jeffrey.kissel@LIGO.ORG - posted 14:21, Tuesday 23 June 2026 (90716)
2026-06-22 SPI Pathfinder -- Installation Complete!
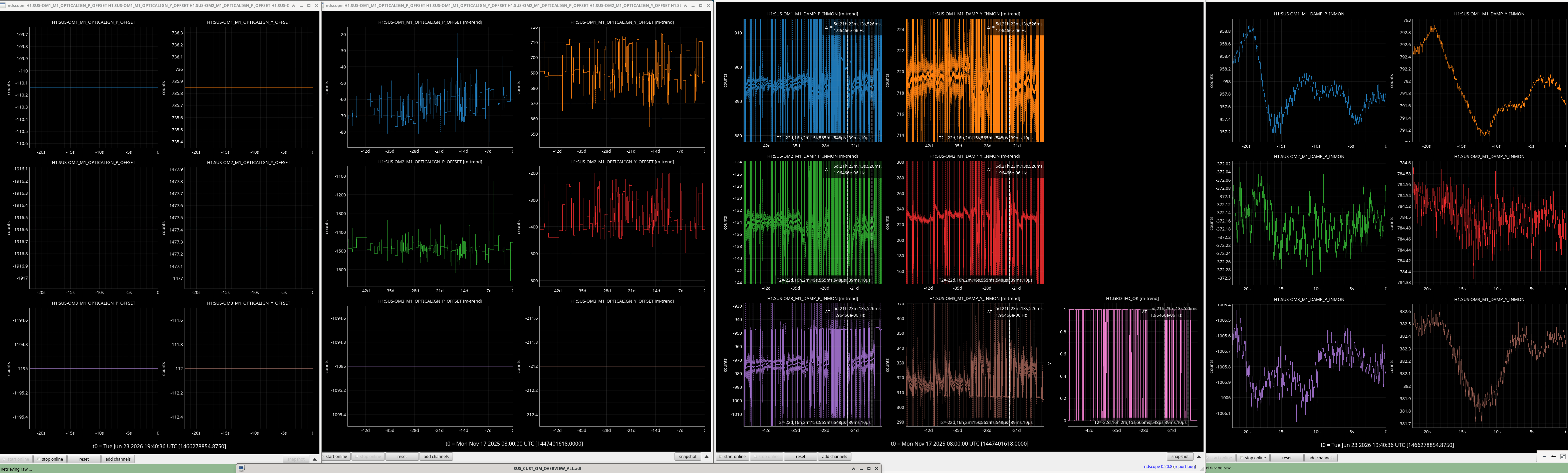
J. Kissel, J. Wright, T. Shaffer, J. Warner, J. Freed (belated aLOG covering 2026-06-22 activity) After enjoying a lovely long, Juneteeth Holiday weekend, TJ and I wrapped up the few loose ends that were left after the 2026-06-18 super push to get everything installed (see last update; LHO:90676). - As a fall out of LHO:90667, Jim, Arnaud and I discussed the pros and cons of using the current, D1000907-v7, balance mass "Payload & Suspended Mass Assembly" arrangement in regards to the W9 corner. We concluded that leaving the D1000907-v4 configuration for this corner in place -- i.e. having 11.6 [kg] of mass in small, modular, optional components -- was better that having one "giant" 10 [kg] mass in "the same" location (on the table top, but in the same W9 corner). As such, we left the plates as re-installed on LHO:90713, with the acknowledgement that the final configuration to create a balanced ISI may be different even further than D1000907-v7. - Using a beam profiler, we measured the Beam Profile of the beam returning from M_C1 on the HAM23 ISIJ Reflector. This is to, at least roughly, confirm the radii of curvature of the M_C1 mirror. We expected a 2 [mm] diameter beam, and we got a 2 [mm] beam diameter. A more thorough aLOG to come. - We did NOT address the stray beam that Jennie mentions in her summary -- yet. I'll also write a separate aLOG on this, but in short -- it's a ~0.2 [mW] beam that's what ~18% reflection there is off of a silicon diode, and it hits the -X/-Z rim of the chamber of the +Y door, and the (splotchy) spot size is ~4-5 [mm] in diameter. The SPI team has been aware of this beam since testing in the optics lab (see mention of it, e.g. in LHO:90455), but hoped that it would land on some part of the SPI Shroud assembly, but it *just* misses it. With this last item, we consider the Installation and Integrated Test Plan COMPLETE (T2500024) ... to as good as possible with the HAM3 ISI still locked. And that ... qualifier is a "just in case" qualifier, as it's a "we'll see what happens" when the ISI gets unlocked, and we've got an excellent amount of remote adjustability to be able to recover the MEAS IFO's alignment if HAM3 moves a lot between - "locked," - "re-balanced and damped" and - "isolated with feedback and DC positioning engaged." Essentially, we've launched the SPI pathfinder into space, and now its up to out built-in remote controlled actuators and sensors to take us home to achieve our scientific goals (see T2600019). Super congrats to all, and similarly large thank you. We did a thing!
Images attached to this report



























































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}