david.barker@LIGO.ORG - posted 08:43, Tuesday 01 October 2024 - last comment - 09:22, Tuesday 01 October 2024(80389)
VACSTAT detected BSC3 glitch at 02:13:44 PDT Tue 01 Oct 2024
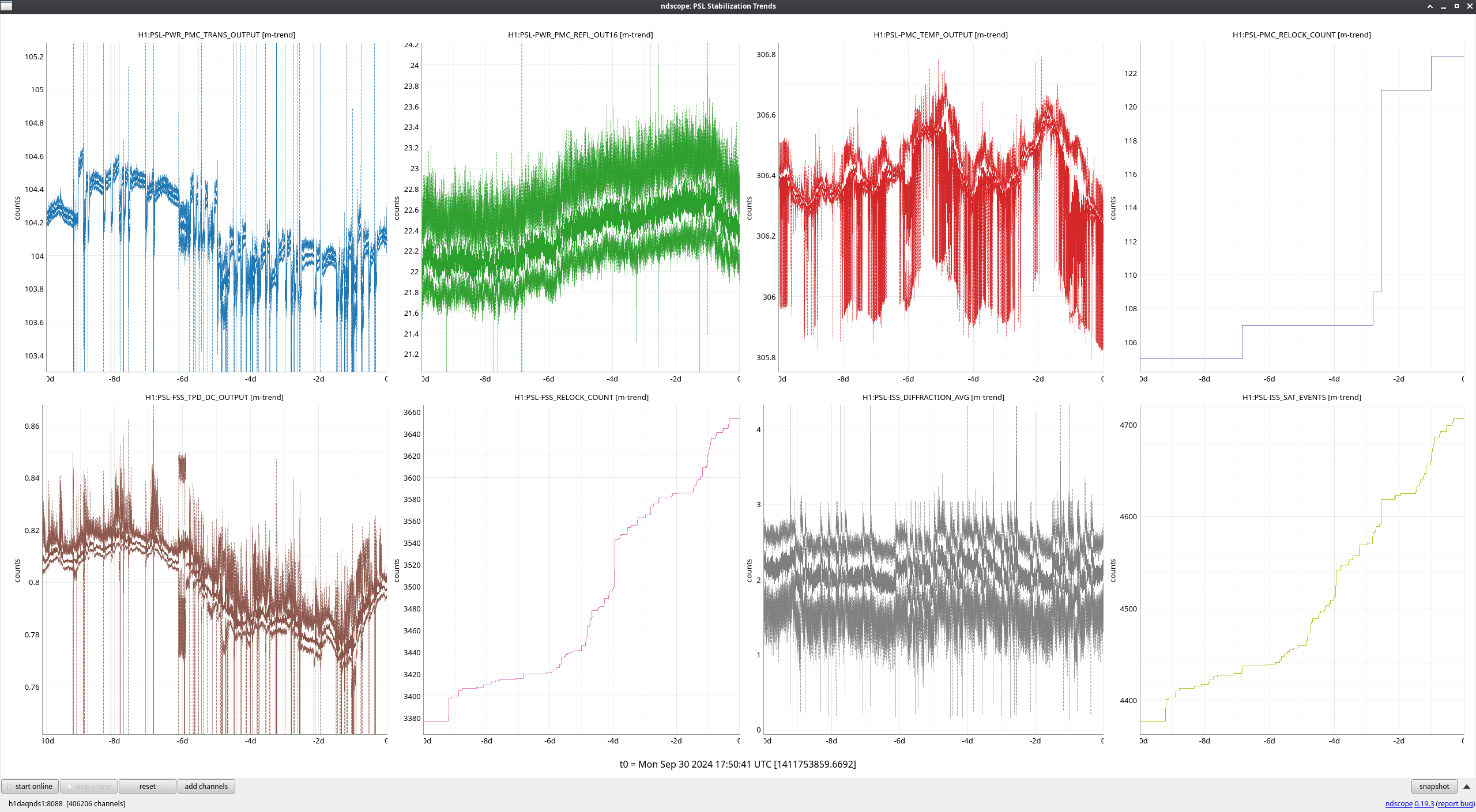
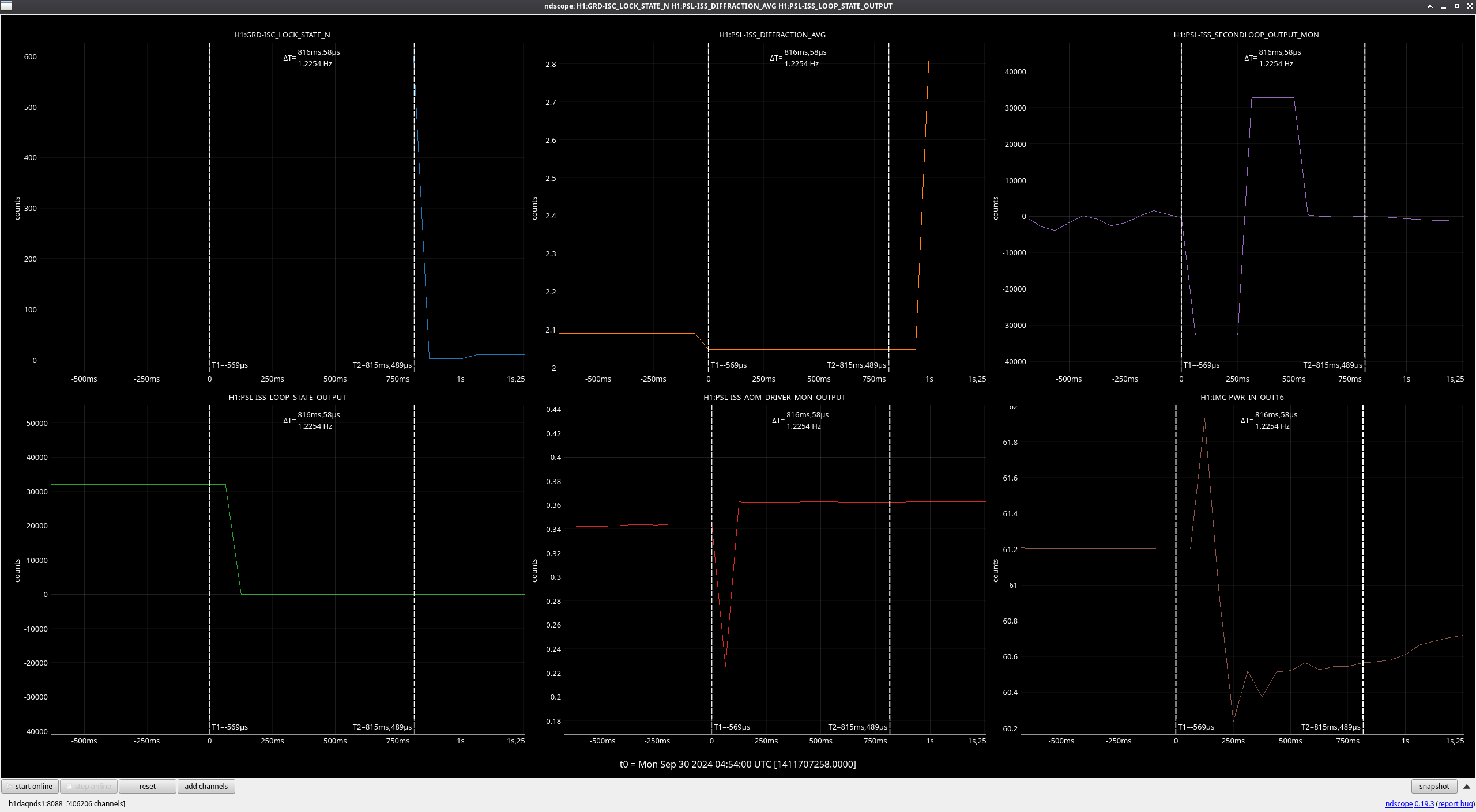
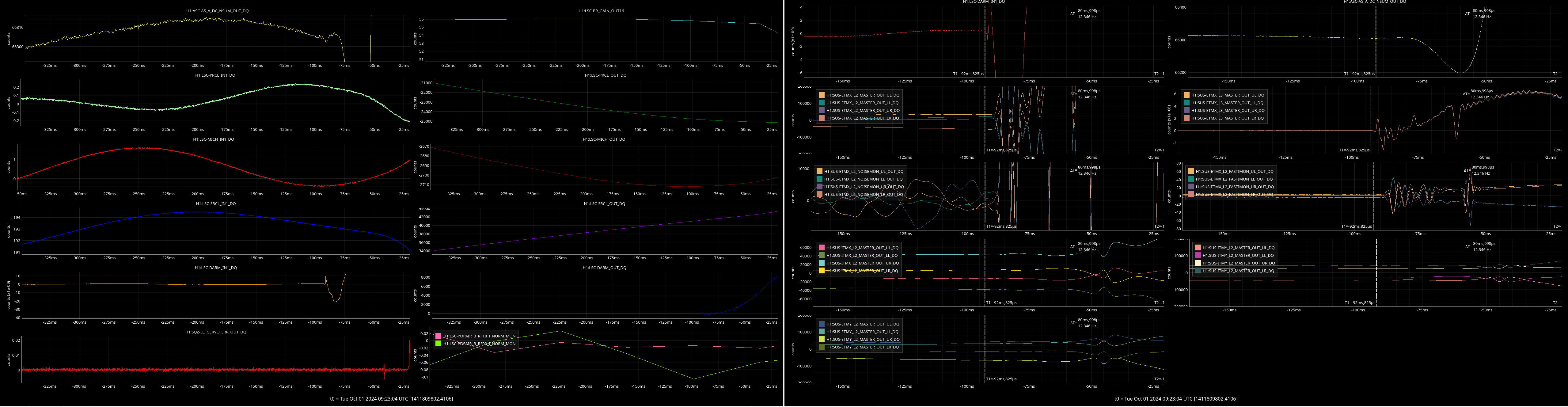
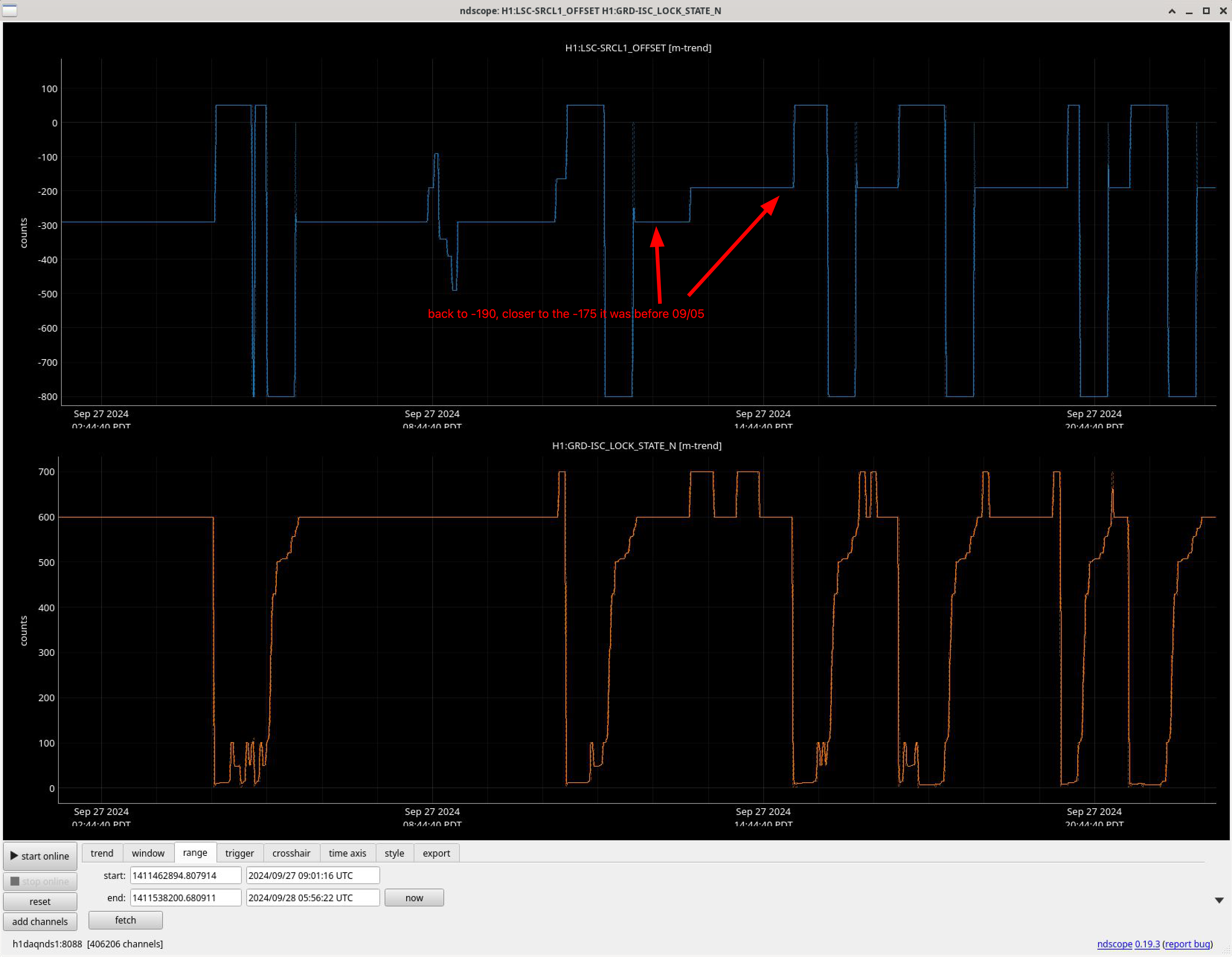
VACSTAT issued alarms for a BSC vacuum glitch at 02:13 this morning. Attachment shows main VACSTAT MEDM, the latch plots for BSC3, and a 24 hour trend of BSC2 and BSC3.
The glitch is a square wave, 3 second wide. Vacuum goes up from 5.3e-08 to 7.5e-08 Torr for these 3 seconds. Neighbouring BSC2 shows no glitch in the trend.
Looks like a PT132_MOD2 sensor glitch.
Images attached to this report

Comments related to this report
vacstat_ioc.service was restarted on cdsioc0 at 09:04 to clear the latched event.
This is the second false-positive VACSTAT PT132 glitch detected.
| 02:13 Tue 01 Oct 2024 |
| 02:21 Sun 01 Sep 2024 |











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}