jennifer.wright@LIGO.ORG - posted 12:33, Friday 27 February 2026 (89305)
IMC WFS MASTER updated
Jennie W
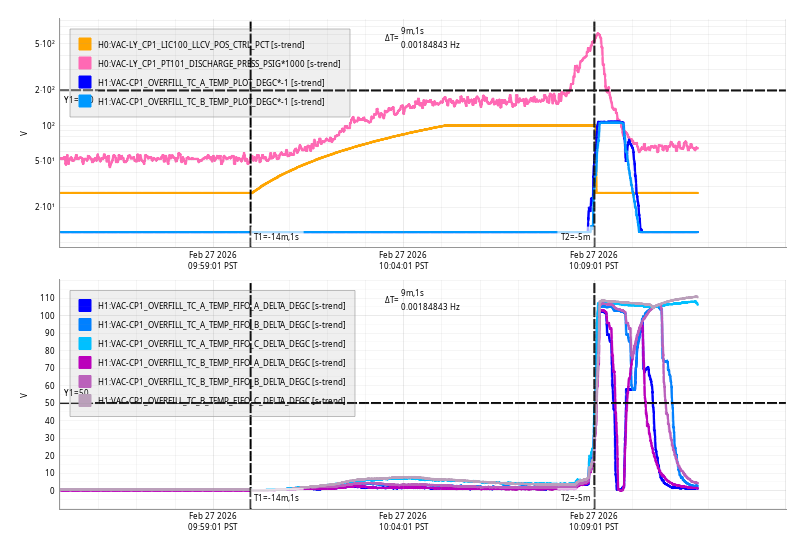
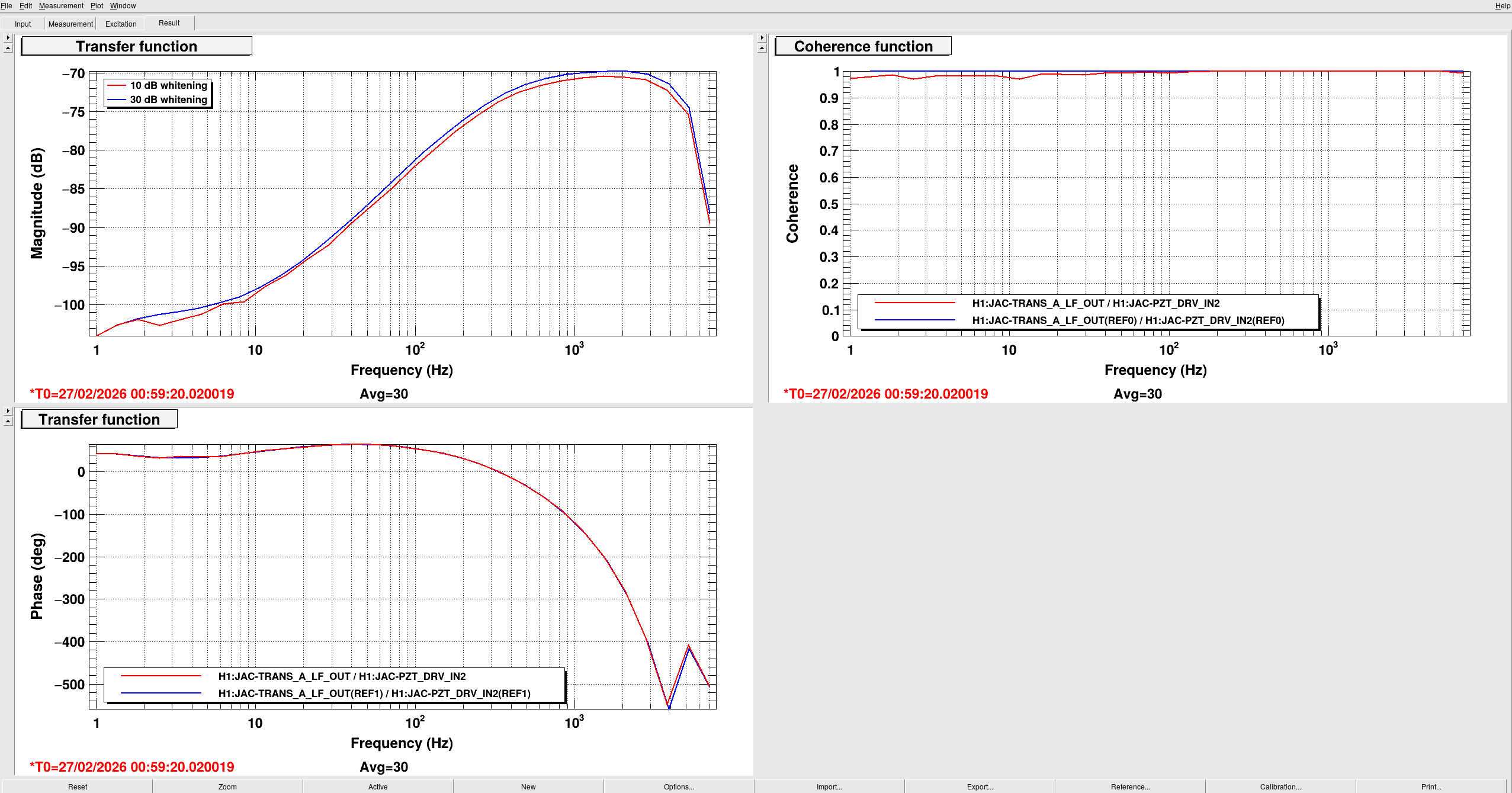
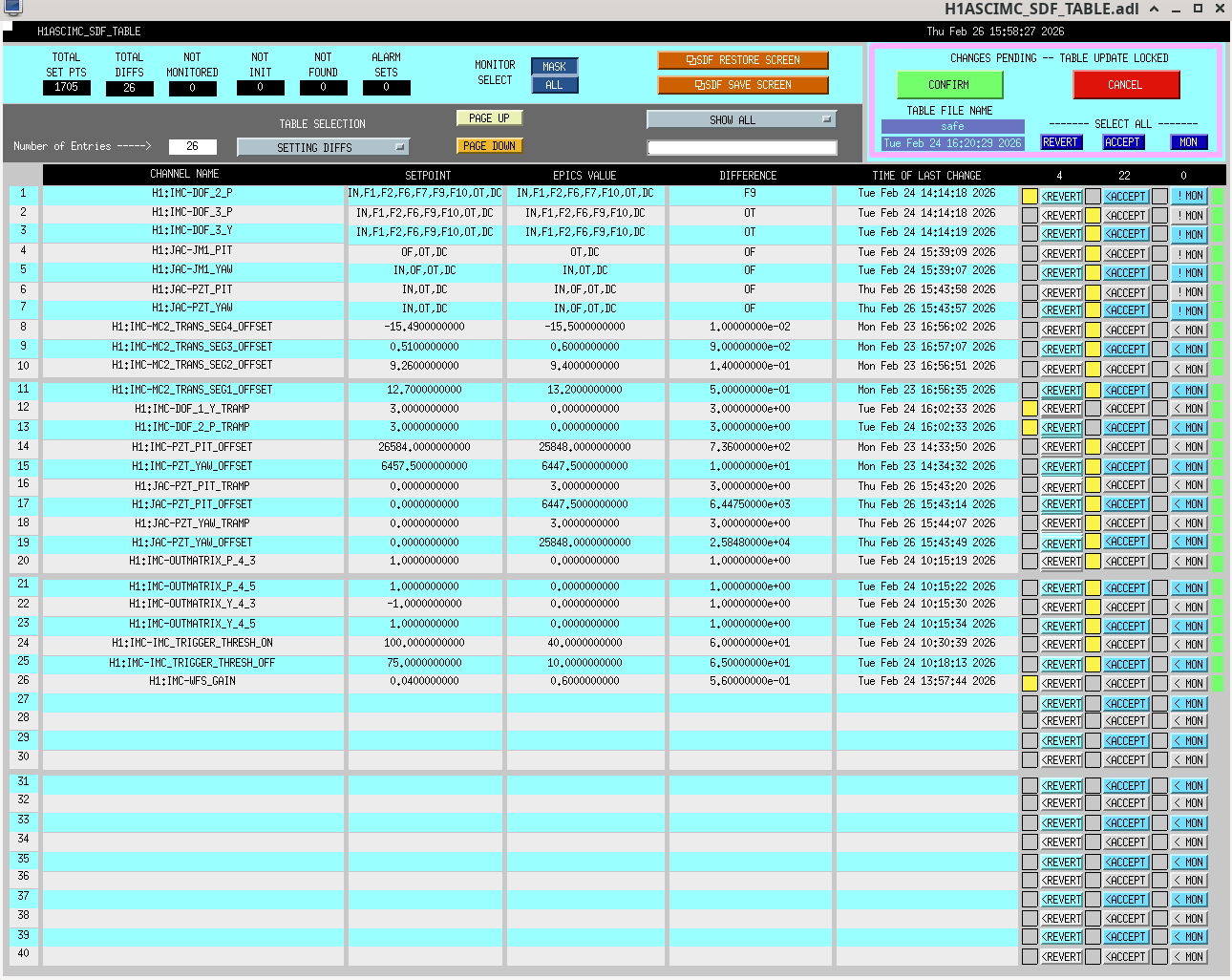
I updated the medm for the IMC WFS to remove the feedback references to the PSL PZT. This feedback path had been removed from the model this morning (thanks Dave for the rev-locked build of h1ascimc and the DAQ restart). The WFS screen output matrices have been updated to put back the fifth DOF and removed the path to the PZT. We never control this fifth degree of freedom but it is still in the simulin model so we should leave it in. The second picture shows the output matrix screens which no longer contain the PZT feedback column.
Images attached to this report













































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}