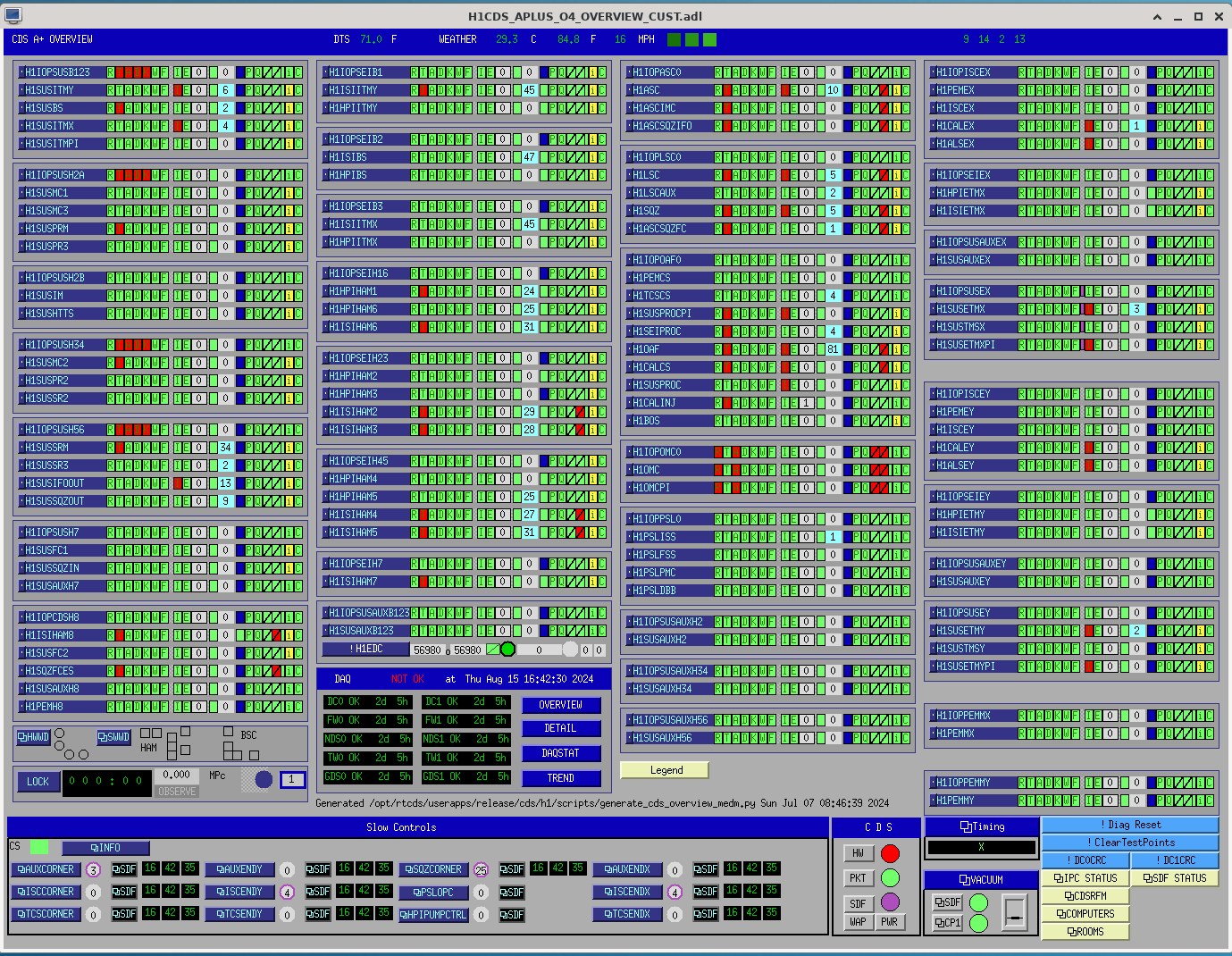
We had a failure of h1omc0 at 16:37:24 PDT which precipitated a Dolphin crash of the usual corner station system.
System recovered by:
Fencing h1omc0 from Dolphin
Complete power cycle of h1omc0 (front end computer and IO Chassis)
Bypass SWWD for BSC1,2,3 and HAM2,3,4,5,6
Restart all models on h1susb123, h1sush2a, h1sush34 and h1sush56
Reset all SWWDs for these chambers
Recover SUS models following restart.
Cause of h1omc0 crash: Low Noise ADC Channel Hop
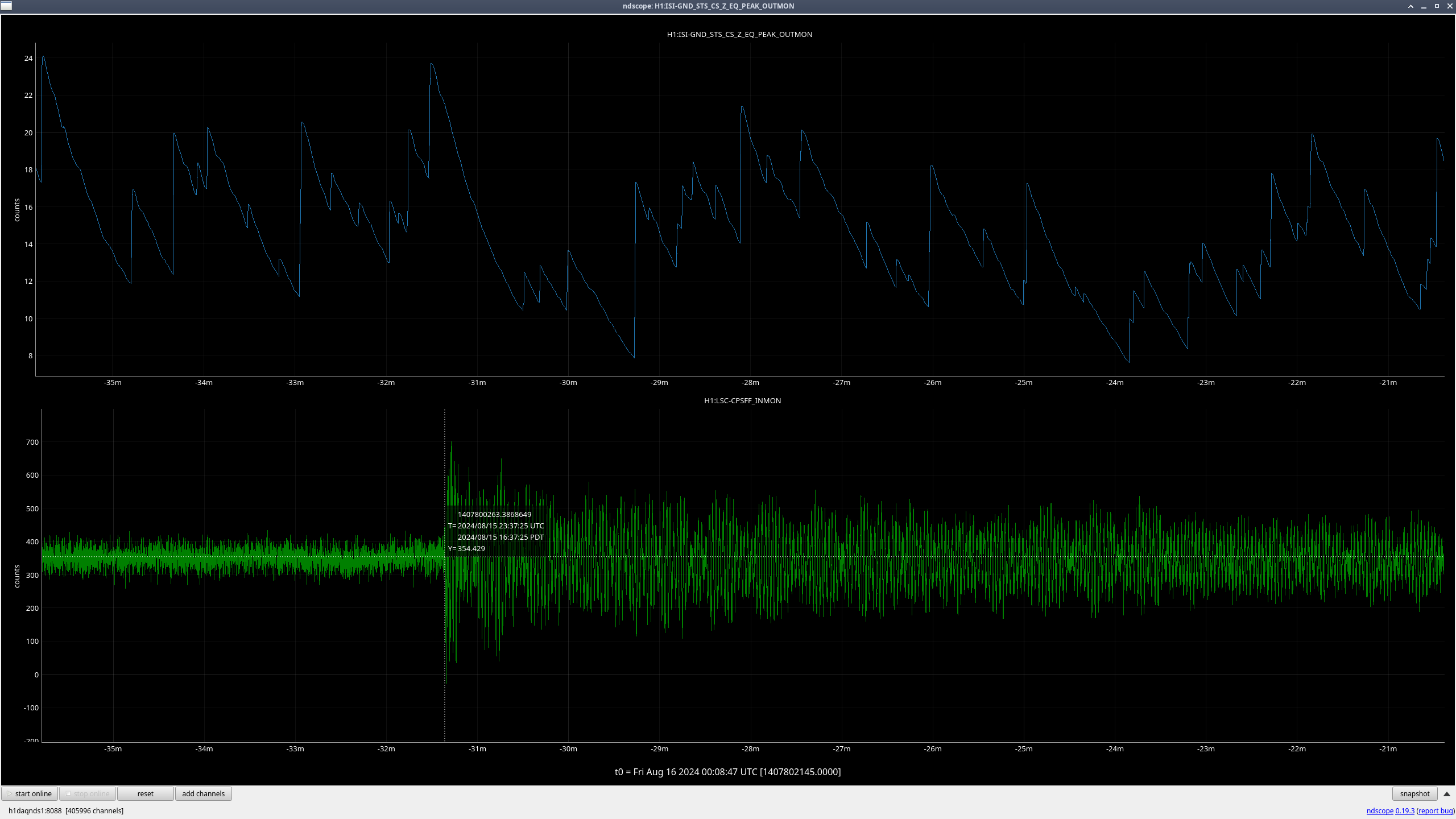
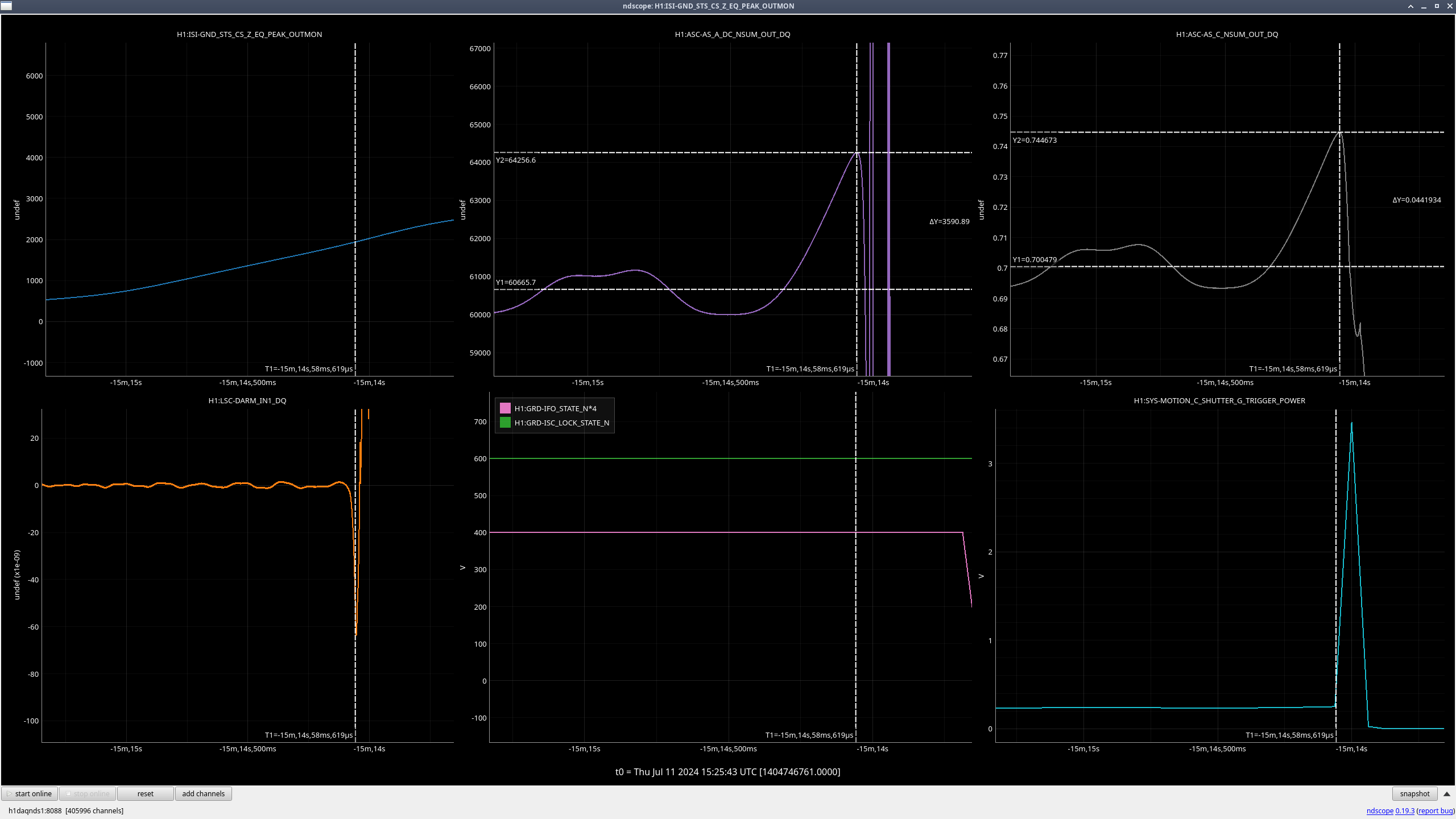
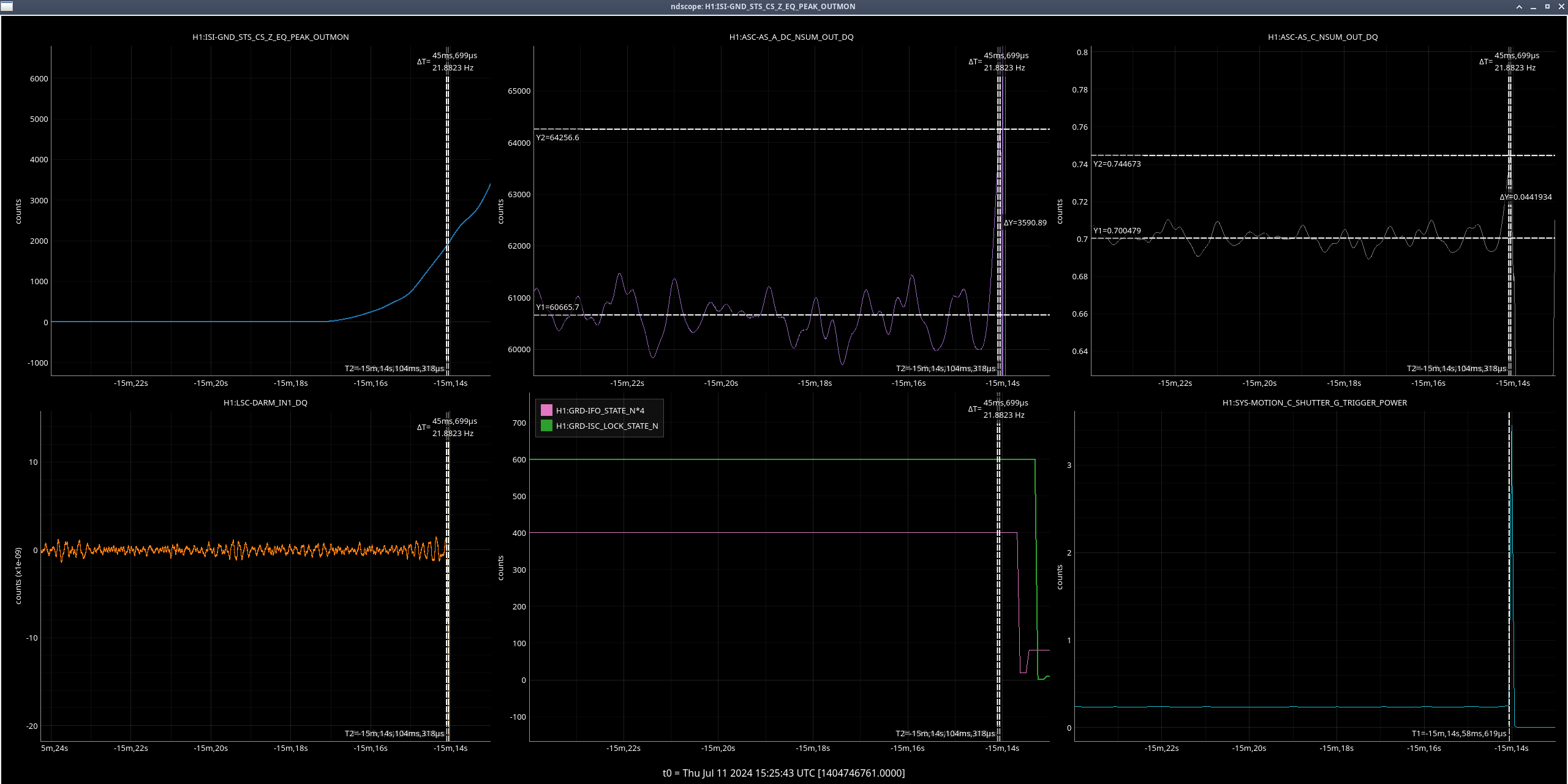
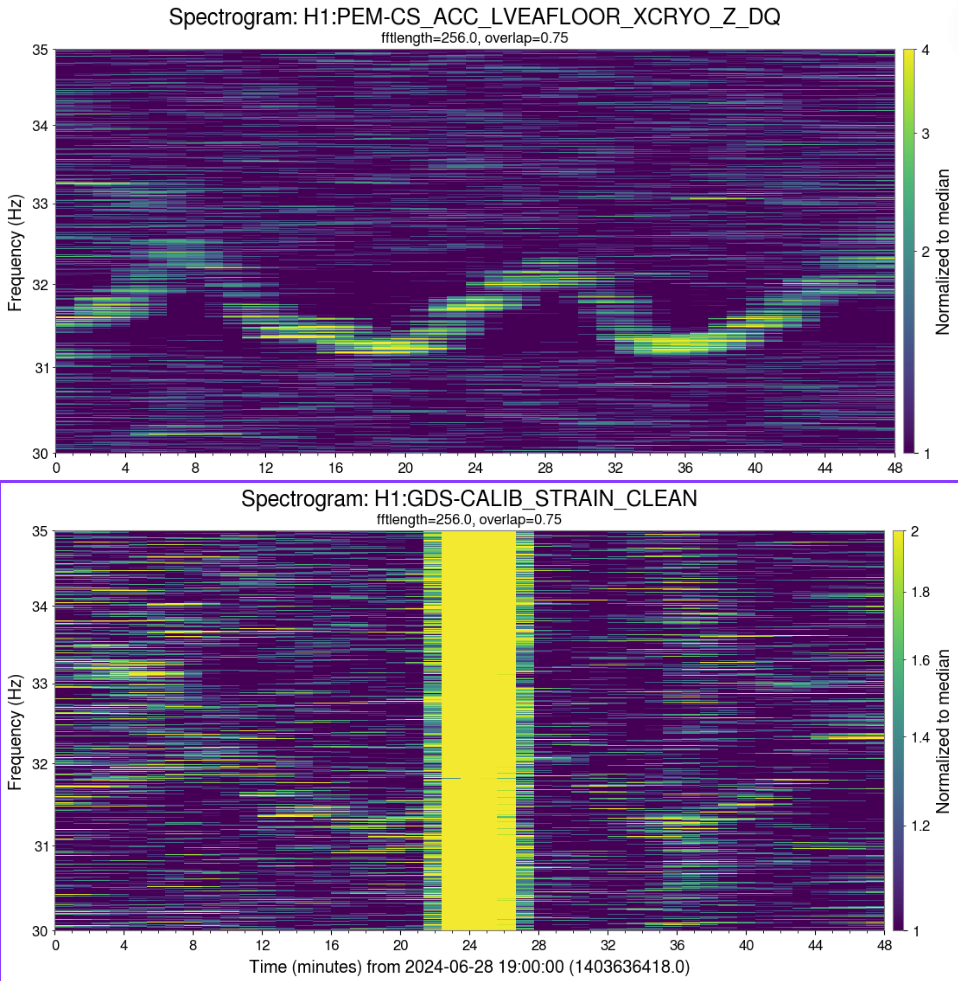
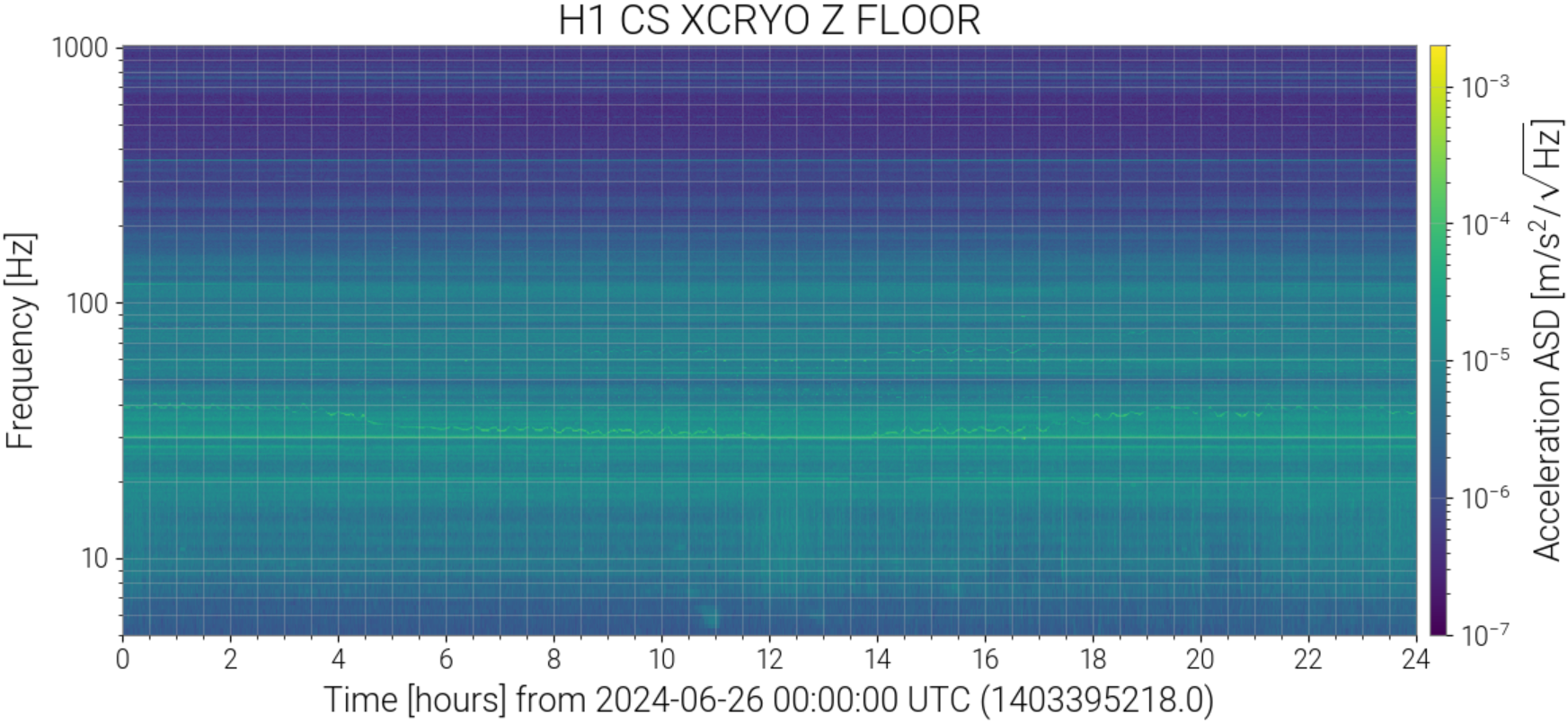
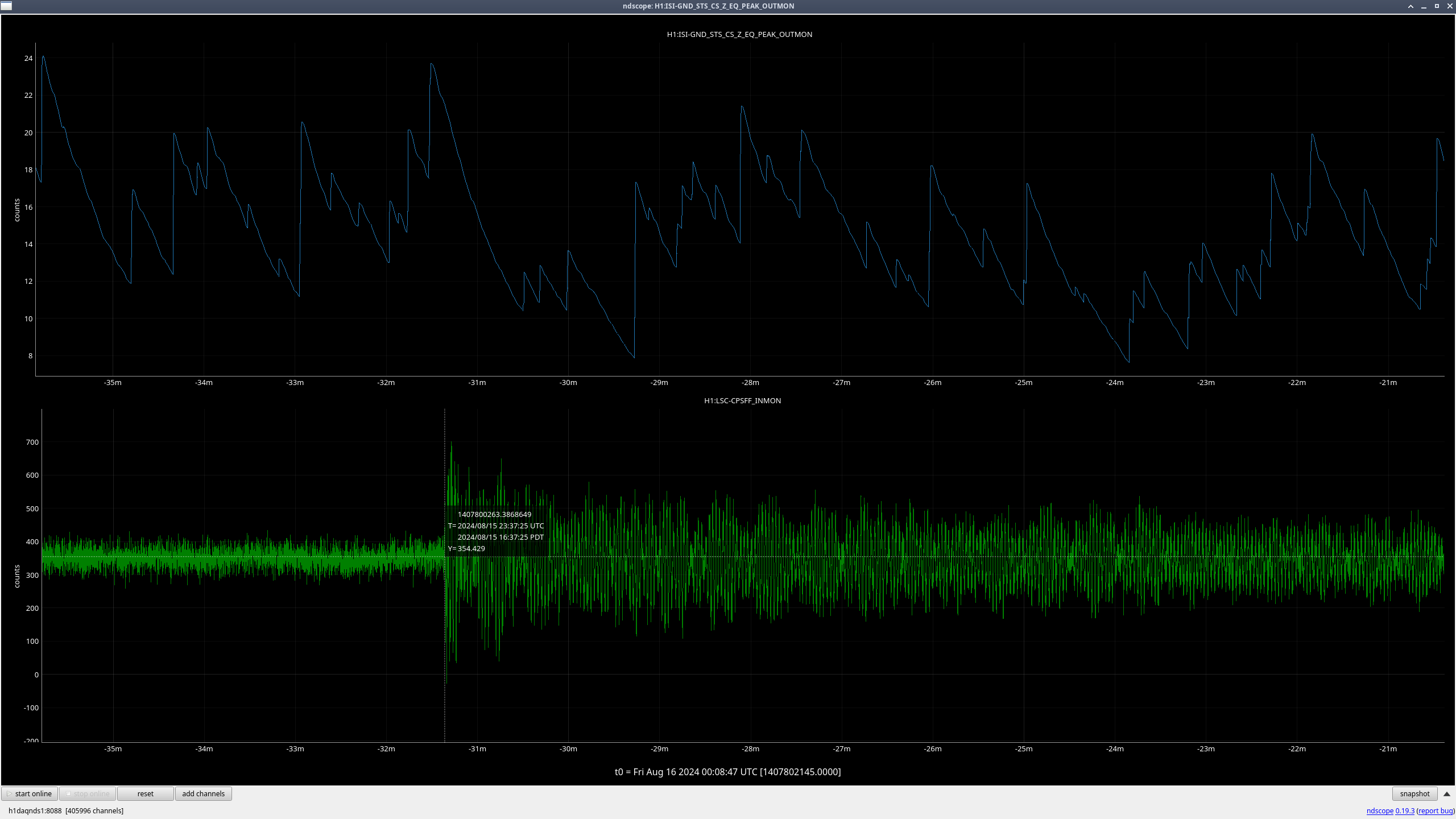
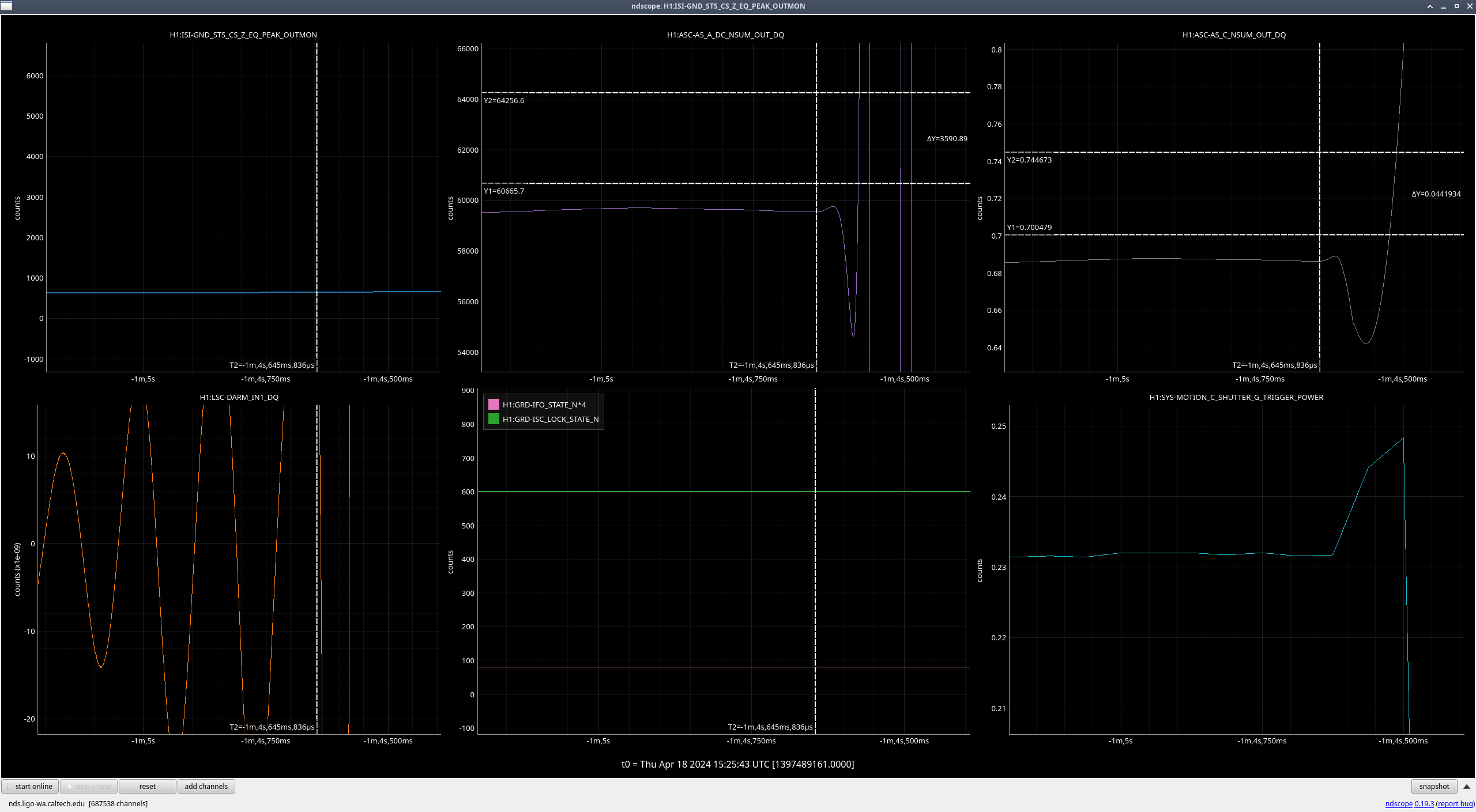
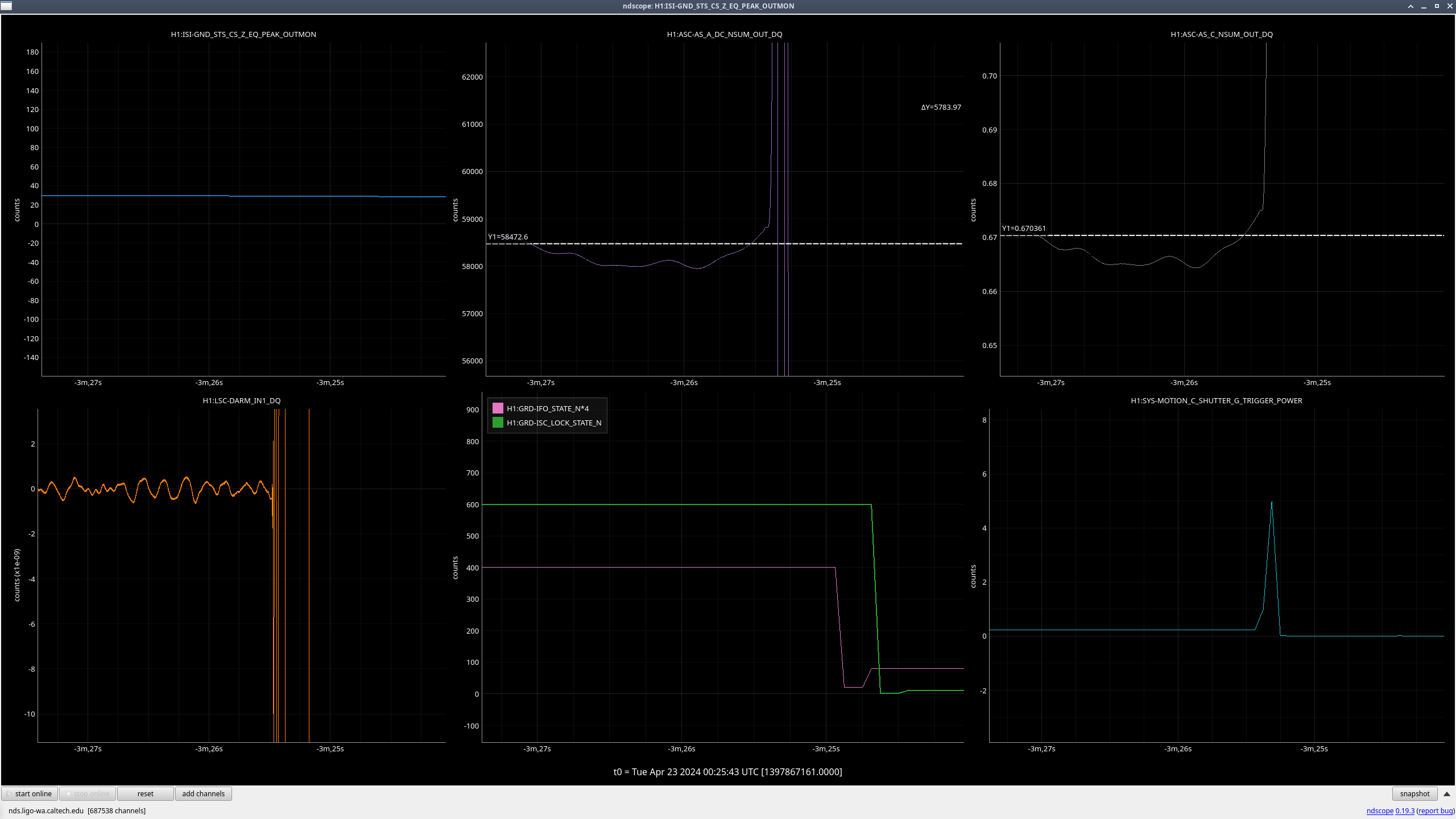
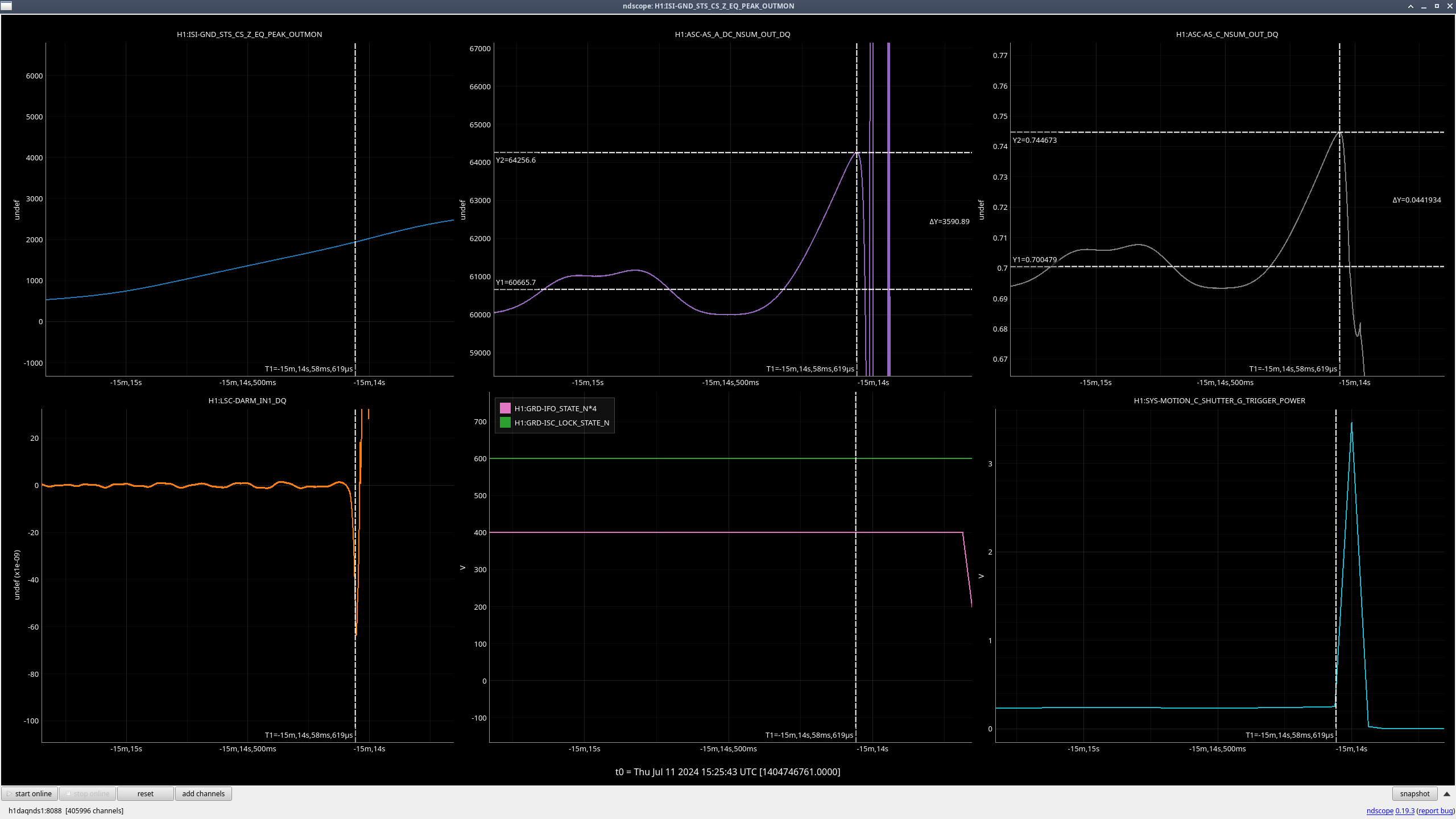
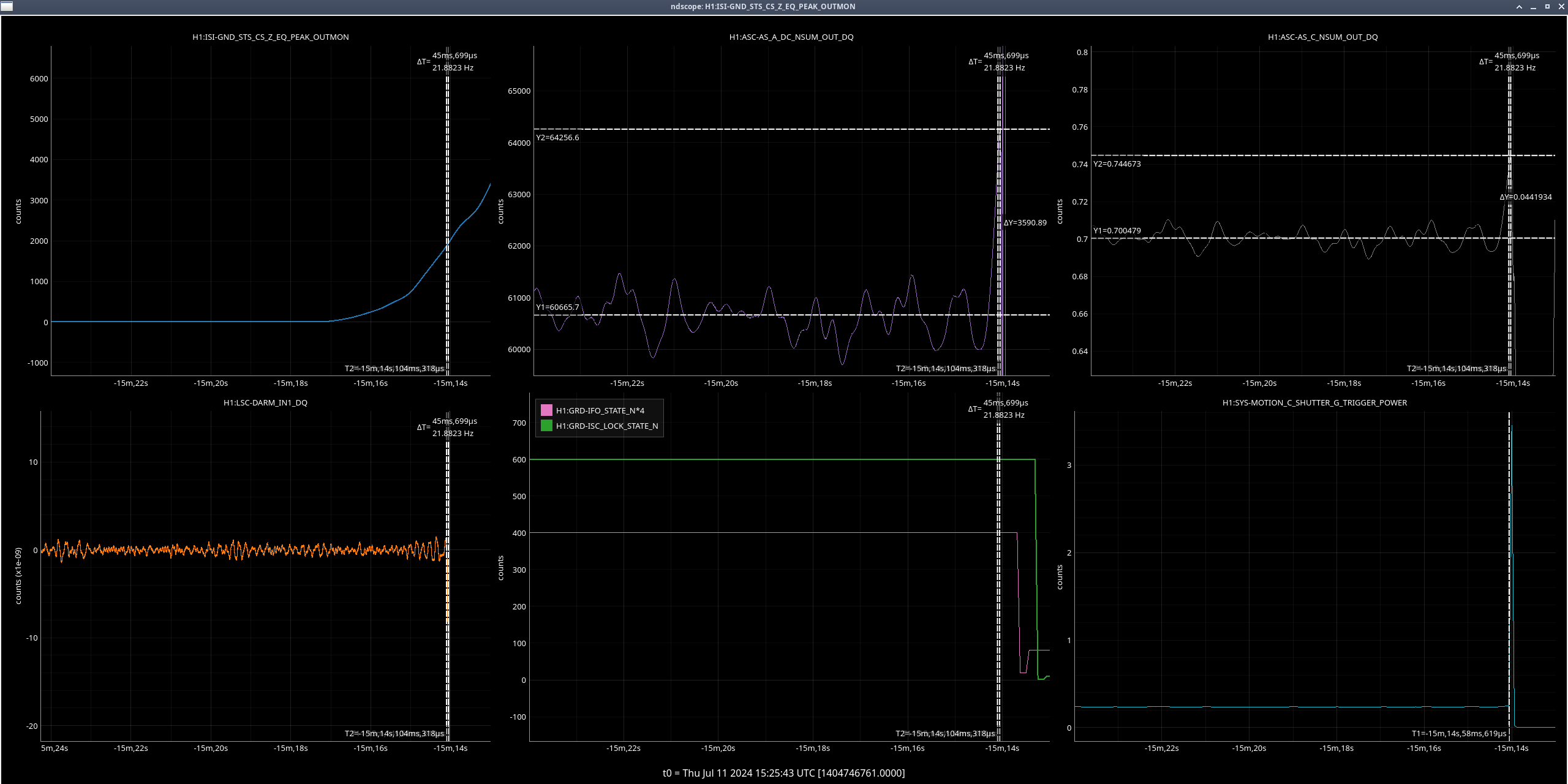
Right as this happened, LSC-CPSFF got much noisier, but there was not any motion seen by peakmon or HAM2 GND-STS in Z direction(ndscope). After everything was back up, it was still noisy. Probably nothing weird but still wanted to mention it.
Also, I put the IMC in OFFLINE for the night since it decided to now have trouble locking and was showing a bunch fringes. Tagging Ops aka tomorrow morning's me
FRS31855 Opened for this issue
LOGS:
2024-08-15T16:37:24-07:00 h1omc0.cds.ligo-wa.caltech.edu kernel: [11098181.717510] rts_cpu_isolator: LIGO code is done, calling regular shutdown code
2024-08-15T16:37:24-07:00 h1omc0.cds.ligo-wa.caltech.edu kernel: [11098181.718821] h1iopomc0: ERROR - A channel hop error has been detected, waiting for an exit signal.
2024-08-15T16:37:25-07:00 h1omc0.cds.ligo-wa.caltech.edu kernel: [11098181.817798] h1omcpi: ERROR - An ADC timeout error has been detected, waiting for an exit signal.
2024-08-15T16:37:25-07:00 h1omc0.cds.ligo-wa.caltech.edu kernel: [11098181.817971] h1omc: ERROR - An ADC timeout error has been detected, waiting for an exit signal.
2024-08-15T16:37:25-07:00 h1omc0.cds.ligo-wa.caltech.edu rts_awgtpman_exec[28137]: aIOP cycle timeout
Reboot/Restart Log:
Thu15Aug2024
LOC TIME HOSTNAME MODEL/REBOOT
16:49:17 h1omc0 ***REBOOT***
16:50:45 h1omc0 h1iopomc0
16:50:58 h1omc0 h1omc
16:51:11 h1omc0 h1omcpi
16:53:56 h1sush2a h1iopsush2a
16:53:59 h1susb123 h1iopsusb123
16:54:03 h1sush34 h1iopsush34
16:54:10 h1sush2a h1susmc1
16:54:13 h1susb123 h1susitmy
16:54:13 h1sush56 h1iopsush56
16:54:17 h1sush34 h1susmc2
16:54:24 h1sush2a h1susmc3
16:54:27 h1susb123 h1susbs
16:54:27 h1sush56 h1sussrm
16:54:31 h1sush34 h1suspr2
16:54:38 h1sush2a h1susprm
16:54:41 h1susb123 h1susitmx
16:54:41 h1sush56 h1sussr3
16:54:45 h1sush34 h1sussr2
16:54:52 h1sush2a h1suspr3
16:54:55 h1susb123 h1susitmpi
16:54:55 h1sush56 h1susifoout
16:55:09 h1sush56 h1sussqzout
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}