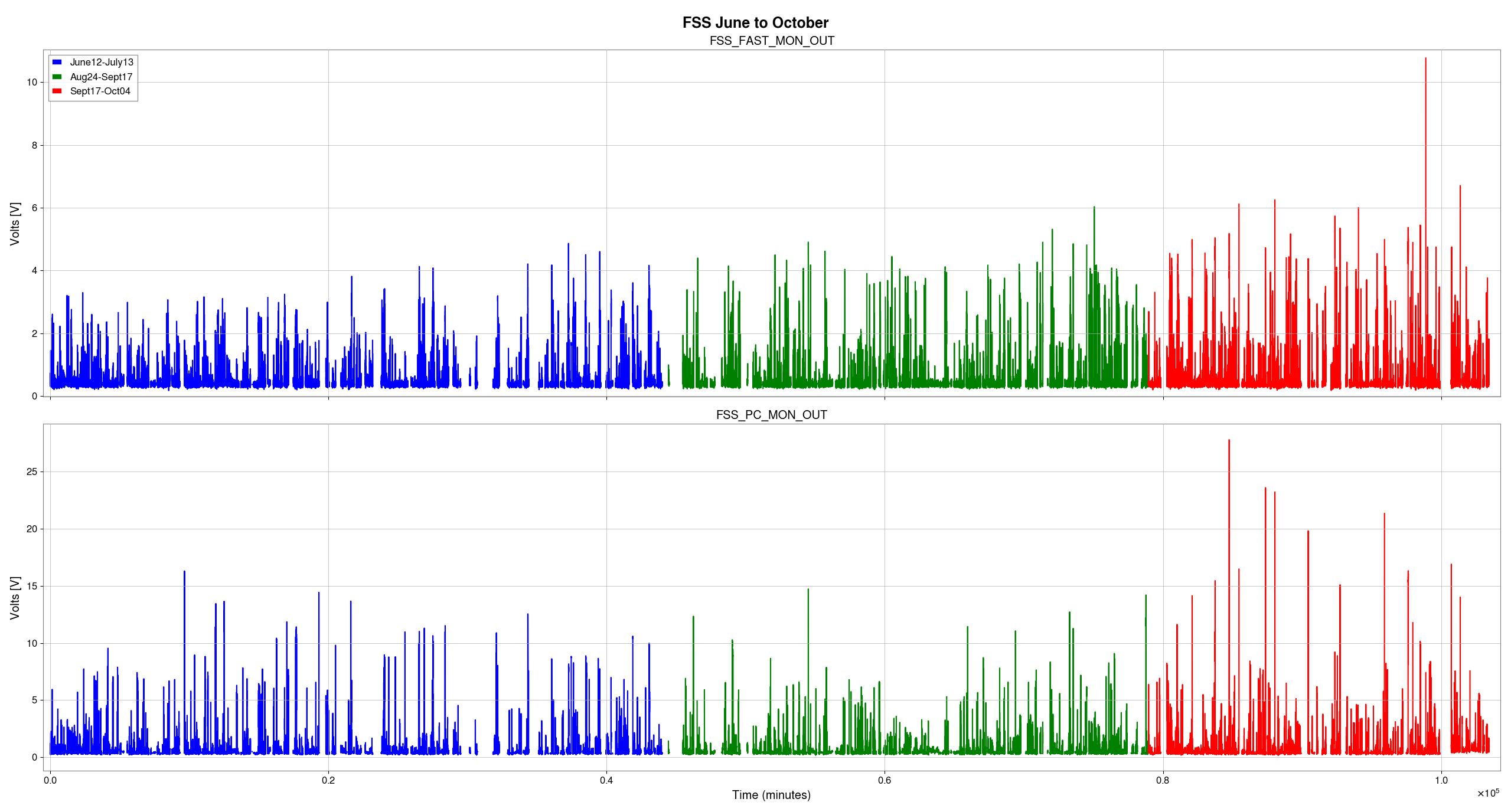
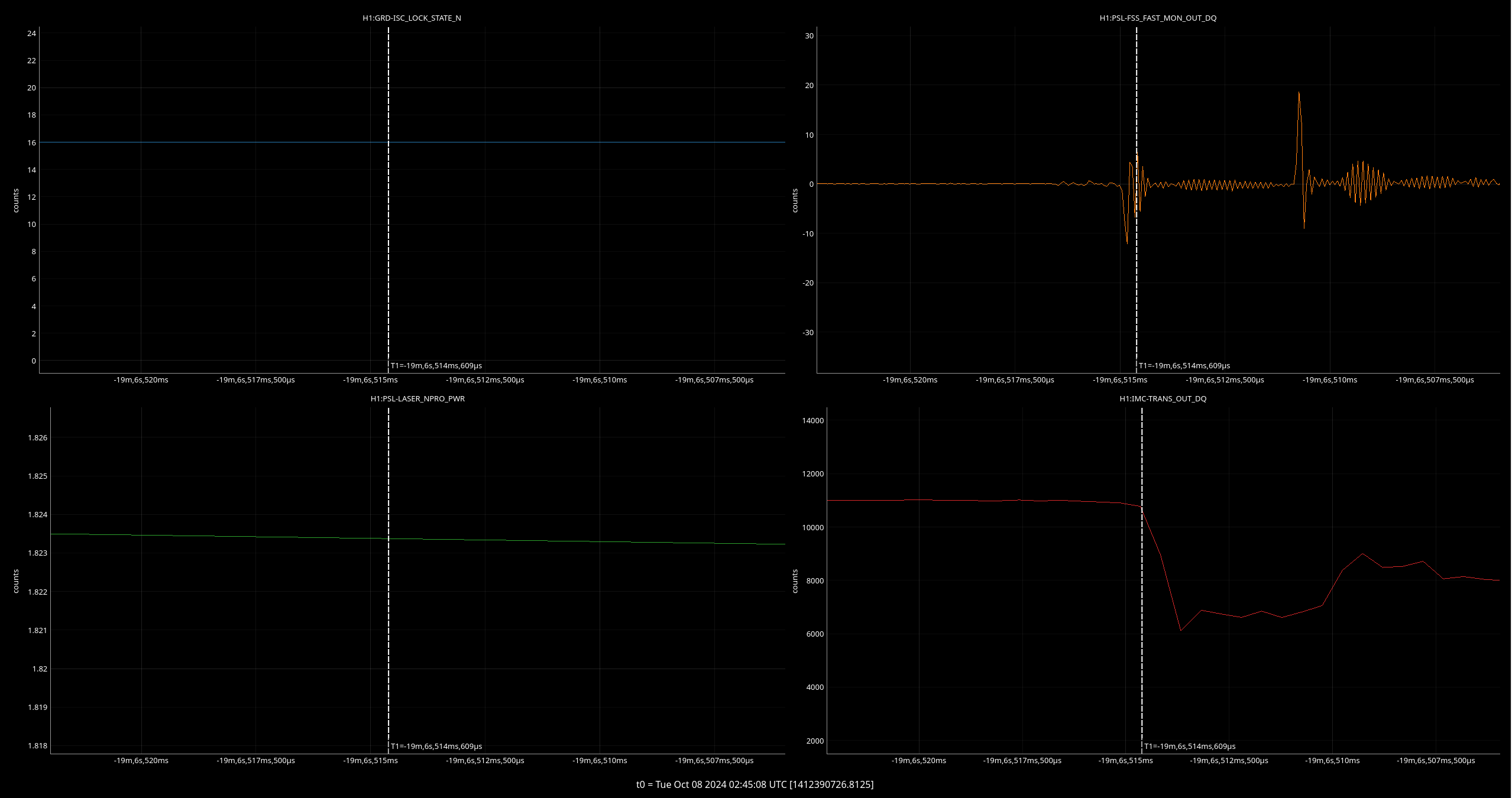
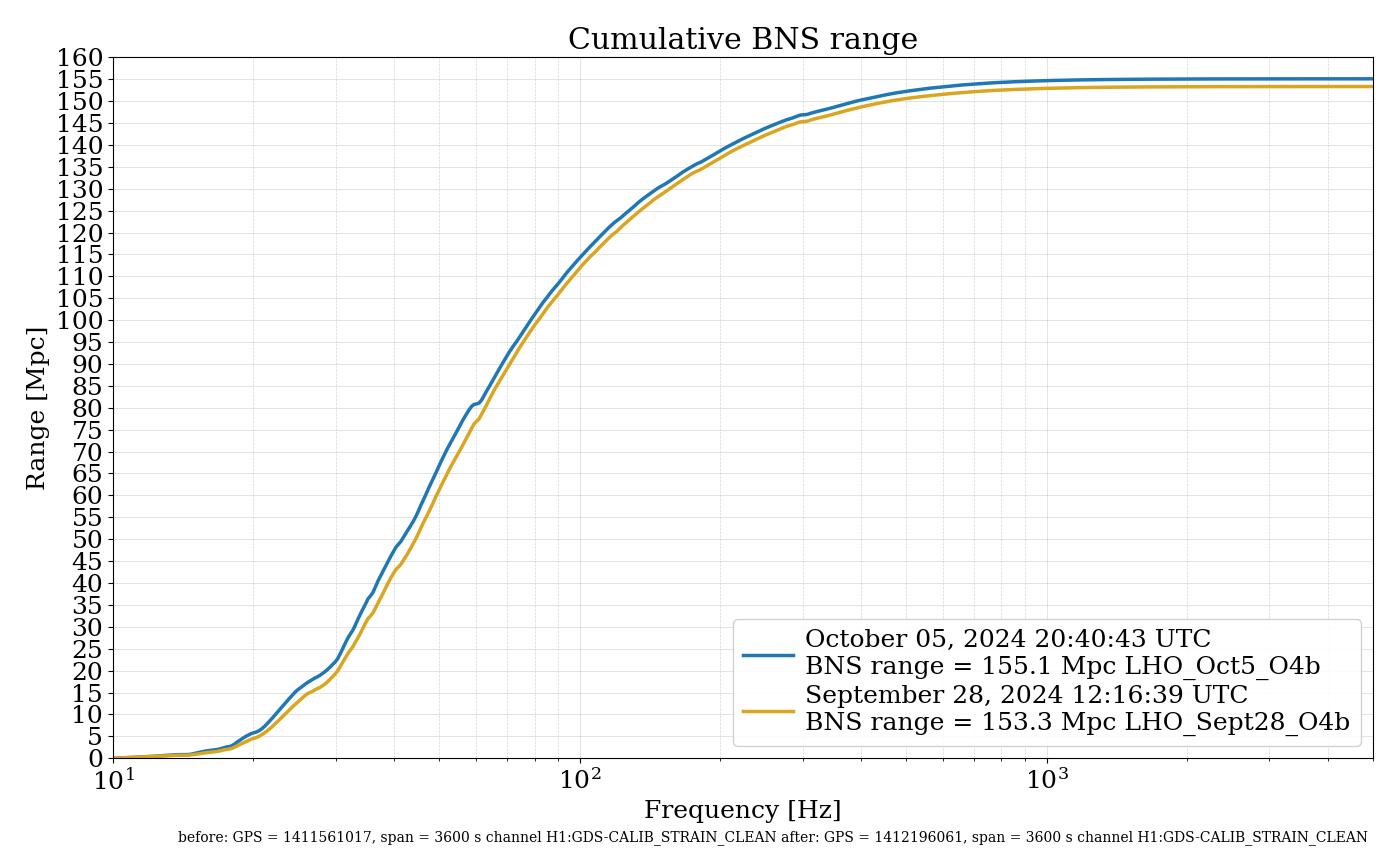
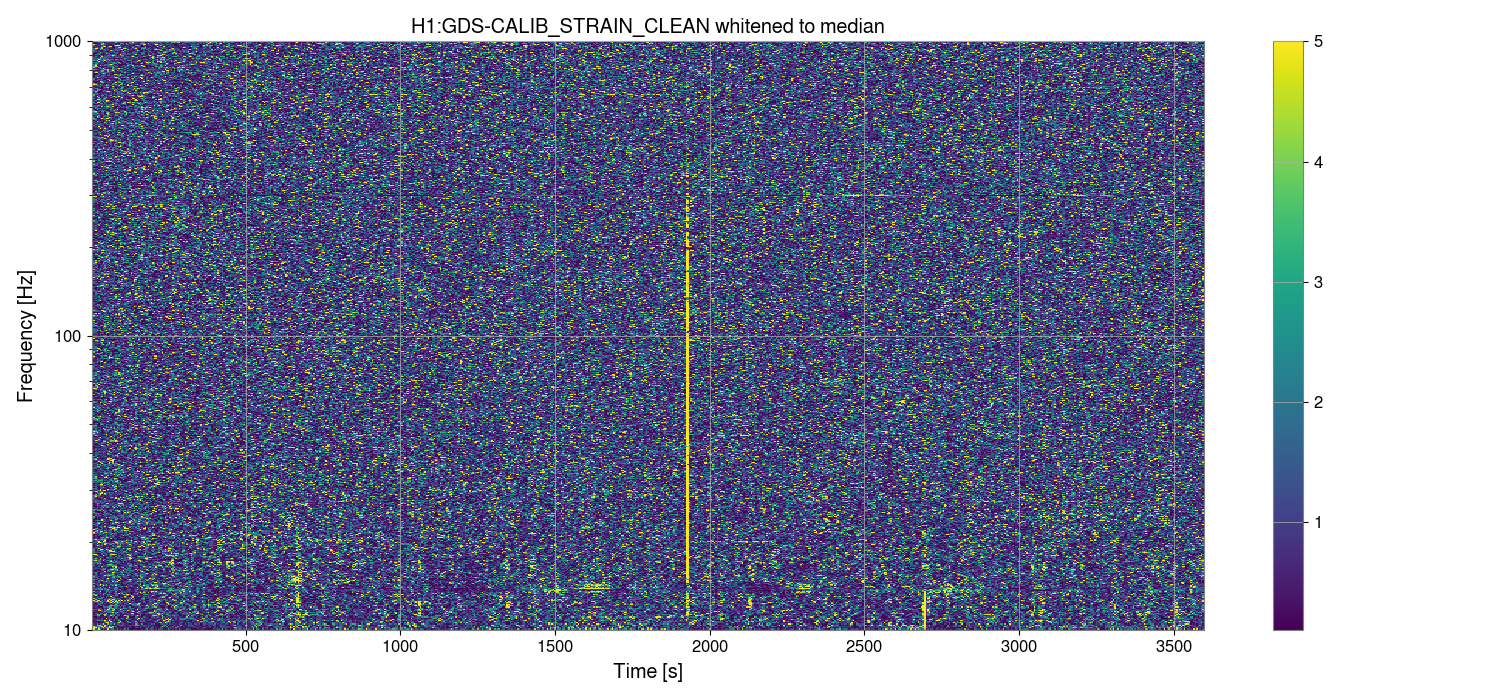
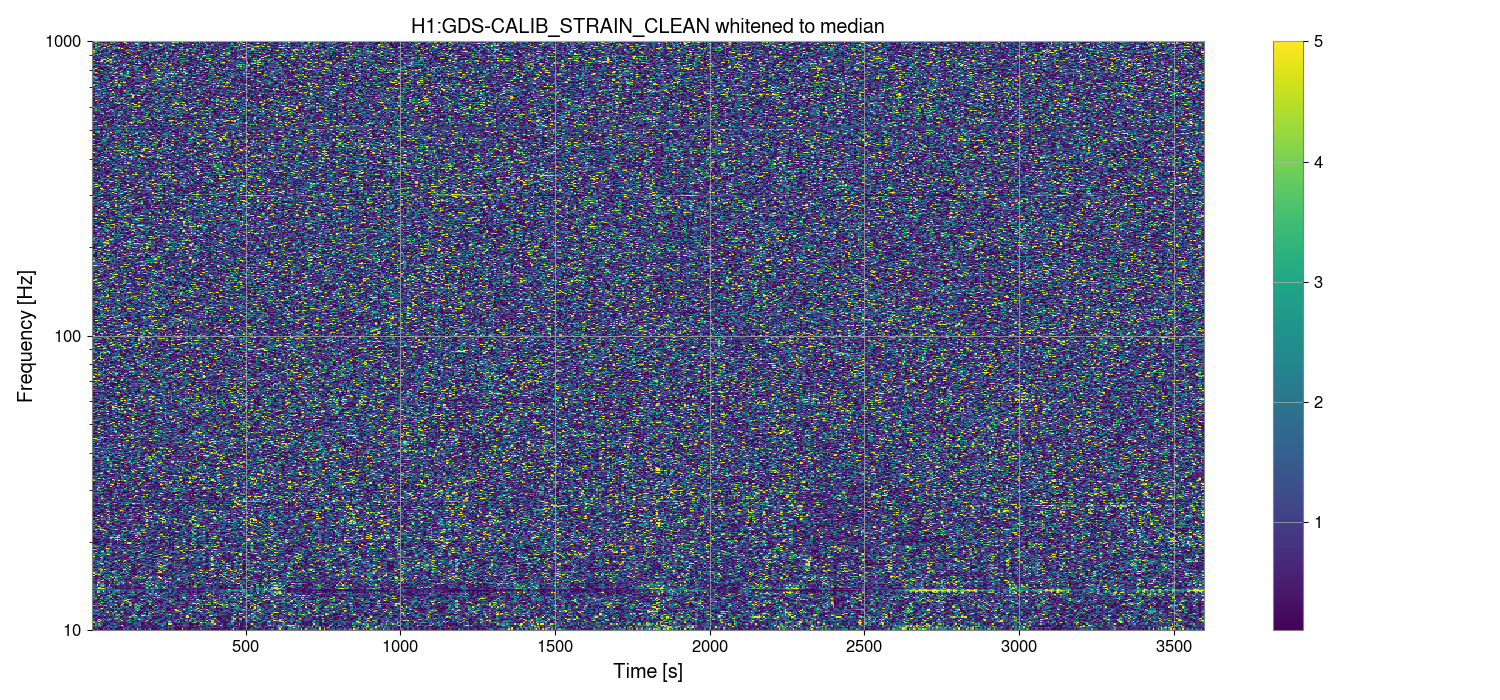
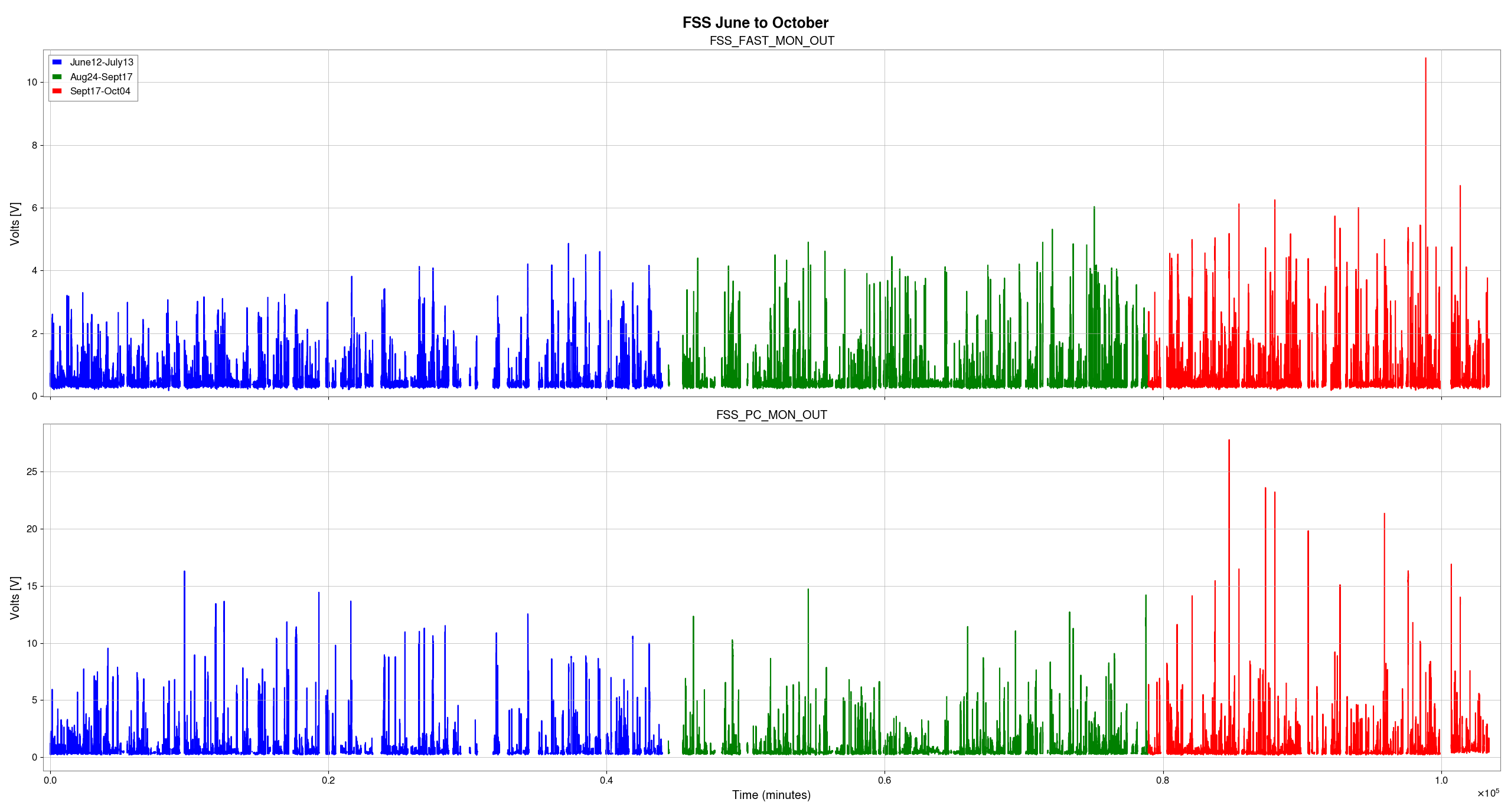
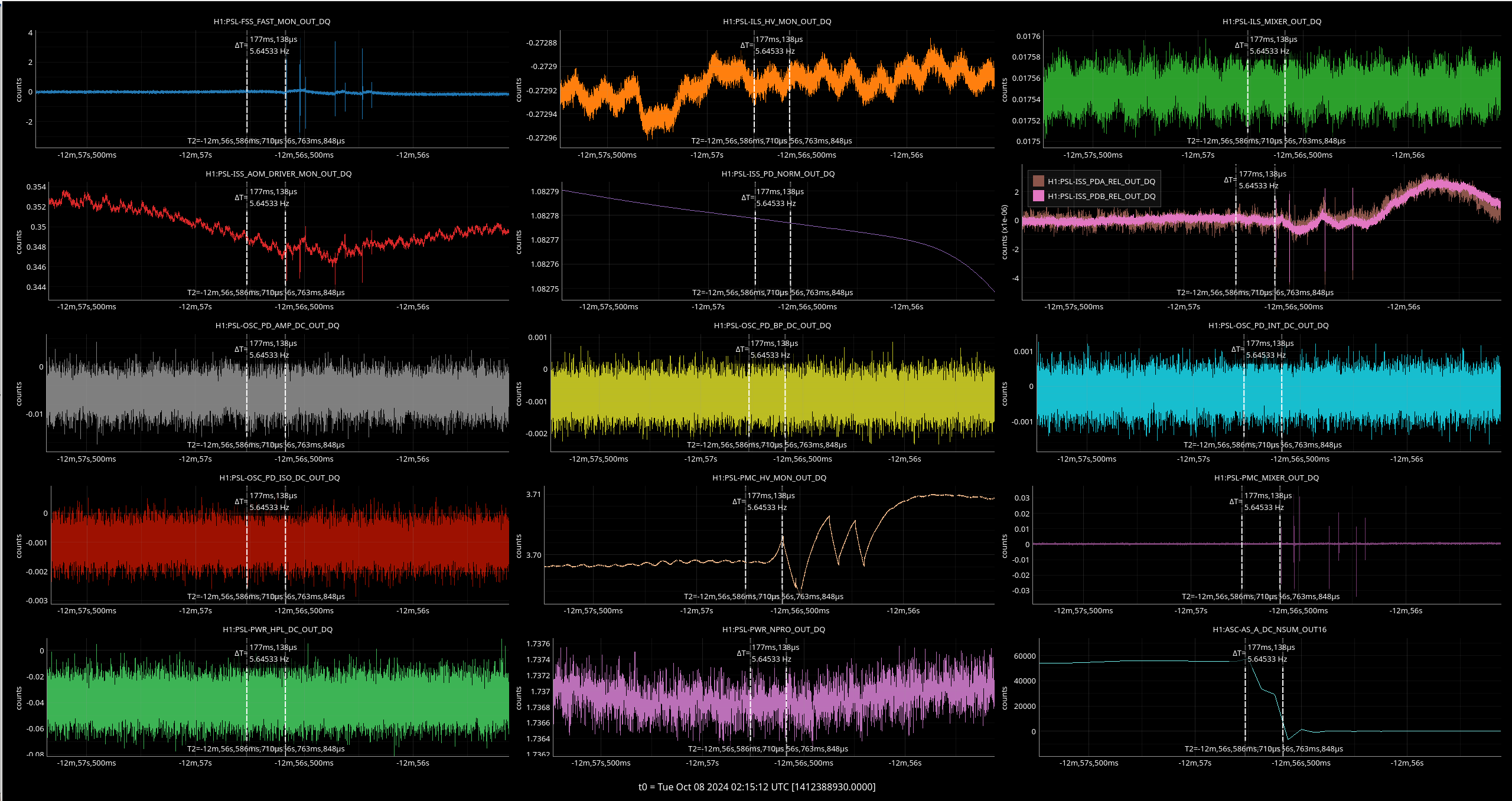
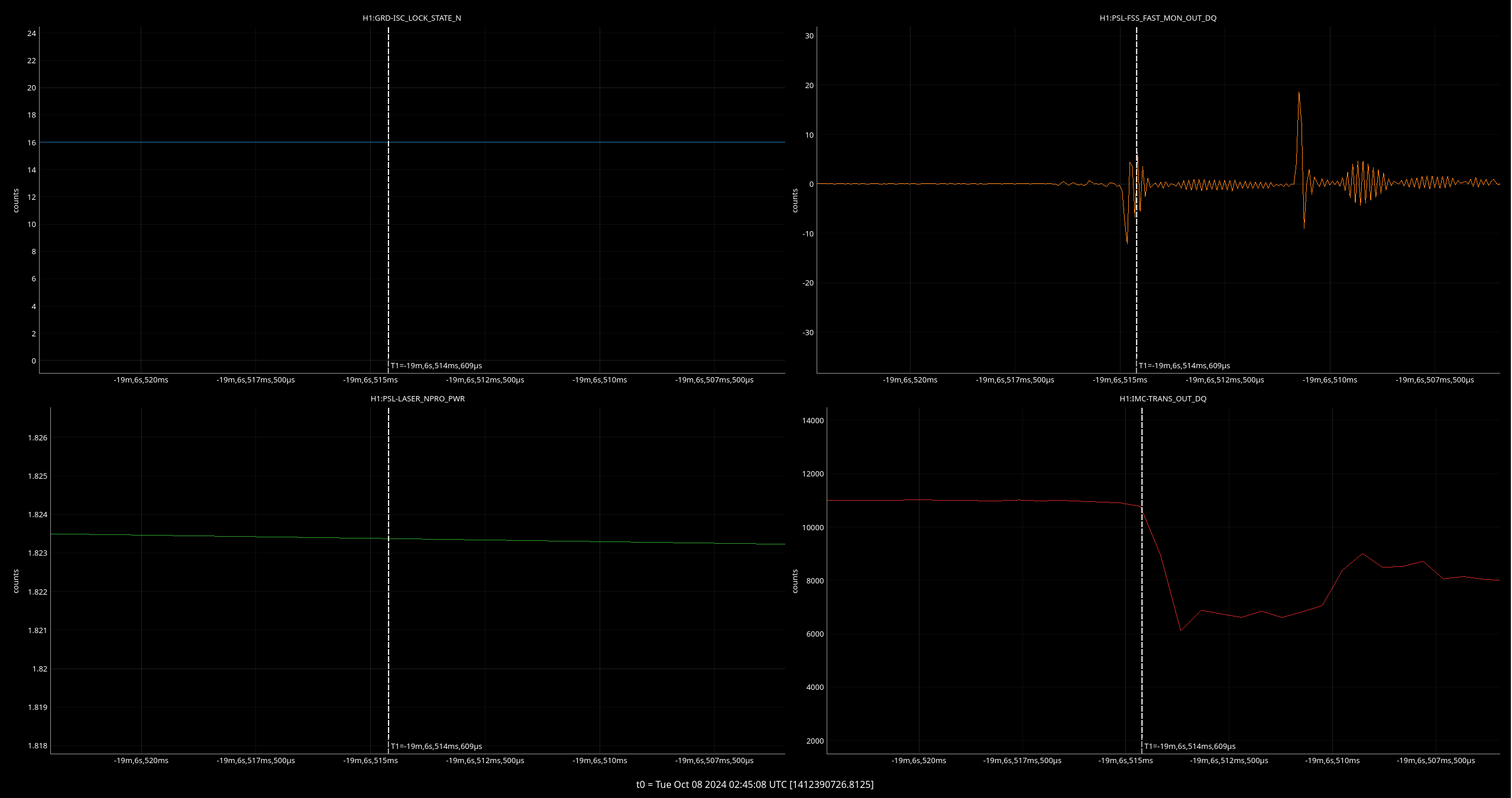
I've taken one of Sheila's and TJ's scripts and adjusted it to plot the max values for PSL-FSS_FAST_MON_OUT_DQ and PSL-FSS_PC_MON_OUTPUT channels before and after we started having issues with the FSS, only looking at data when we were in NLN (600+) and ignoring the data from the last minute in each locked stretch when we lost lock (since the IMC unlocks during locklosses and everything in the detector is generally all over the place).
We started seeing FSS related locklosses starting September 17th, so the plot(attachment1) shows the 'before' in two chunks - June 12 - July 13 (in blue), which was pre- FSS issues and pre- OFI vent, August 24th - September 17th in green, which was after the OFI vent but before we started having FSS issues, and then the 'after'/during is September 17th - October 4th, shown in red.
In both channels we can see that the red tends to reach higher than the blue or green, but the difference isn't as drastic and the glitching doesn't seem to be more frequent during the FSS issues either. By squishing up the plot(attachment2), I did notice that the level FASTMON reaches does look to have been gradually increasing over the last 4 months, which is interesting.
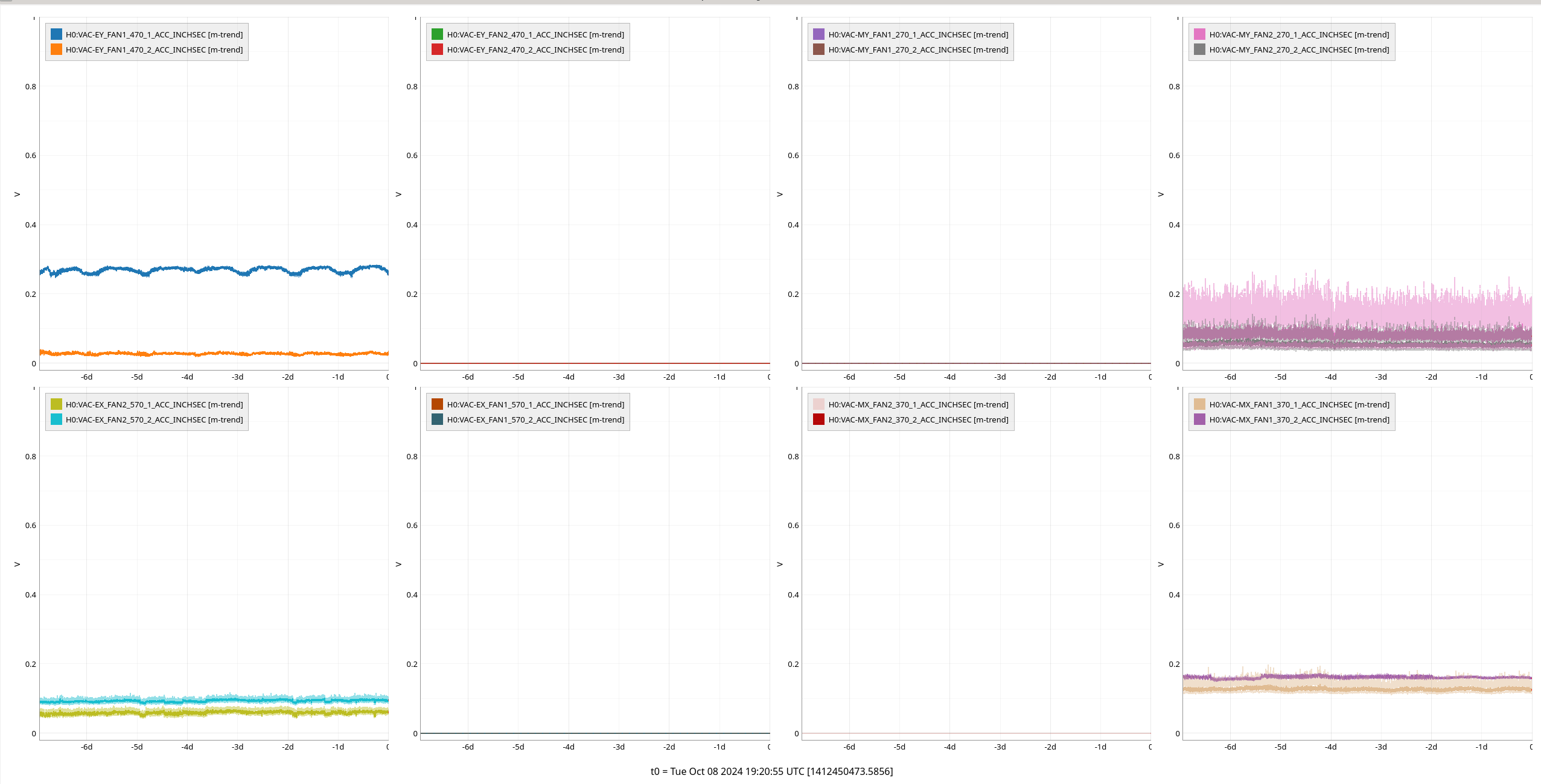
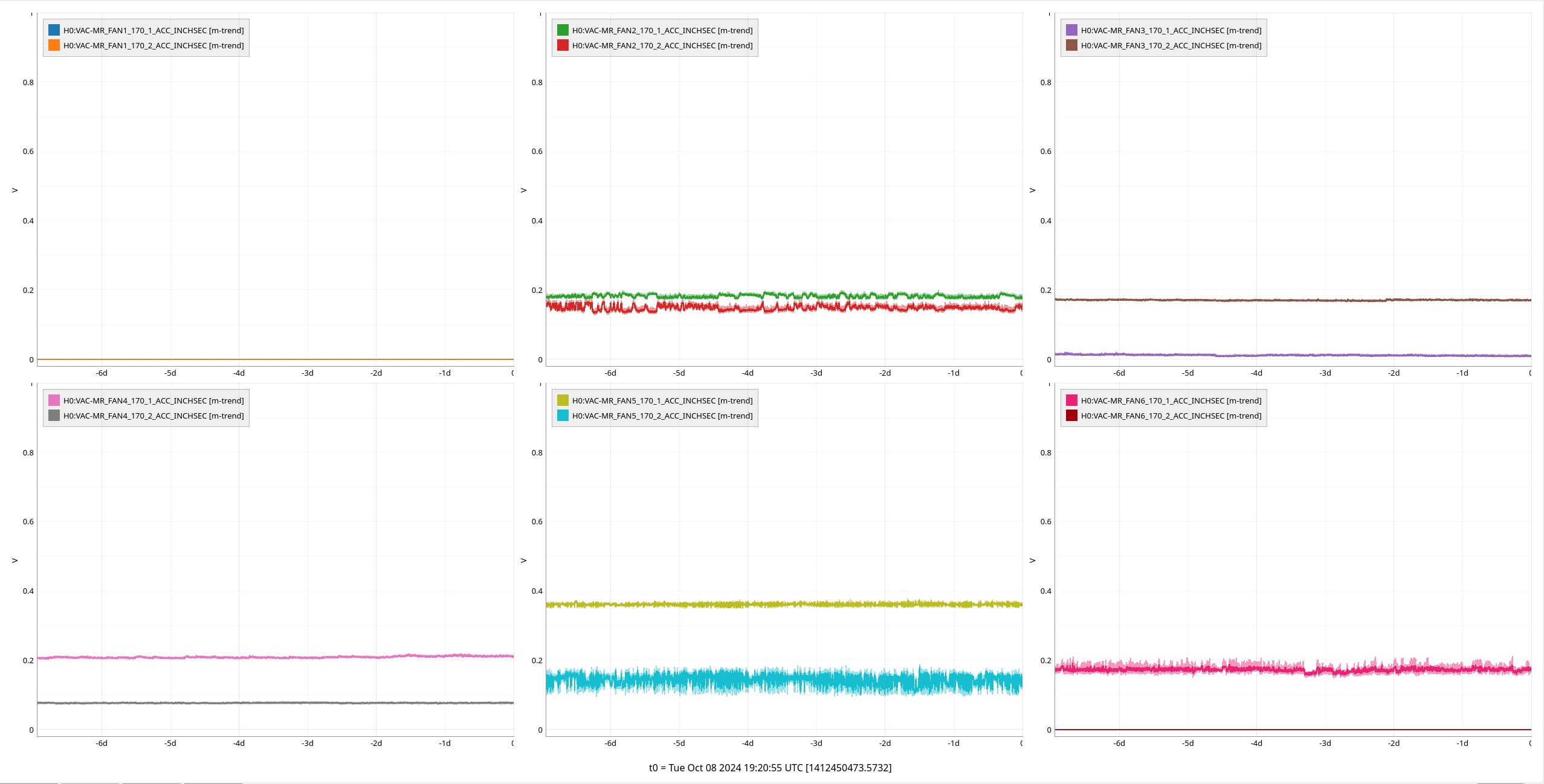
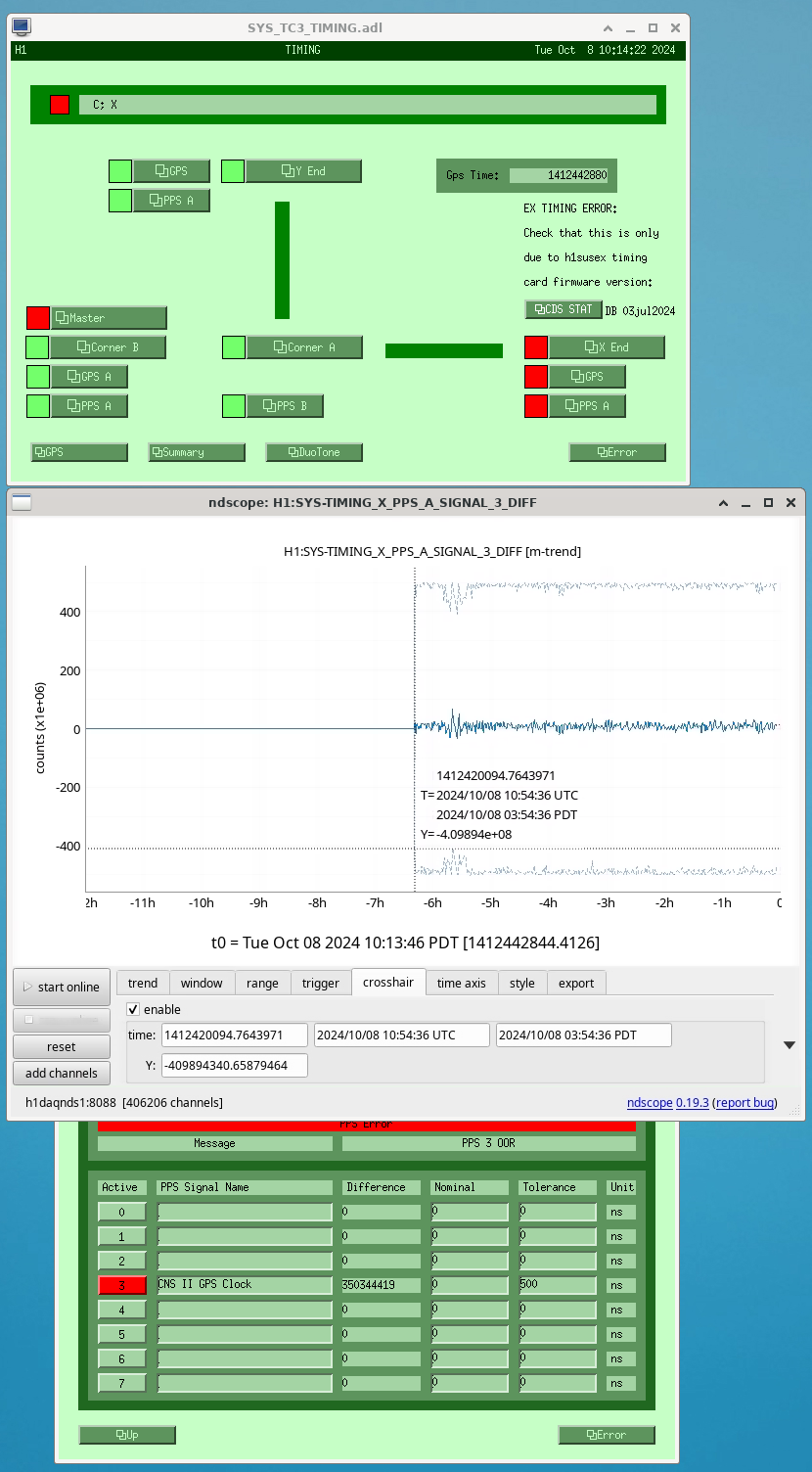
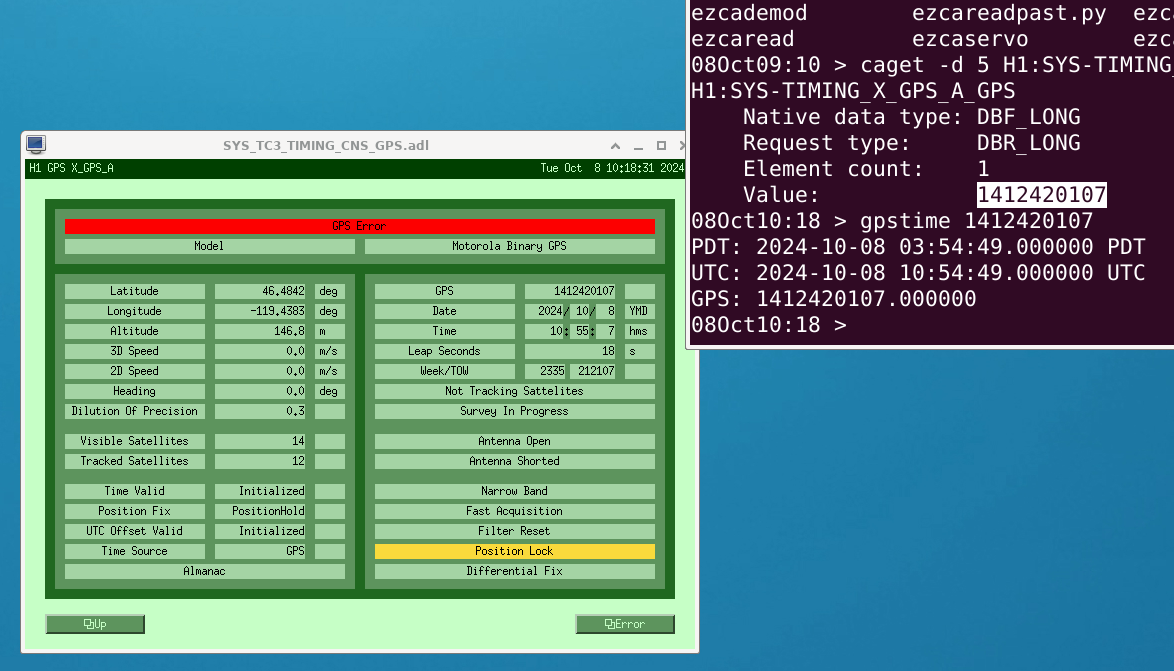


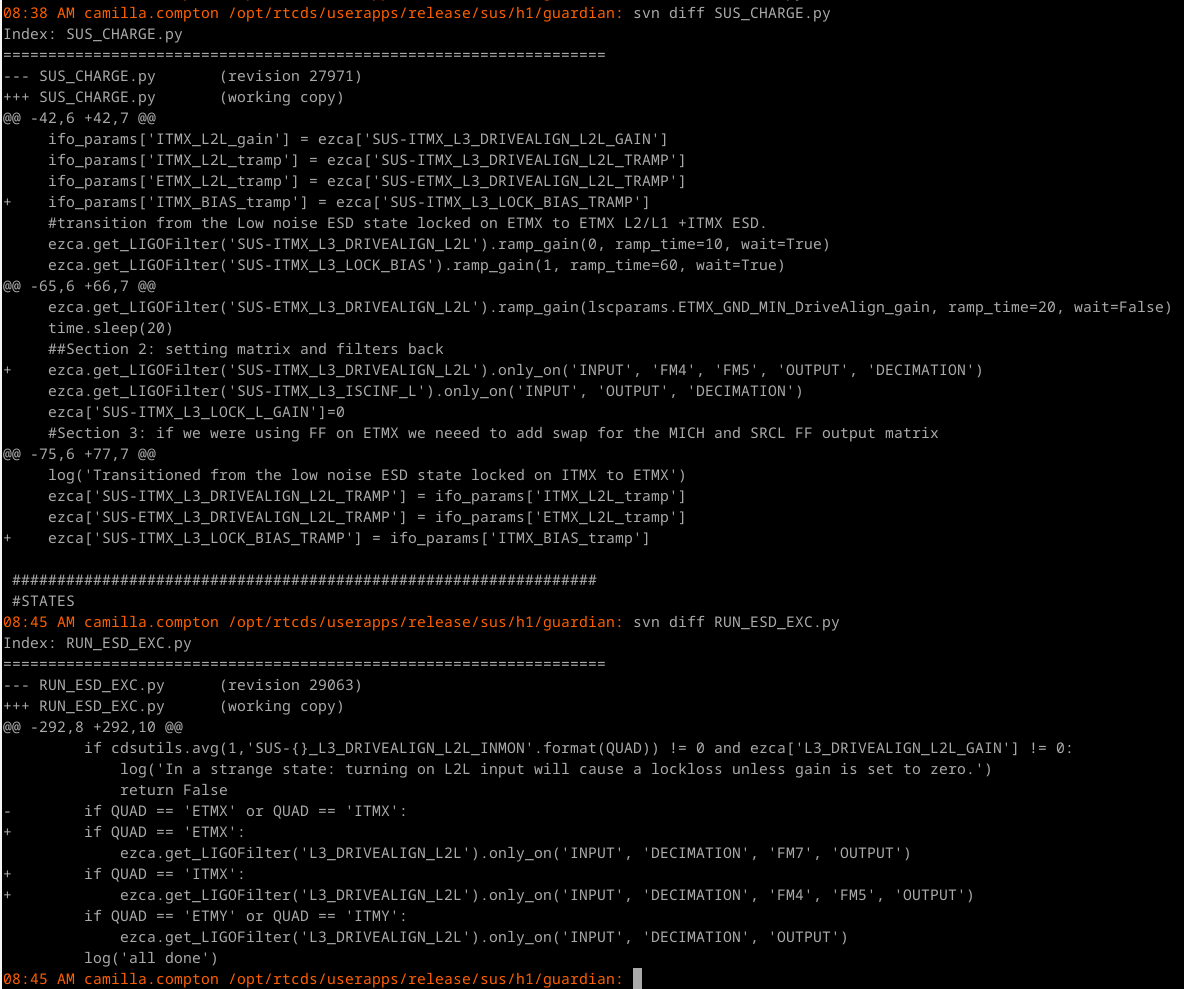
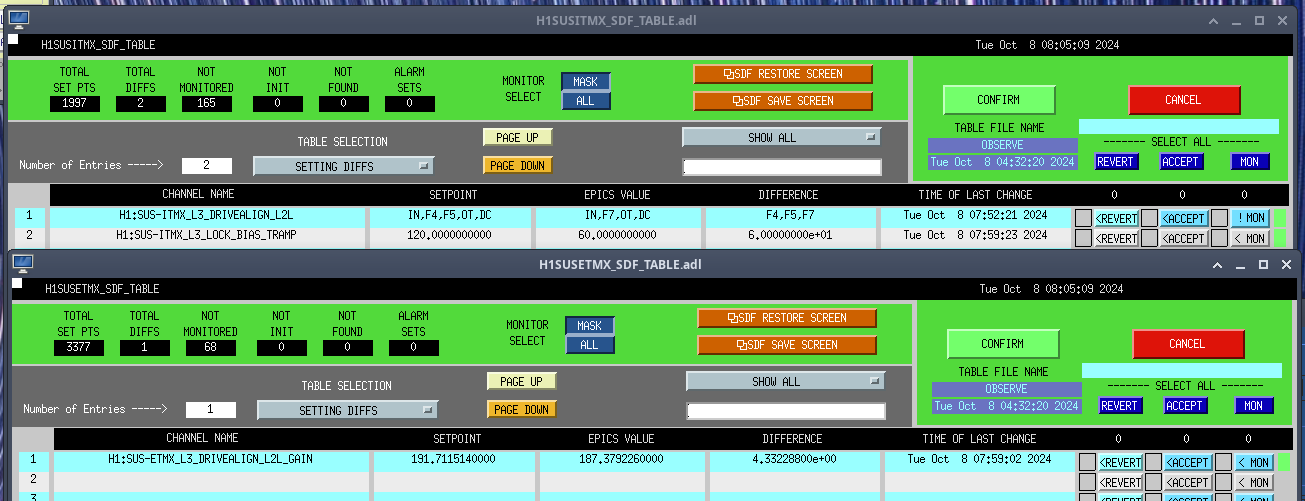
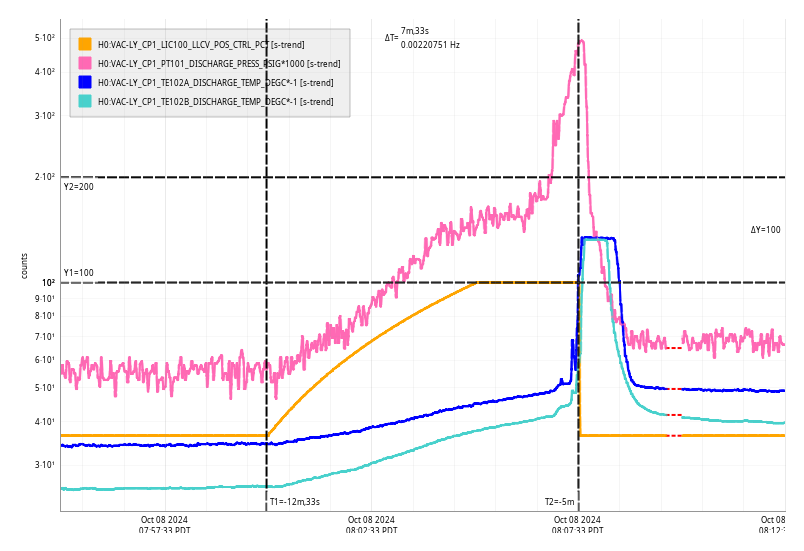
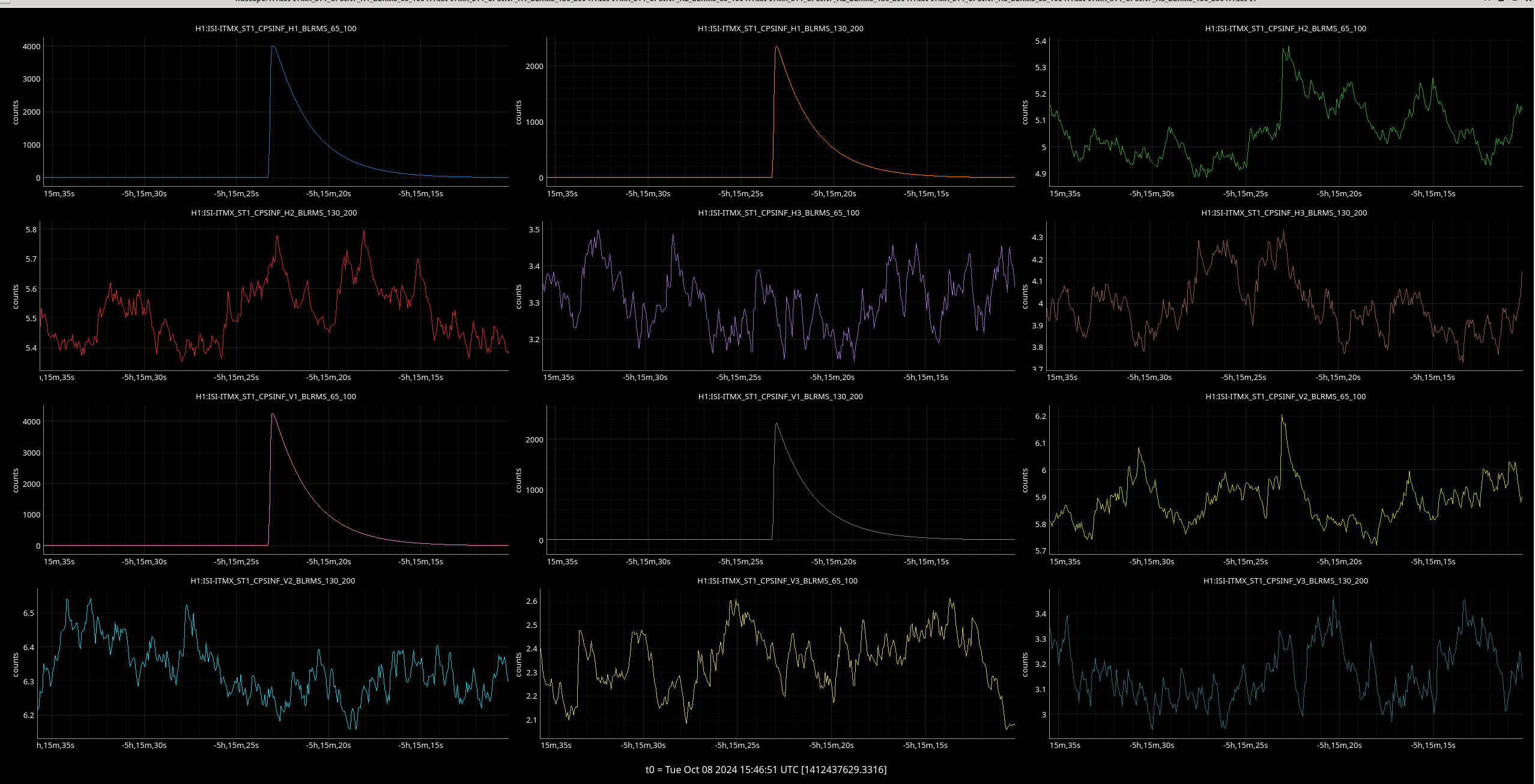

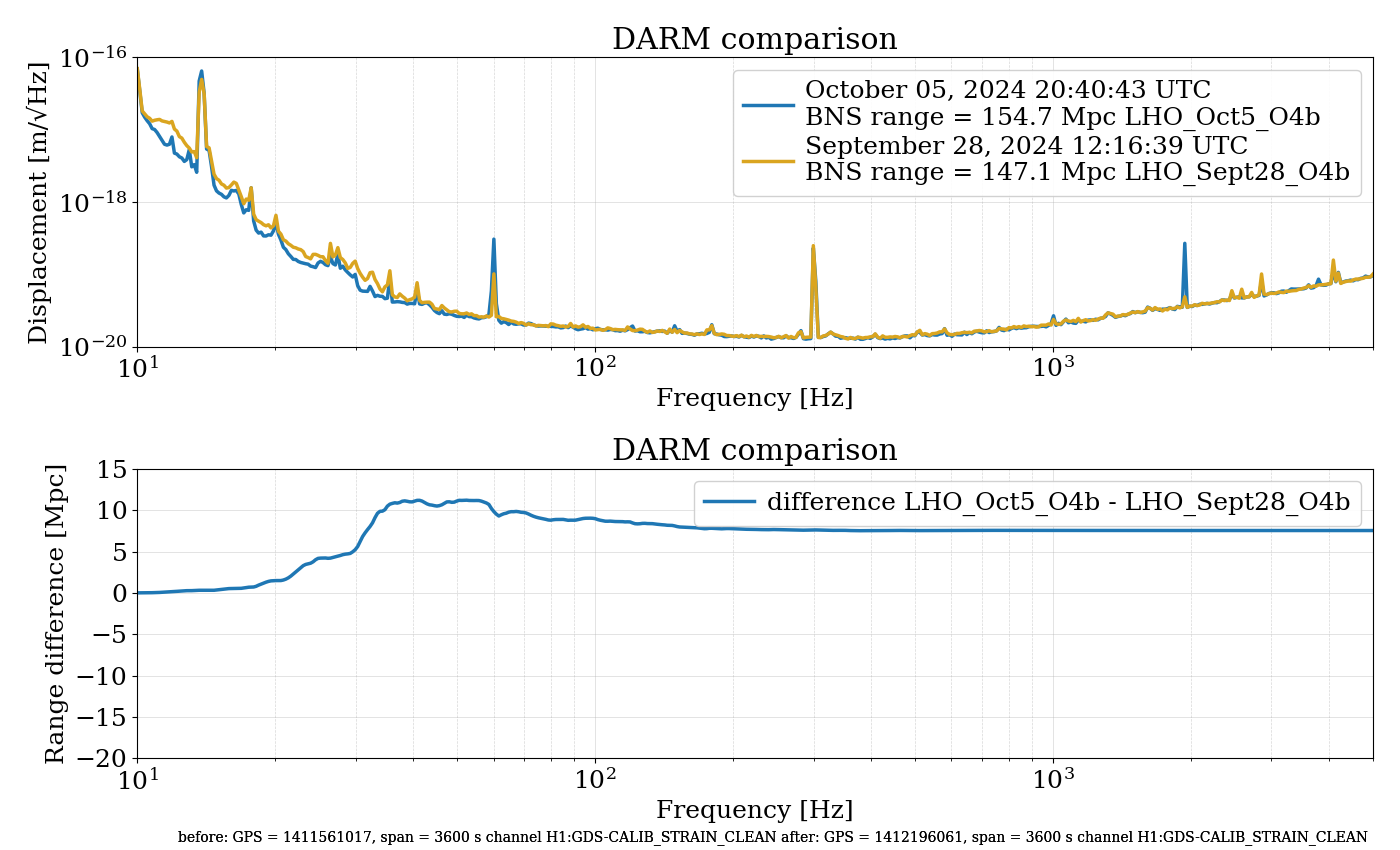
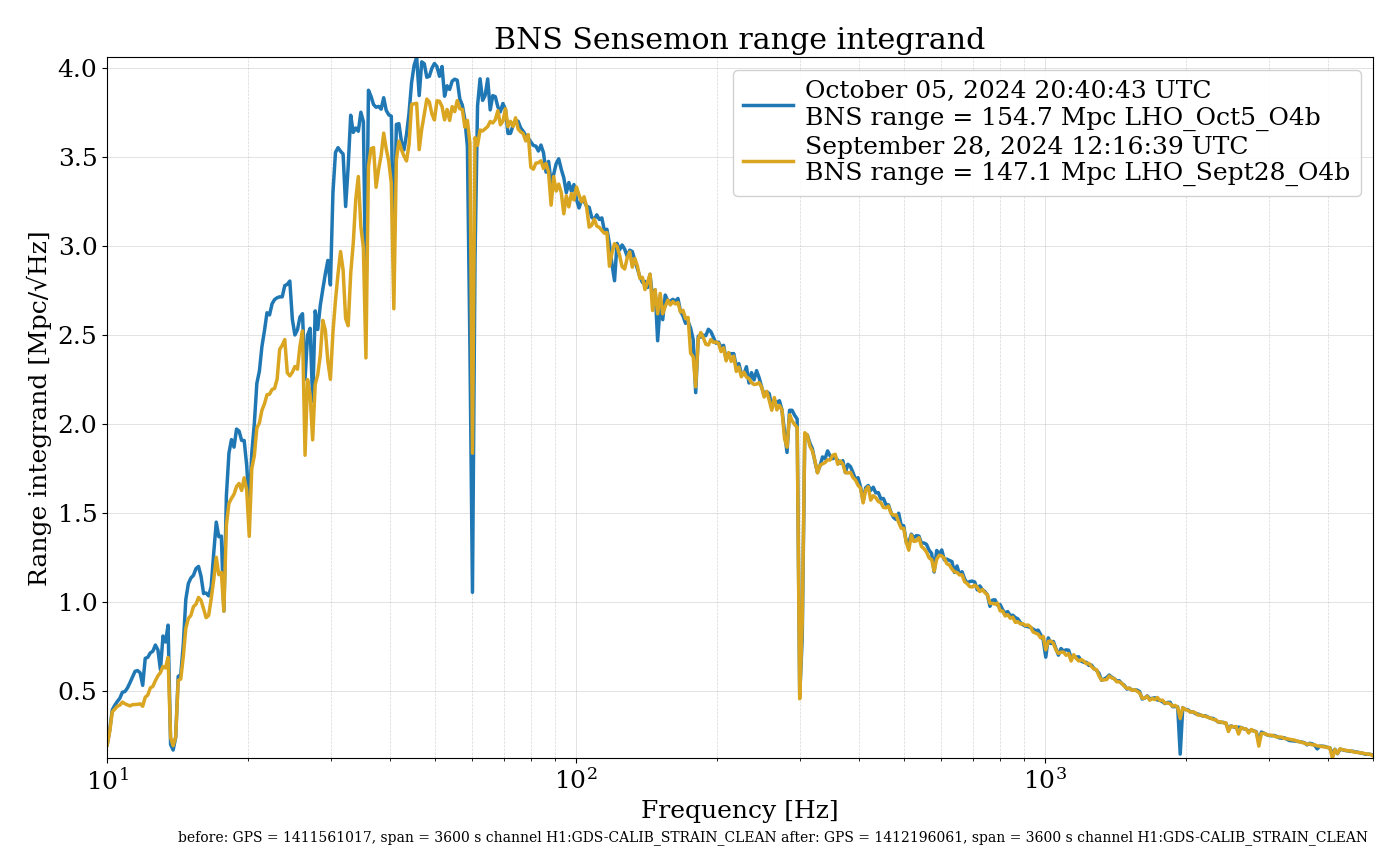
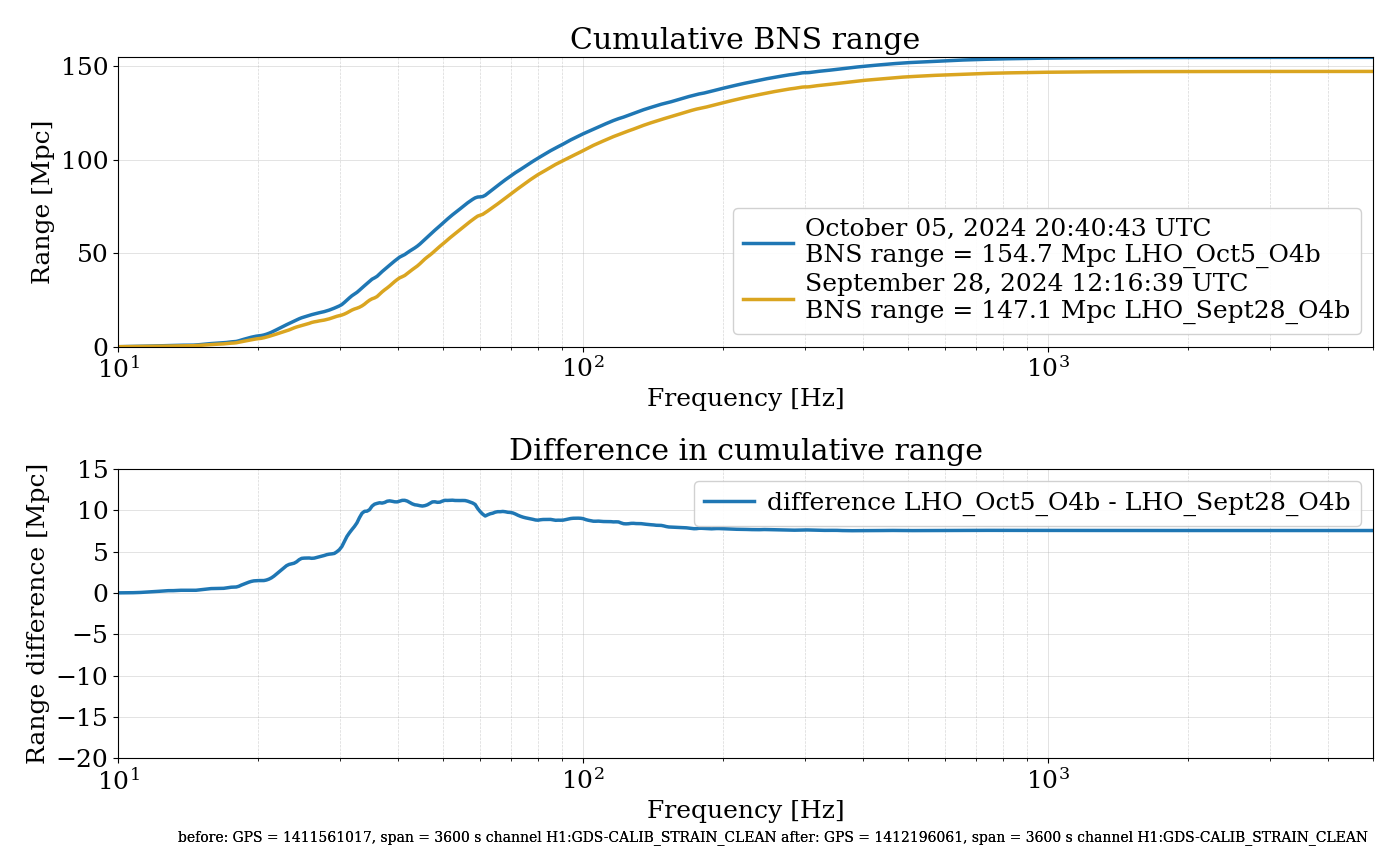
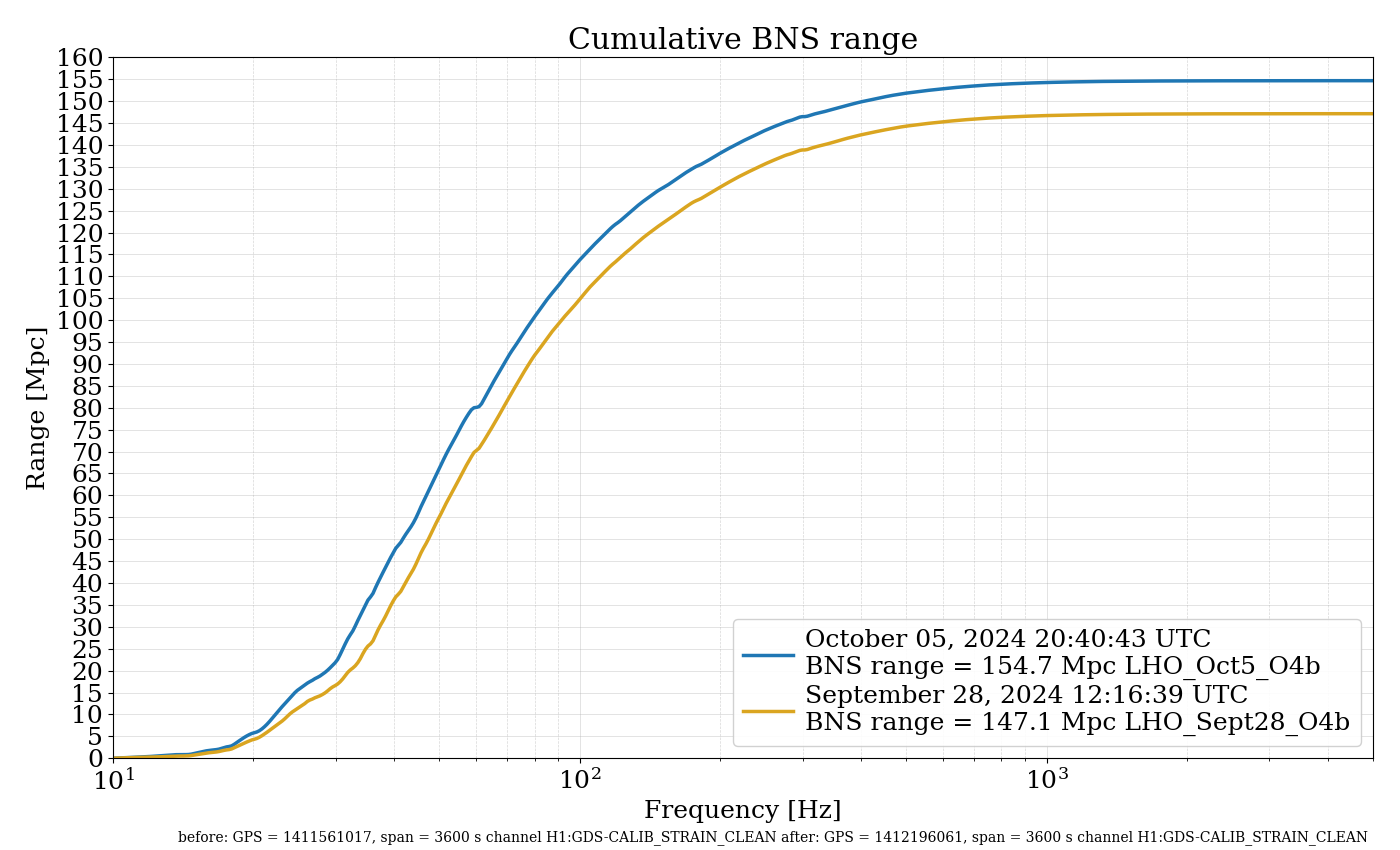
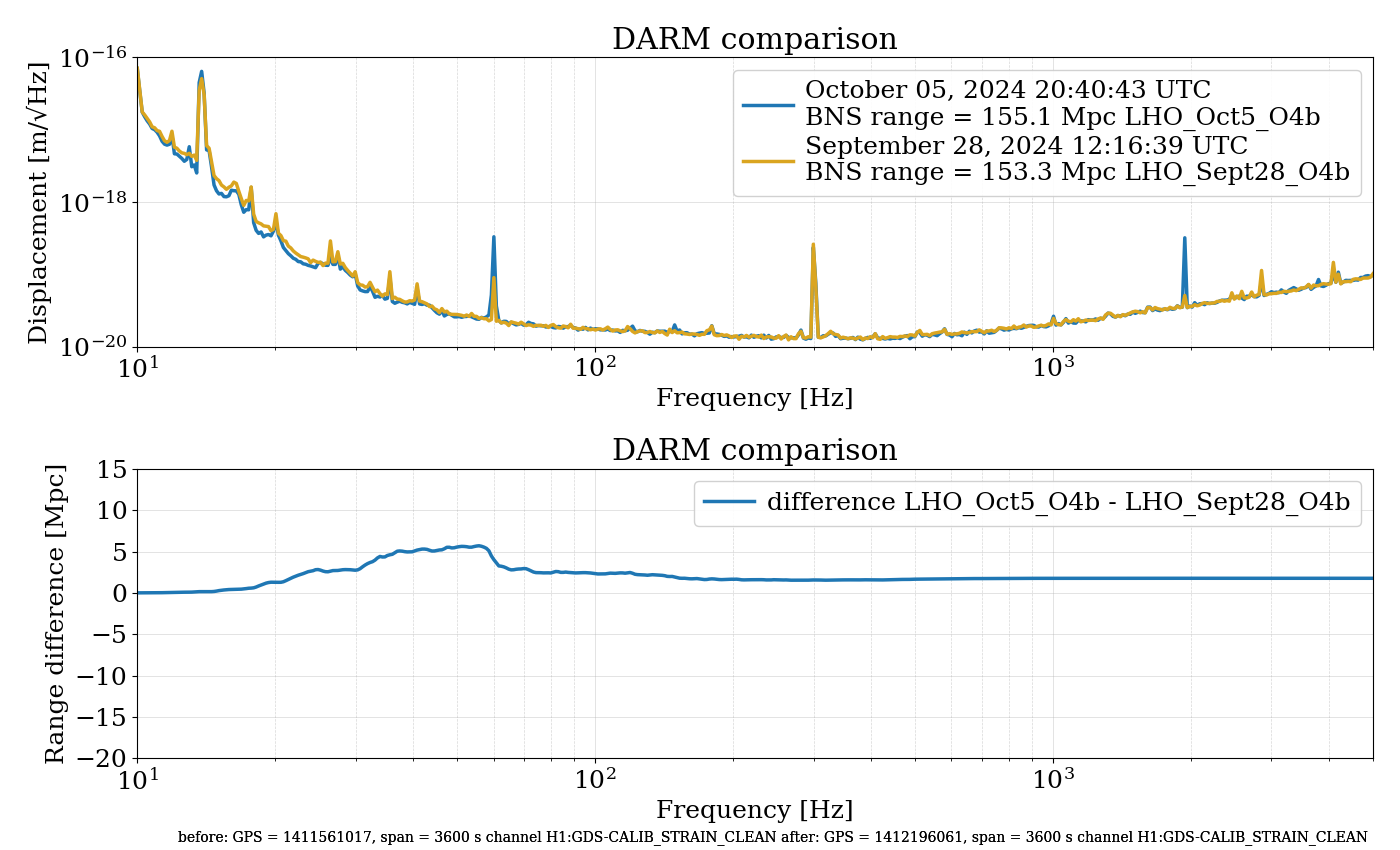
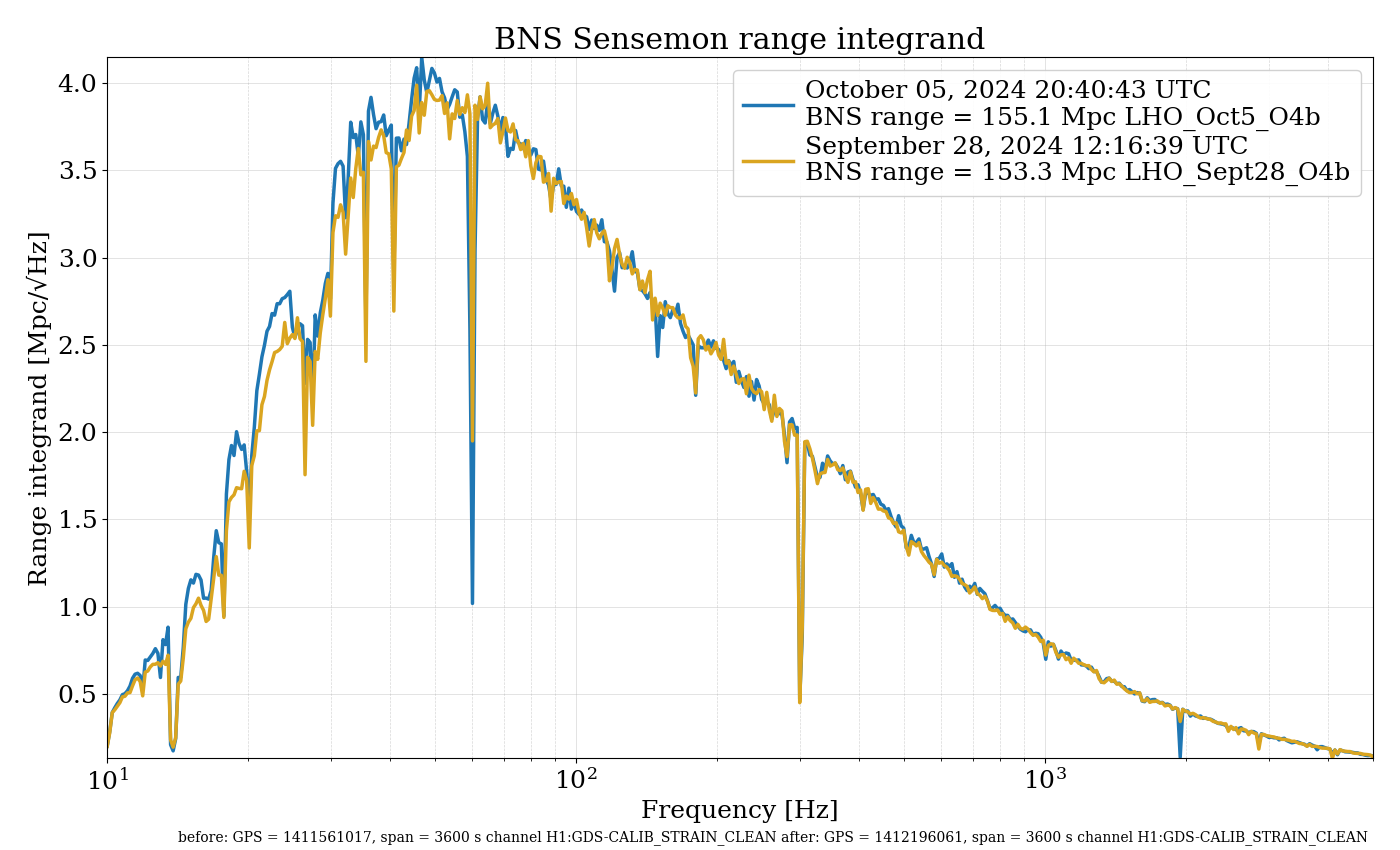
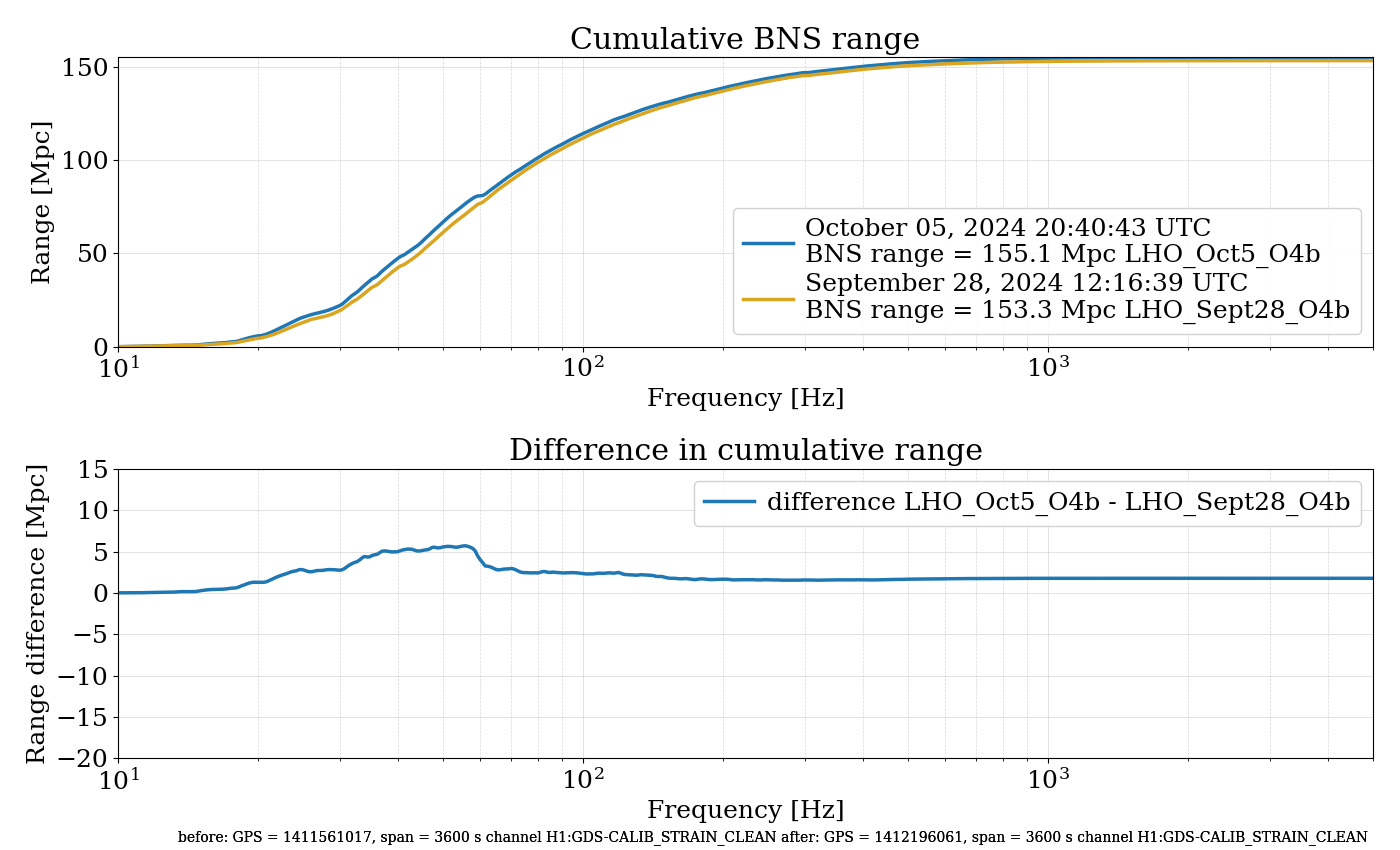
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}