We looked into the PLL servo. First we checked the temperature feedback signals to the laser. They did seem ok, although the green had a 1mV offset (although not being written to it). We disconnected the green temp feedback.
The IR laser crystal temperature feedback was ok, but only after we managed to reset it to zero. Even the EPICS display was not showing all the digits (we got an intergrator gain of 1e-6). The EPICS screen displays voltage, which is good to know.
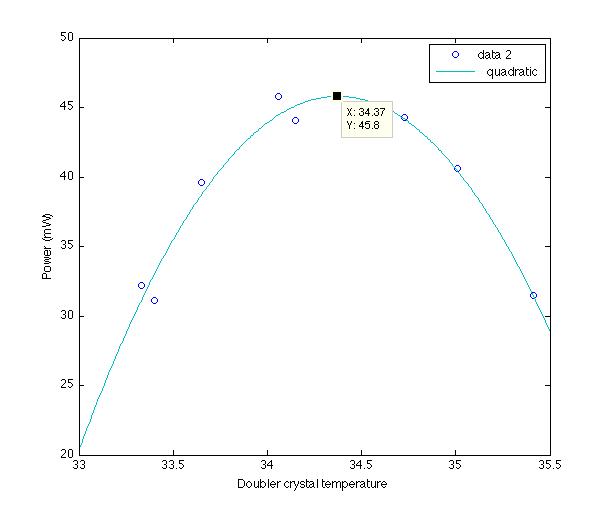
We had to adjust the temprature on the laser to find the beatnote, it was set back to 42.1 deg C. The knob on the front panel is very 'coarse', so the beatnote was within 10 MHz from the nominal 39.7 MHz. We engaged the temperature servo and we saw the beatnote move towards the 39.7 MHz. The Phase-Frequency Discriminator has a flat gain when the beatnote is far away from the LO frequency (39.7 MHz). Although not a problem, with low gain you do wait for it:) You can speed it up by engaging the CMB-A servo, which feedback to the PZT. Matter of fact, the temp signal is a plain copy of the PZT signal, which goes through the Beckhoff system and has it sown little servo.
We looked on an oscilloscope at the temperature feedback signal. There are a few ripples in the signal at ~1 micro second, ~5 microseconds and ~2 milli seconds. I think we should add an analog 10 Hz low pass filter at the output to remove these. The temperature feedback has a bandwidth of up ~0.5 Hz anyway.
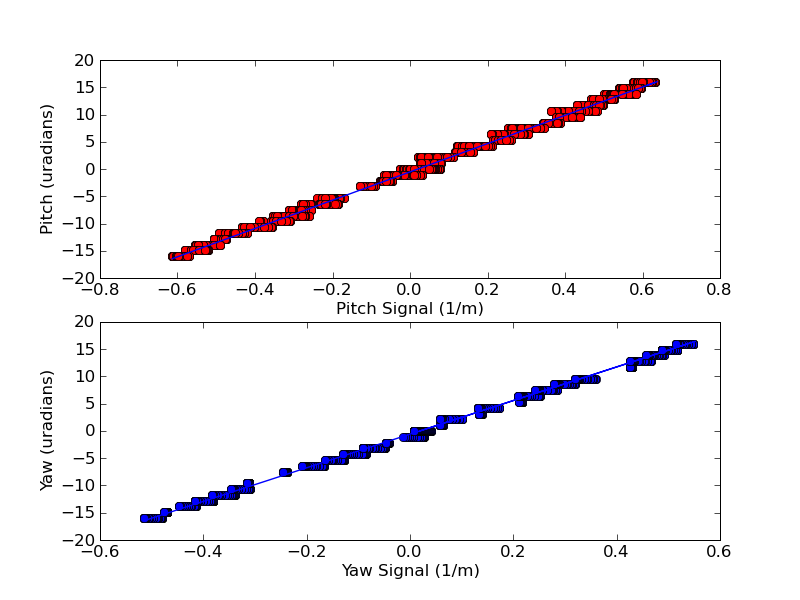
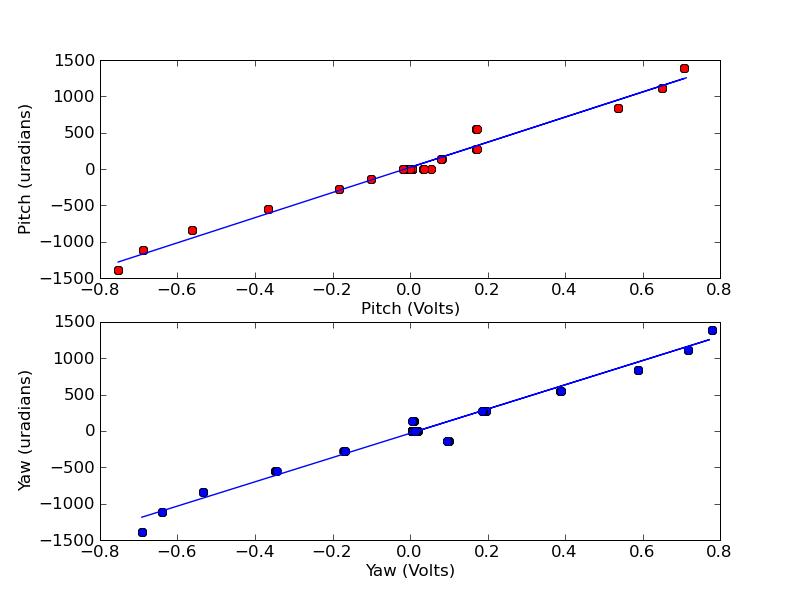
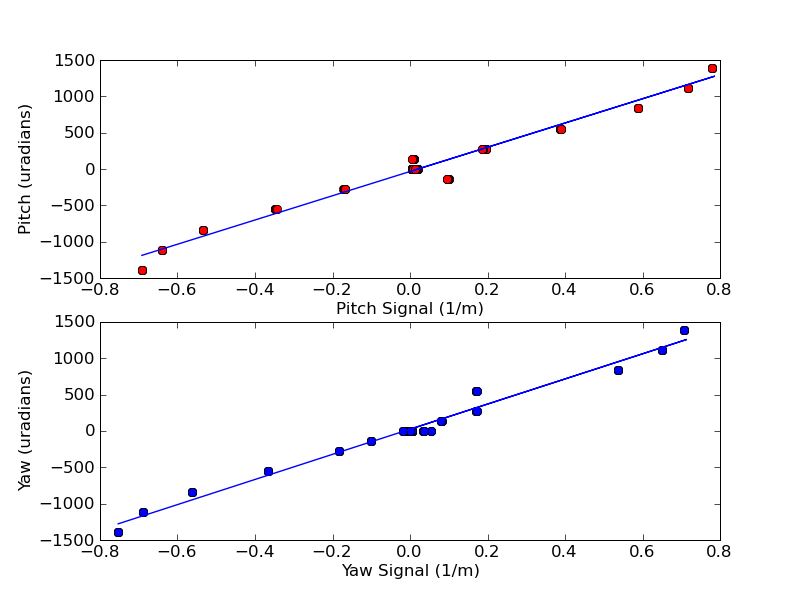
Looking at the PZT feedback signal. It has ~1.5Vpp 'oscillations' with a ~10s period appearing and then fading away. This is of course the 'equivalent' noise the laser tries to follow. The PZT frequency to volts conversion is ~3 MHz/V, so that indicates that the laser frequency fluctuates by ~4.5 MHz!
Looking a the I-mon from the Phase-Freq Discriminator it is flat when locked (and around the 39.7 MHz). When further away the signal looks like 'pulse-widht-modulated' with an average voltage which correspond to how far away the beatnote is and is expected. I don't know how far the beatnote needs to drift, at which point the frequency discriminator takes over from the phase discriminator. All-in-all the I-mon doesn't seem to be bad or noisy.