Jim, Cyrus, Dave
Rolf added a new feature to RCG2.8 to permit a front end to run without an IRIGB card (GPS time is obtained via EPICS Channel Access from a remote IOC). We are in the process of testing this on h1pemmx.
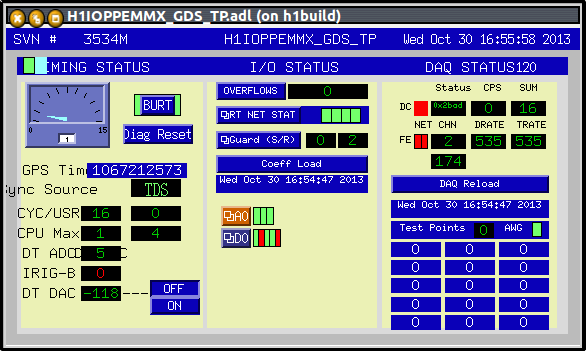
To prepare for the test, I added the line "remoteGPS=1" to the CDS block on h1ioppemmx. I added a cdsEzCaRead part, reading the GPS time from the DAQ data concentrator on channel H1:DAQ-DC0_GPS. I svn updated the trunk area, and compiled h1ioppemmx and h1pemmx against the latest trunk.
Test 1: keep the IRIG-B card in the computer, restart the IOP model several times. We noticed that the sync of the GPS time from IOPPEMMX and its reference DC0 does change from restart to restart but keeps synchronized to within a second.
We are in the process of test 2, removing the IRIGB card from h1pemmx. At the same time, Cyrus is reconfiguring the X-ARM switching sysems for the FrontEnd and DAQ switches, which will permit replacement of two netgear switches at MX with media converters. The use of full switches to support a single front end computer is obviously wasteful.
On completion of today's IRIGB tests, we will re-install the IRIGB card and reload the 2.7.2 version of the IOP and PEM code. While this test is progressing the DAQ status from MX is 0x2000 and its data is bad.