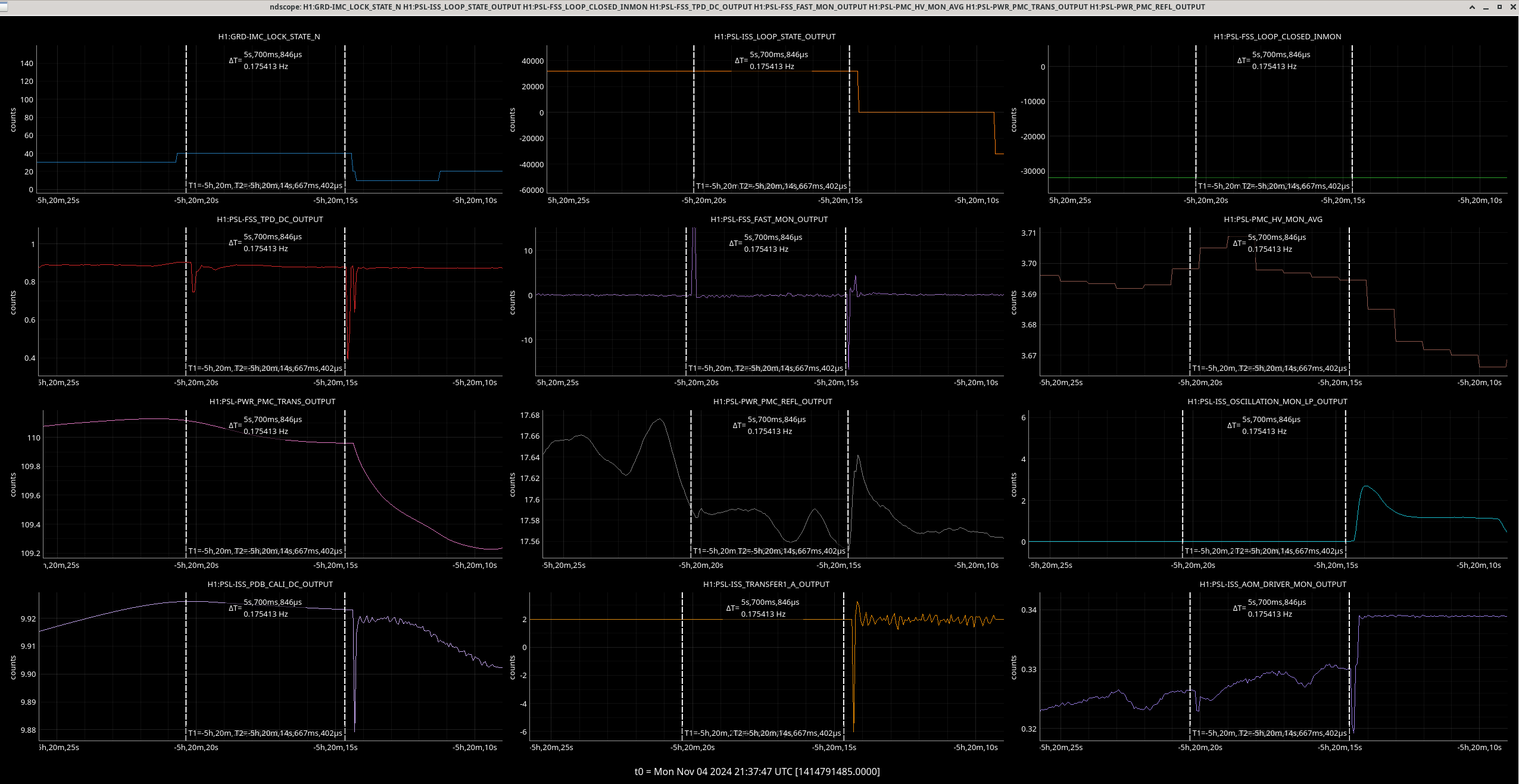
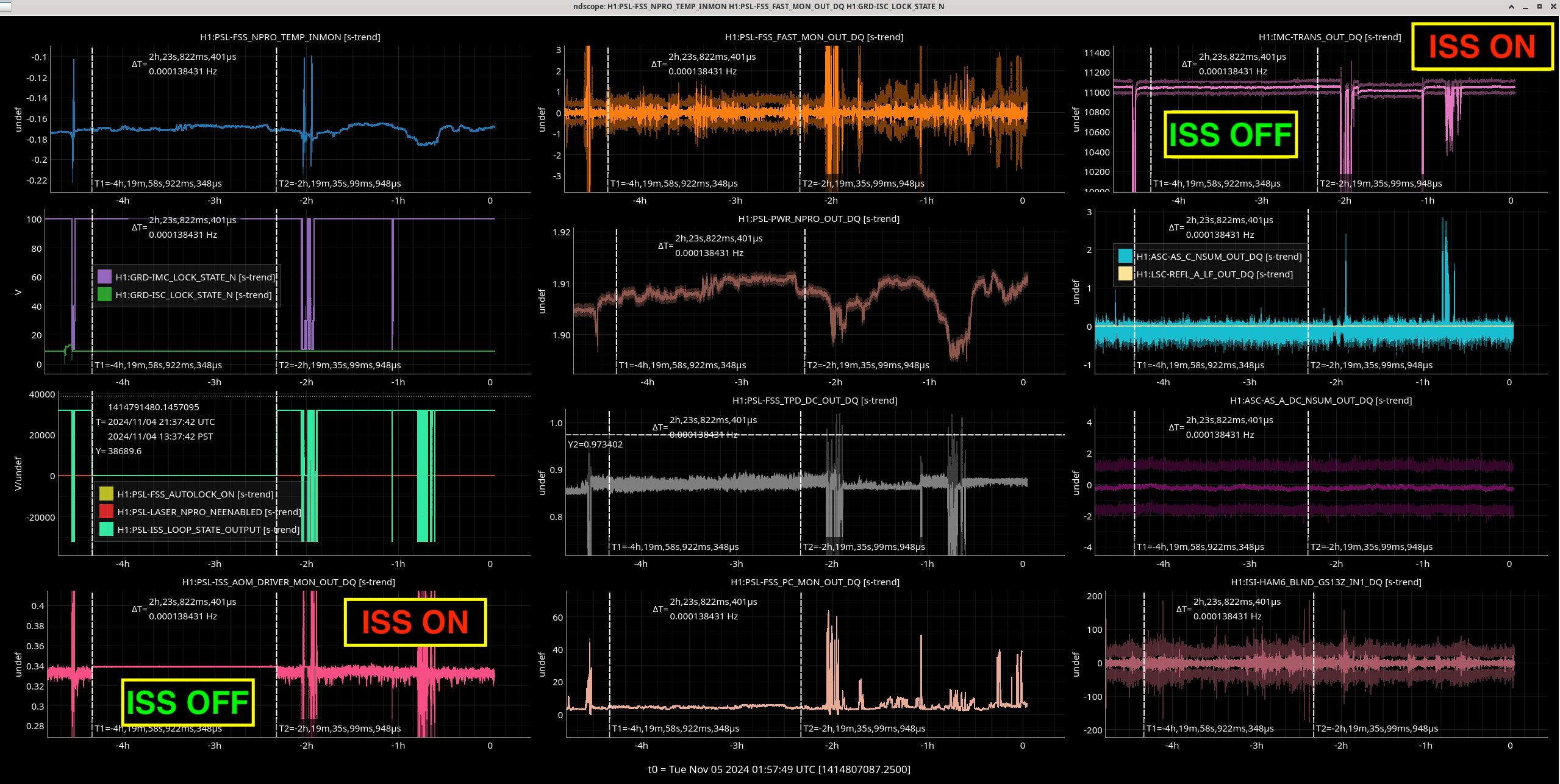
Img 4: EX railing for 42 minutes straight, from 23:17 to 00:00.
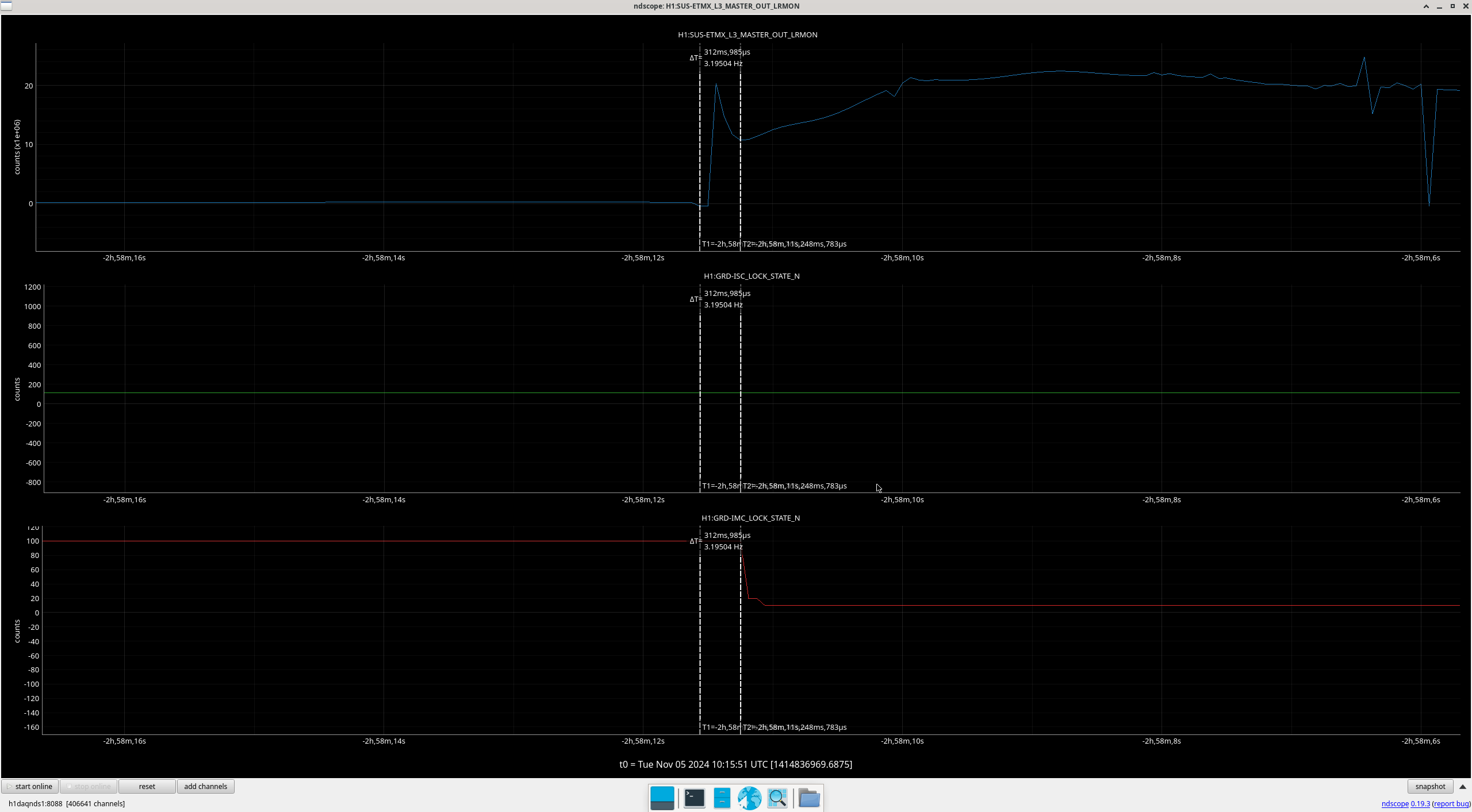
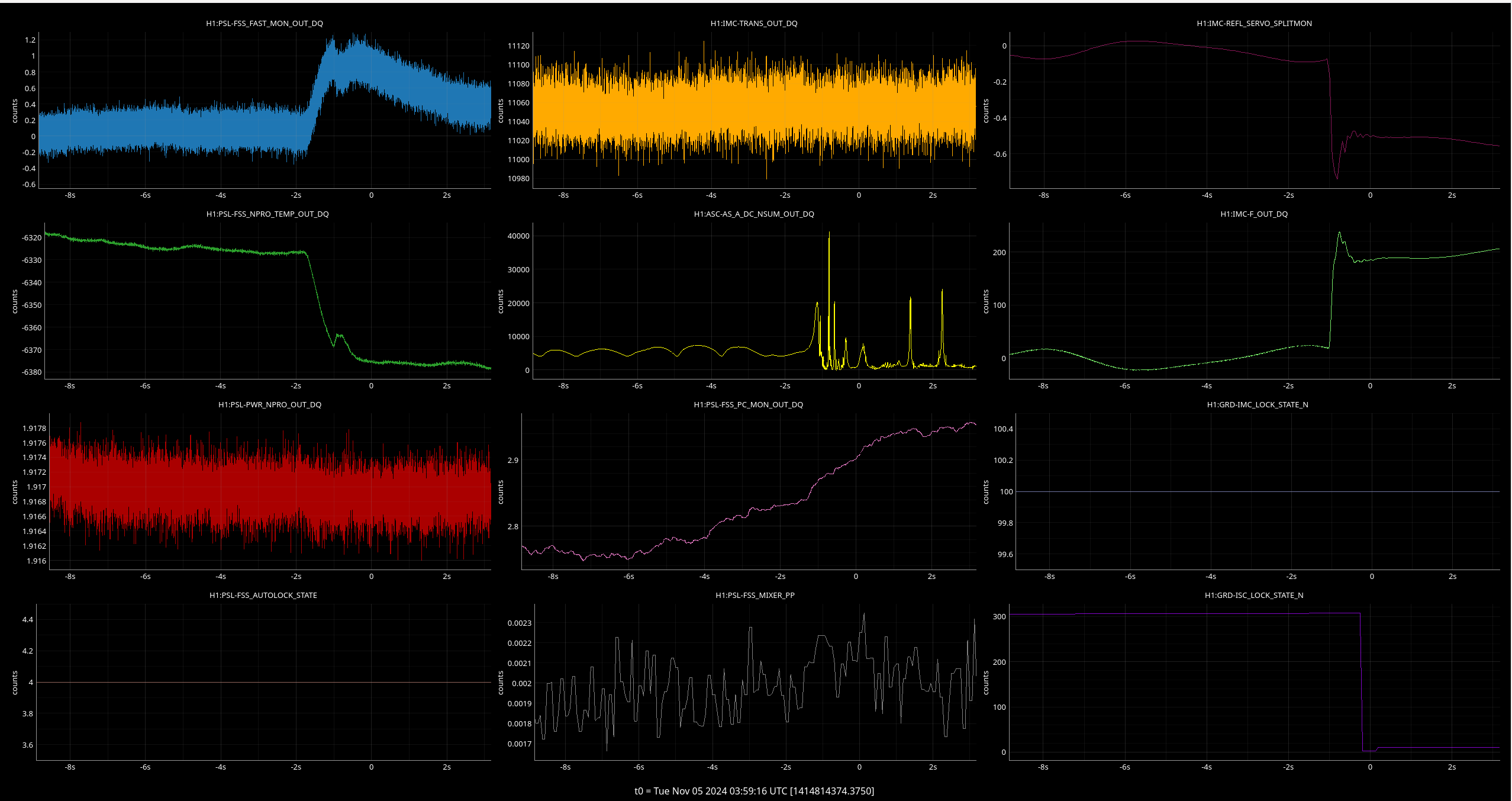
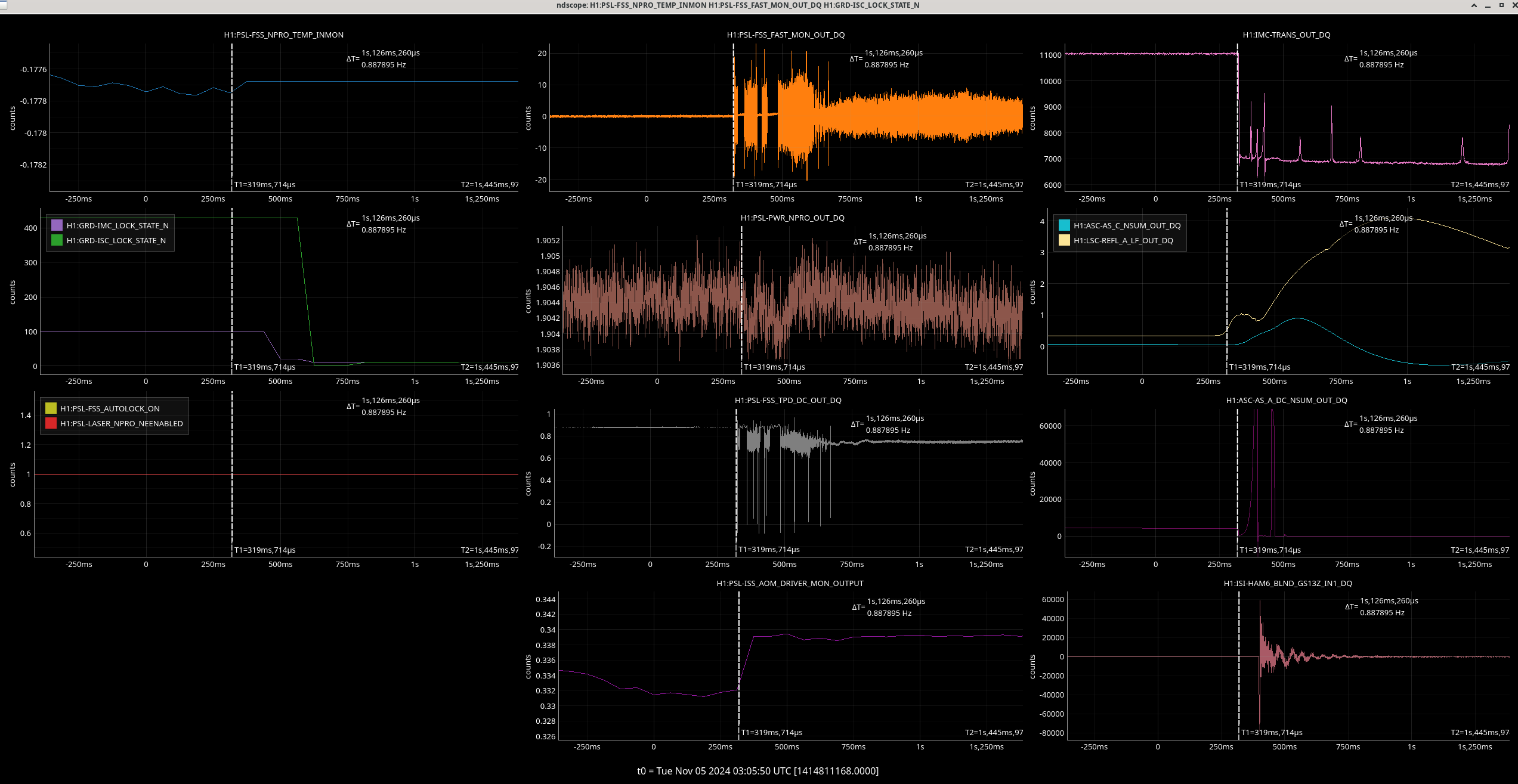
Img 5: Ex beginning to rail 300ms before IMC faults.
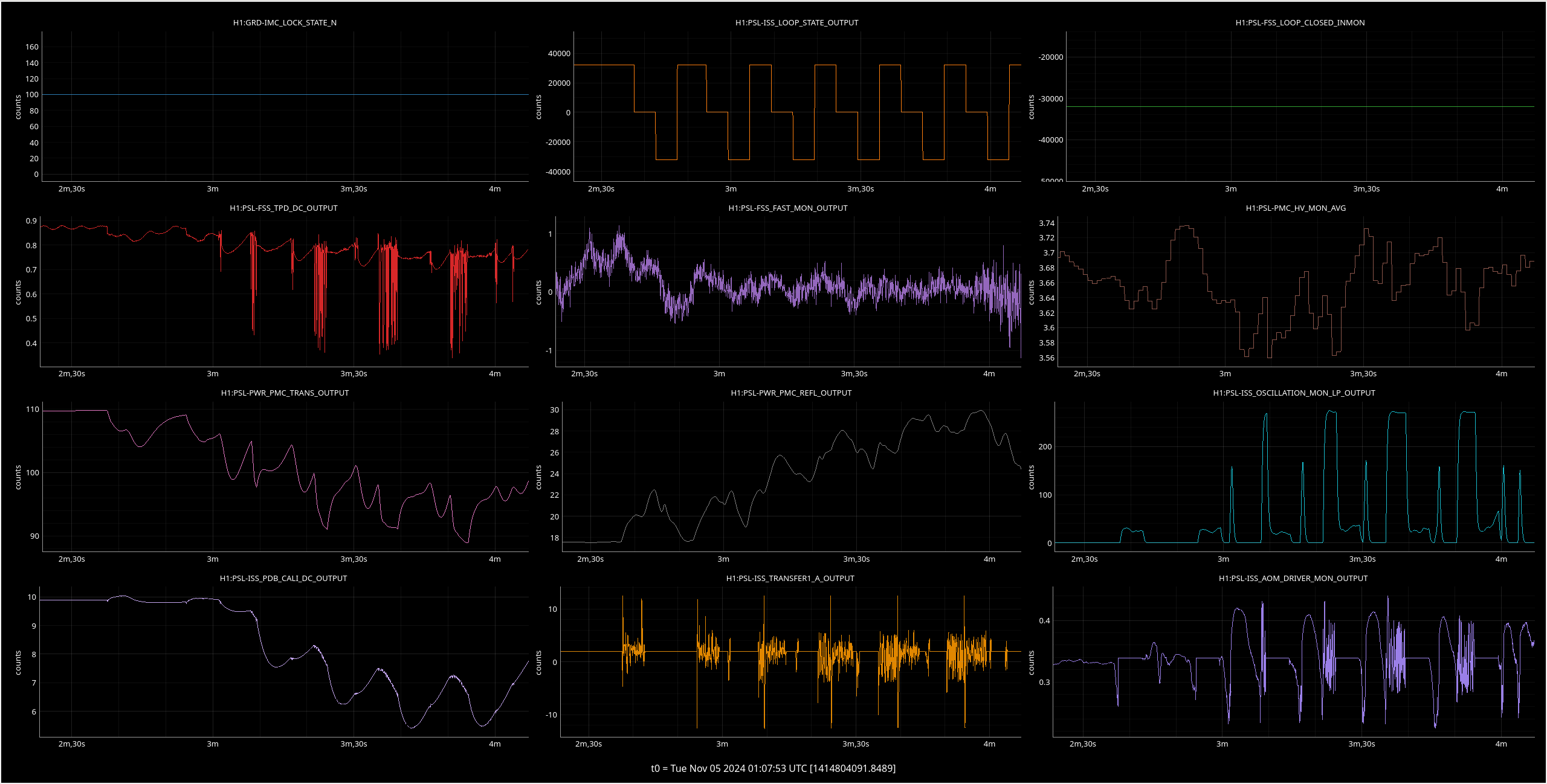
Img 6: EX L2 and L3 OSEMs at the time of the saturation. Interestingly, L2 doesn’t saturate but before the saturation, there is erratic behavior. Once this noisy signal stops, L3 saturates.
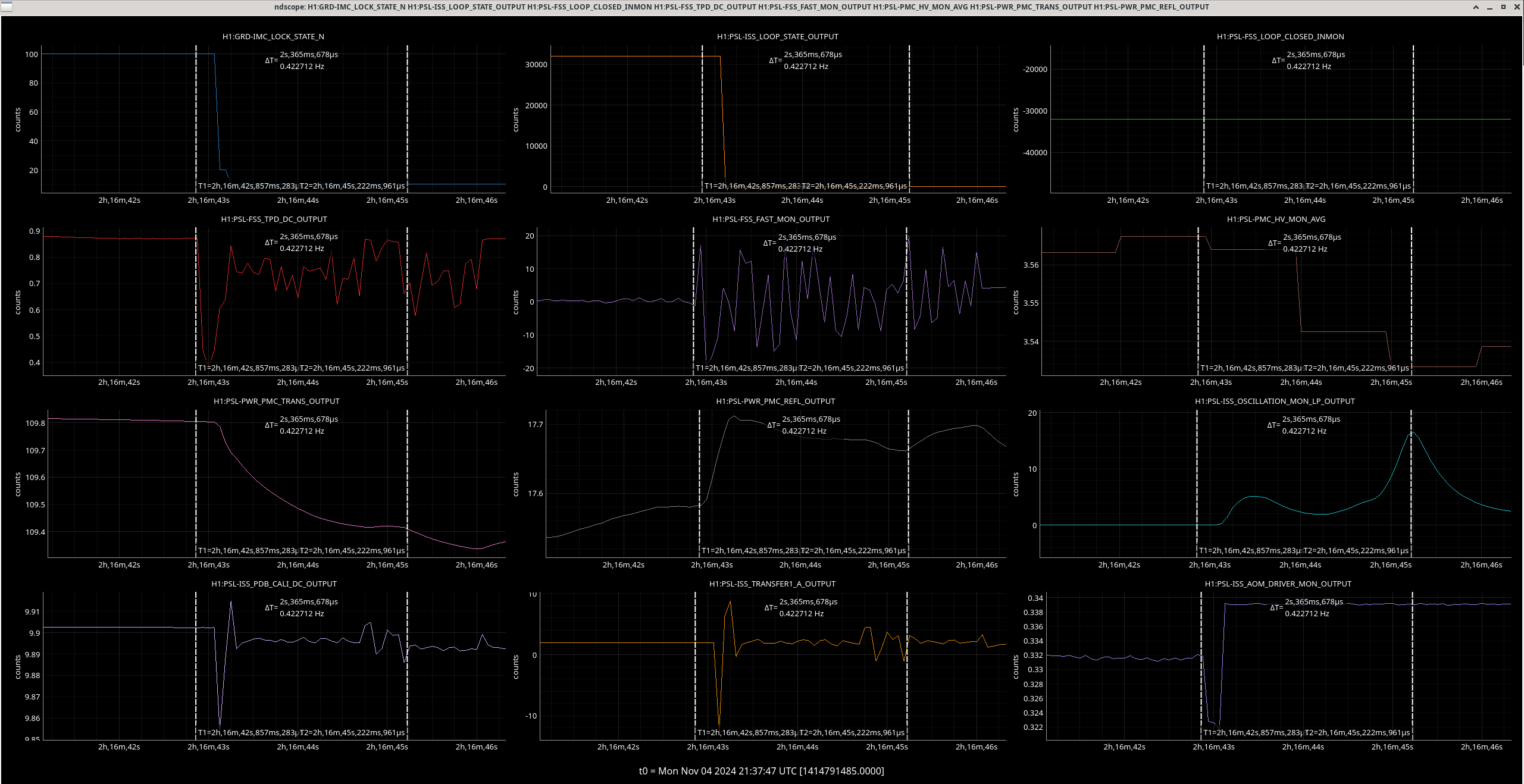
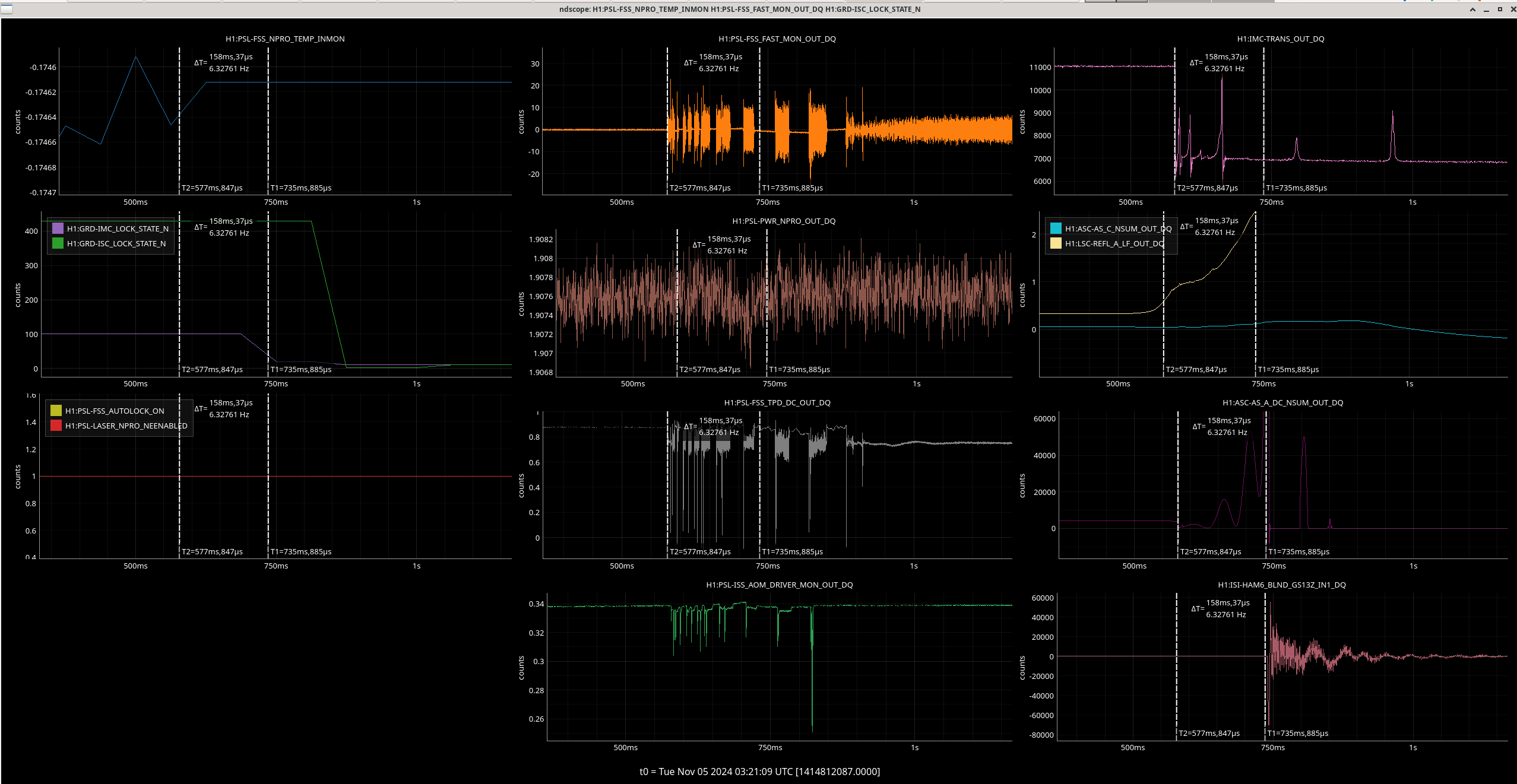
Img 7: EX L1 and M0 OSEMs at the time of the saturation, zoomed in. It seems that there is a noisy and loud signal, (possibly a glitch or due to microseism?) in the M0 stage that is very short which may have kicked off this whole thing.
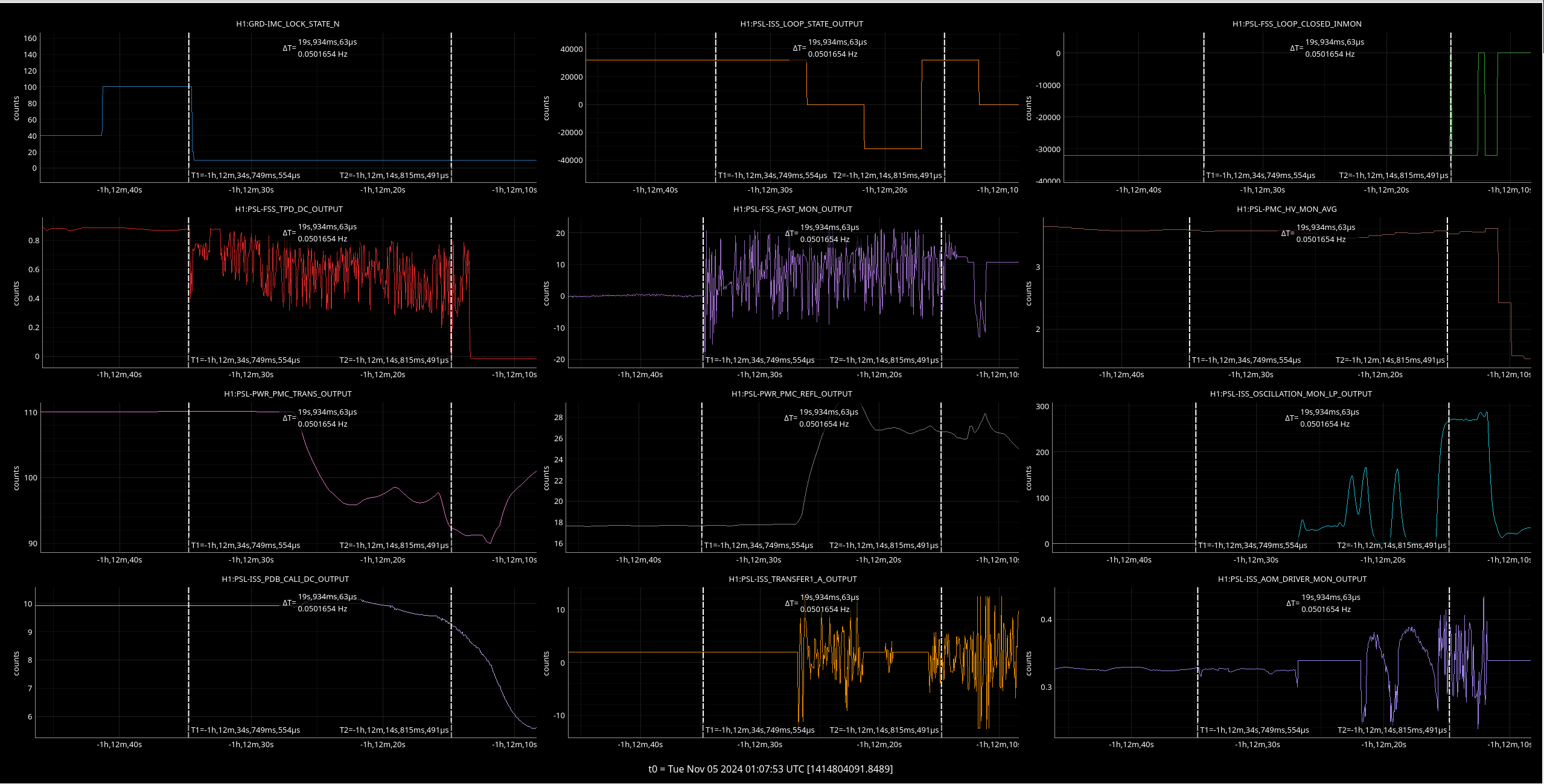
Img 8: EX L1 and M0 OSEMs at the whole duration of saturation. We can see the moves that L1 took throughout the 42 minutes of railing, and the two kicks when the railing started and stopped.
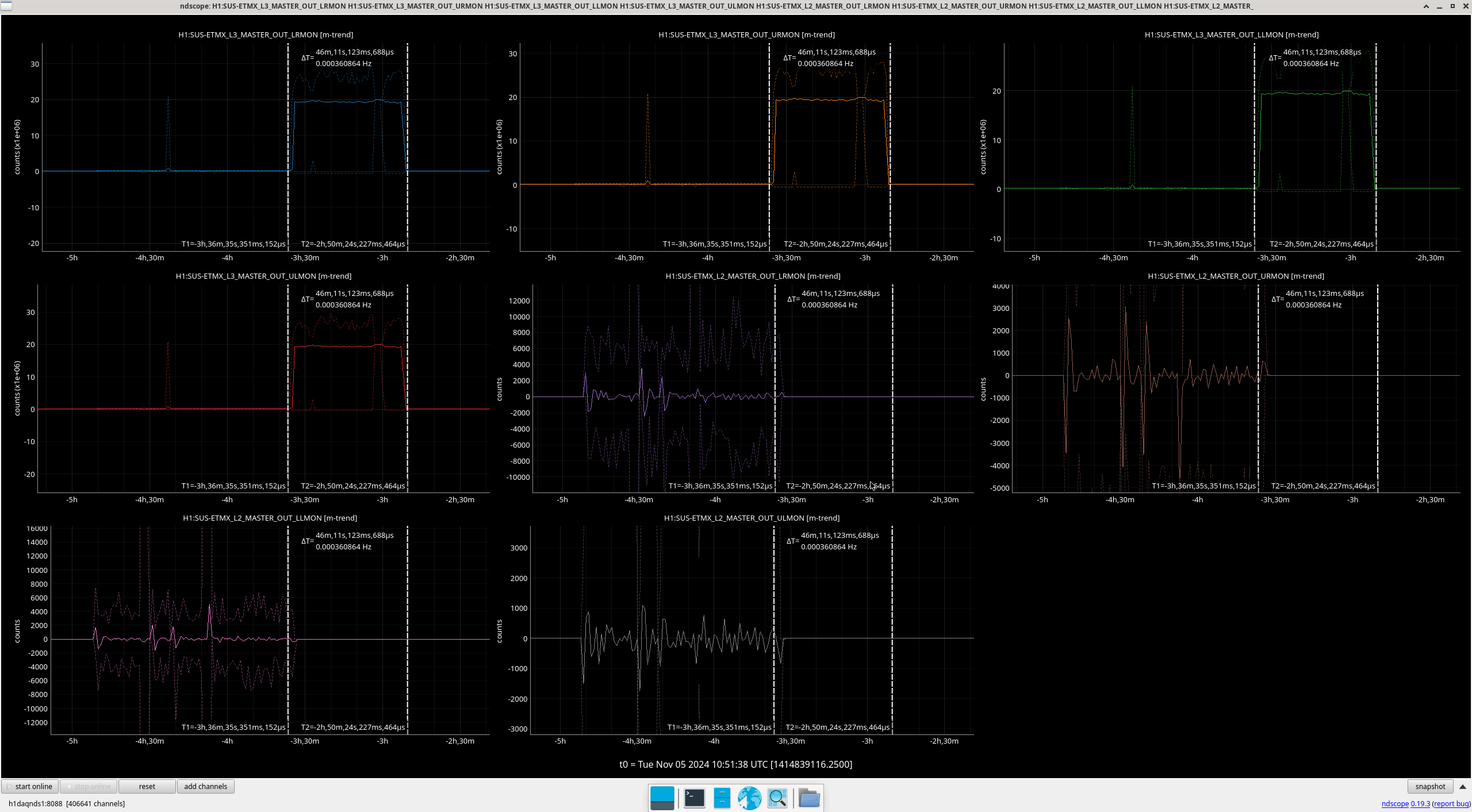
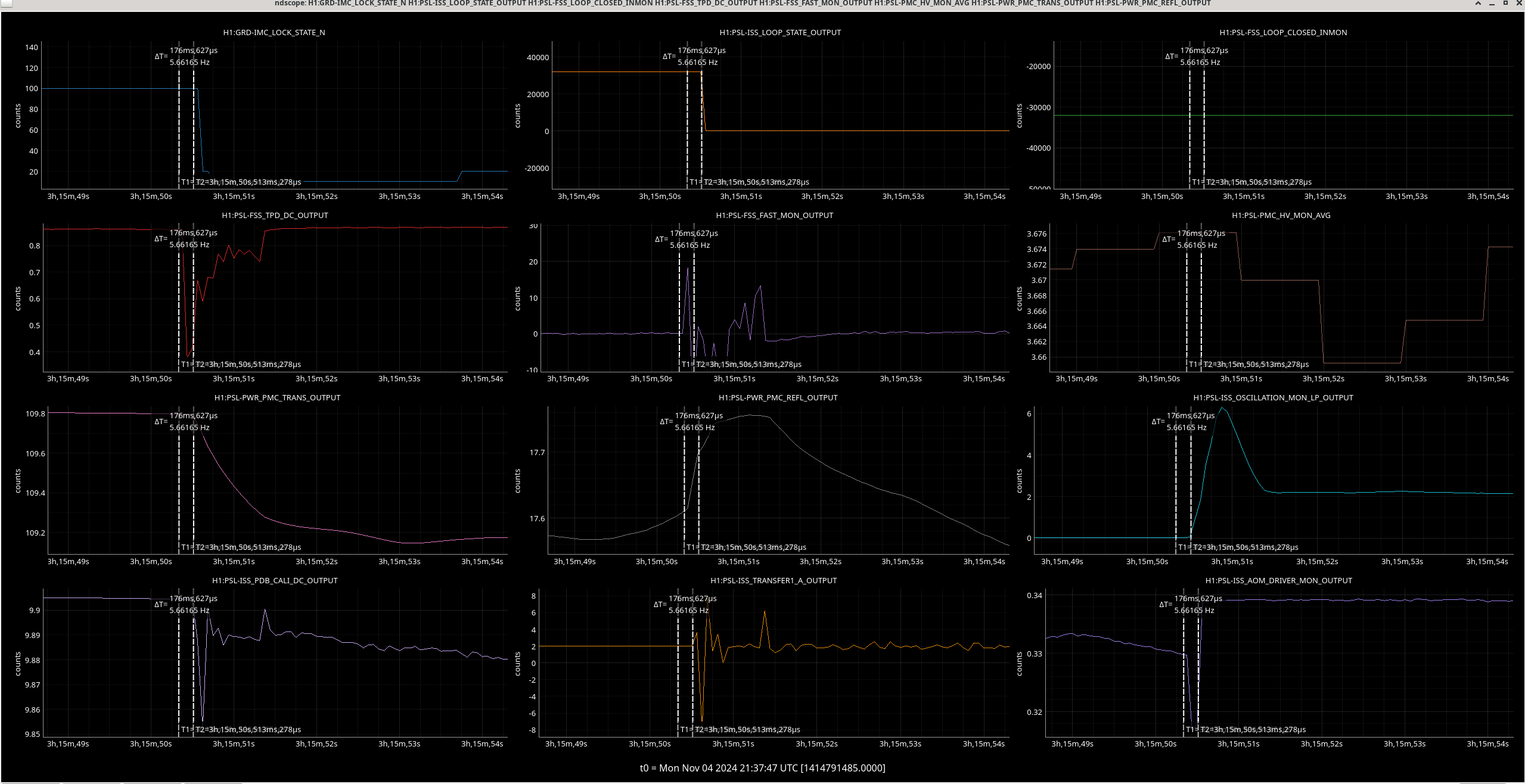
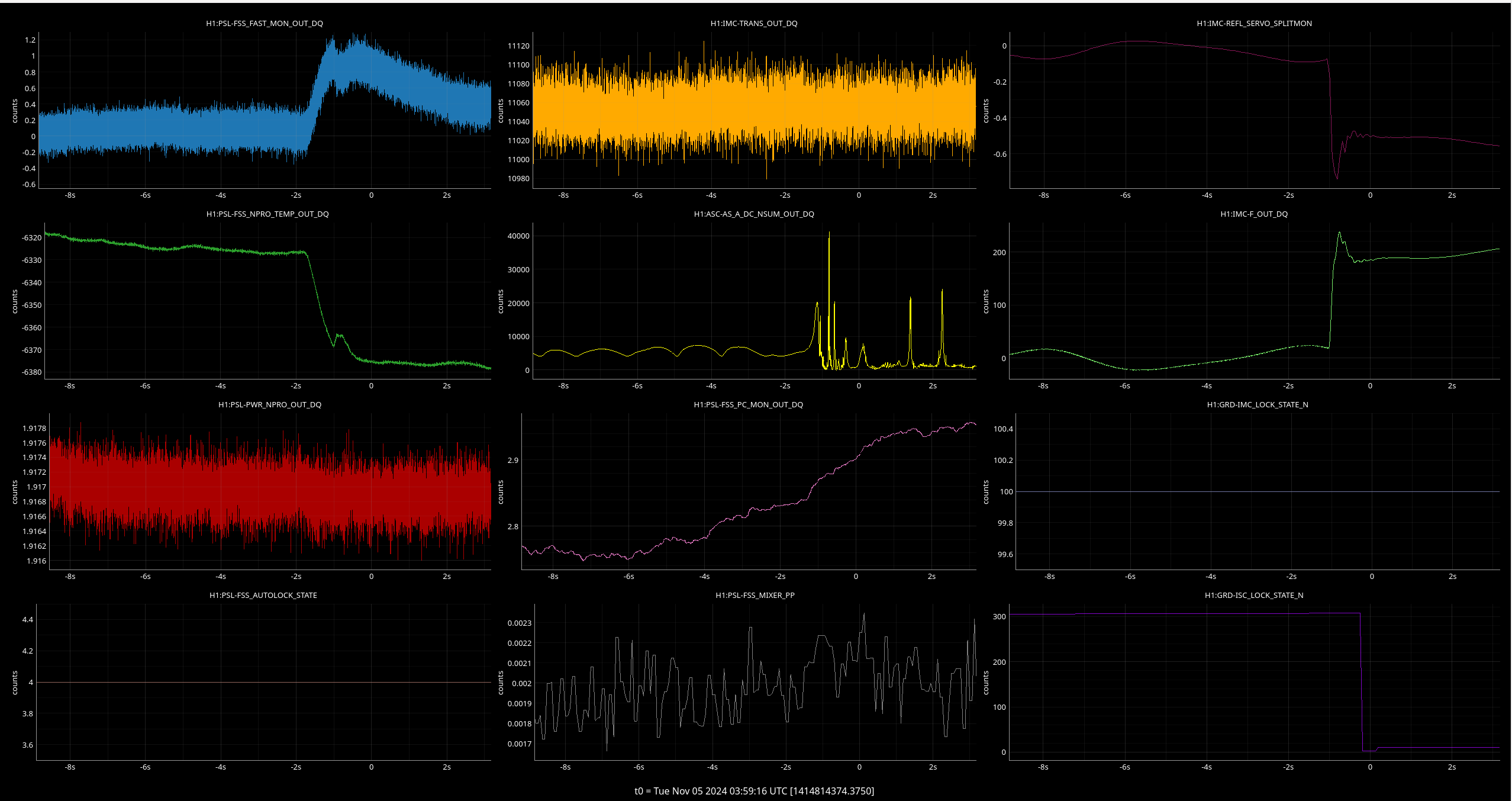
Img 9 and 10: An OSEM from each stage of ETMX, including one extra from M0 (since signals were differentially noisy). Img 9 is zoomed in to try to capture what started railing first. Img 10 shows the whole picture with L3’s railing. I don’t know what to make of this.
Further investigation:
See what else may have glitched or lost lock first. Ryan C’s induced lockloss, saving the constant EX railing doesn’t seem to show up under the LL tool, so this would have to be done in order of likely suspects. I’ve never seen this behavior before what this was if anyone else has.
Other:
Ryan’s post EVE update: alog 81061
Ryan’s EVE Summary: alog 81057


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}